Code Review 1: The Cleanup
source
As much as we would like a program to follow the design, there is always an element of ad libbing when filling out the details. We create auxiliary classes and functions, add methods and data members to existing classes. This process reminds me of the growth of a yeast culture. As each cell keeps growing, it starts to bloat and bud. Eventually new buds separate and start a life of their own.
In software, the growing and (especially) the bloating happens quite naturally. Itĺs the budding and the separation that requires conscious effort on the part of the programmer. Code reviews help this process greatly. Weĺll see examples of overgrown files, methods and classes throughout our code reviews. Our response will be to create new files, new methods and, especially, new classes.
Weĺll be always on the lookout for potential code reuse.
When reviewing code, we will also figure out which parts require more thorough explanation and add appropriate comments.
Improving Code Grouping
The obvious place to start the code review is the file parse.cpp. It contains the main procedure. And thatĺs the first jarring feature. Main does not belong in the implementation file of the Parser class. I put it there because its purpose was mainly to test the Parser. Now itĺs time to separate it away from the Parser and create a new file main.cpp.
Look also at the file symtab.h. I definitely see some potential for code reuse there. Such classes as Link and List are very general and can be used in many applications. This particular list stores direct values rather than pointers to objects. So letĺs create a separate header file for it and call it vlist.h. The implementation will go to another file vlist.cpp.
Notice that we havenĺt tried to make any changes to the classes Link and List to make them more general. This is a useful rule of thumb:
| Donĺt try to generalize until there's a need for it. |
Over-generalization is the bane of code reuse.
Finally, I split the files symtab.h and symtab.cpp into three groups of files corresponding to the symbol table, the function table and the hash table.
Table: The correspondence between files and classes, functions and global objects.
| main.cpp | main () |
| parser.h parser.cpp | Parser |
| scan.h scan.cpp | EToken, Scanner |
| funtab.h funtab.cpp | FunctionEntry, funArr, FunctionTable |
| symtab.h symtab.cpp | SymbolTable |
| vlist.h vlist.cpp | Link, List |
| htab.h htab.cpp | HTable |
| store.h store.cpp | Store |
| tree.h tree.cpp | Node and its children |
Decoupling the Output
Letĺs look again at the main loop of our calculator.
cout << "> "; // prompt cin.getline (buf, maxBuf); Scanner scanner (buf); Parser parser (scanner, store, funTab, symTab); status = parser.Eval (); |
The first two lines take care of user input. The next three lines do the parsing and evaluation. Arenĺt we missing something? Shouldnĺt the calculator display the result? Well, it does, inside Eval. Sending the result of the calculation to the output is a side effect of evaluation.
What it means, however, is that somebody will have to look inside the implementation of Eval in order to understand what the calculator is doing. Okay, that sounds bad--but isn't it true in general that you'd have to look inside the implementation of Eval in order to know what it's doing? Otherwise, how would you know that it first parses and then evaluates the user input, which has been passed to the parser in the form of a scanner.
Well, that's a good point! Indeed, why donĺt we make it more explicit and rewrite the last line of the main loop.
cout << "> "; // prompt cin.getline (buf, maxBuf); Scanner scanner (buf); Parser parser (scanner, store, funTab, symTab); status = parser.Parse (); double result = parser.Calculate (); cout << result << endl; |
This way, every statement does just one well defined thing. I can read this code without having to know any of the implementation details of any of the objects. Hereĺs how I read it:
- Prompt the user,
- Get a line of input,
- Create a scanner to encapsulate the line of input,
- Create a parser to process this input,
- Let the parser parse it,
- Let the parser calculate the result,
- Display the result.
I find this solution esthetically more pleasing, but esthetics alone isn't usually enough to convince somebody to rewrite their code. I had to learn to translate my esthetics into practical arguments. Therefore I will argue that this version is better than the original one because:
- It separates three distinct and well defined actions: parsing, calculation and display. This decoupling will translate into easier maintenance.
- Input and output are now performed at the same level, rather than input being done at the top level and output interspersed with the lower level code.
- Input and output are part of user interface which usually evolves independently of the rest of the program. So it's always a good idea to have it concentrated in one place. Iĺm already anticipating the possible switch from command line interface to a simple Windows interface.
The changes to Parser to support this new split are pretty obvious. I got rid of the old Parse method and pasted its code directly in the only place from which it was called (all it did was: _pTree = Expr(). Then I renamed the Eval to Parse and moved the calculation to the new method Calculate. By the way, I also fixed a loophole in error checking: the input line should not contain anything following the expression. Before that, a line like 1 + 1 = 1 would have been accepted without complaint.
Status Parser::Parse ()
{
// Everything is an expression
_pTree = Expr ();
if (!_scanner.IsDone ())
_status = stError;
return _status;
}
double Parser::Calculate () const
{
assert (_status == stOk);
assert (_pTree != 0);
return _pTree->Calc ();
}
bool Scanner::IsDone () const
{
return _buf [_iLook] == '\0';
}
|
My students convinced me that Calculate should not be called, if the parsing resulted in an error. As you can see, that certainly simplifies the code of Parse and Calculate. Of course, now we have to check for errors in main, but thatĺs okay; since we have the status codes available there, why not do something useful with them.
By the way, as long as weĺre at it, we can also check the scanner for an empty line and not bother creating a parser in such a case. Incidentally, that will allow us to use an empty line as a sign from the user to quit the calculator. Things are just nicely falling in place.
cout << "\nEnter empty line to quit\n";
// Process a line of input at a time
do
{
cout << "> "; // prompt
cin.getline (buf, maxBuf); // read a line
Scanner scanner (buf); // create a scanner
if (!scanner.IsEmpty ())
{
// Create a parser
Parser parser (scanner, store, funTab, symTab);
status = parser.Parse ();
if (status == stOk)
{
double result = parser.Calculate ();
cout << result << endl;
}
else
{
cout << "Syntax error.\n";
}
}
else
{
break;
}
} while (status != stQuit);
|
Notice what we have just done: We have reorganized the top level of our program with very little effort. In traditional programming this is a big no-no. Changing the top level is synonymous with rewriting the whole program. We must have done something right, if we were able to pull such a trick. Of course, this is a small program and, besides, I wrote it, so it was easy for me to change it. I have some good news: I have tried these methods in a project a hundred times bigger than this and it worked. Better than that--I would let a newcomer to the project go ahead and make a top level change and propagate it all the way to the lowest level. And frankly, if I werenĺt able to do just that, I would have been stuck forever with some early design mistakes. Just like the one in the calculator which we have just fixed.
There are several other output operations throughout the program. They are mostly dealing with error reporting. Since we donĺt have yet a coherent plan for error reporting and error propagation, weĺll just do one cosmetic change. Instead of directing error messages to the standard output cout, weĺll direct them to the standard error cerr, like this:
cerr << "Error: division by zero\n"; |
The only practical difference is that, if you redirect standard output of your program to a file, the error messages will still go to your console. Not that we care much, but when we port this program to Windows, we would like to be able to quickly search the source for stderr and, for instance, convert these printouts to message boxes.
Fighting Defensive Programming
"Defensive programming" sounds good, doesnĺt it? A program written by a defensive programmer should be safer and more robust, right?
Wrong! Defensive programming is a dangerous form of engineering malpractice (in a show of self-abasement Iĺll shortly expose examples of such practices in my own code). Defensive programming promotes writing code that is supposed to work even in the face of programmersĺ errors, a.k.a. bugs. In practice, it gives the bugs the opportunity to cover their tracks. Anybody who spent a sleepless night chasing a bug that could have been caught early on, if it werenĺt for defensive programming, will understand my indignation. In most cases defensive programming is a result of not understanding the exact contract between various parts of the program. A confused or lazy programmer, instead of trying to understand the logic of the program, might write something that should work no matter what. That code will obscure the program's logic even more, making further development even sloppier. The programmer will eventually lose control of the code.
One source of confusion that is often covered up by defensive programming is the discrepancy between the length of a string and the size of the array into which it will fit. The array must have room for the terminating null which is not counted in the length of the string. Does the MAX_PATH defined in a system header take into account the terminating null? Should one use MAX_PATH or MAX_PATH + 1 when allocating a buffer?
Now look at the confusion in our calculator. Scanner::GetSymbolName assumes that its argument len is the maximum size of a string that can fit in the buffer. So the buffer size is one larger than len. Hence the assertions:
assert (len >= maxSymLen); assert (_lenSymbol <= maxSymLen); |
But when we are calling GetSymbolName from the parser, we are allocating a buffer of maxSymLen characters and pass maxSymLen as its length. Wait a moment, that looks like a bug, doesnĺt it? We have just said that GetSymbolName expects the buffer to be one char longer than len. So how does it work? Because, in the scanner, we have defensively truncated the length of a symbolic name to one less than maxSymLen.
if (_lenSymbol >= maxSymLen)
_lenSymbol = maxSymLen - 1;
|
So now it turns out that maxSymLen includes the terminating null and Scanner::GetSymbolName expects len to be the size of the buffer, not the string; although when it returns, it sets len to the actual size of the string--without the null. Hey, it works! Look how clever I am! Not!
Letĺs just try to rationalize our assumptions. First of all, maxSymLen should be the maximum length of a symbolic name without the terminating null. Null termination is an implementation detail--we should be able to switch to counted strings without having to change the value of maxSymLen. Scanner::Accept should therefore truncate symbolic names like this:
if (_lenSymbol > maxSymLen)
_lenSymbol = maxSymLen;
|
This is how GetSymbolName should be called
char strSymbol [maxSymLen + 1]; int lenSym = _scanner.GetSymbolName (strSymbol, maxSymLen + 1); |
int Scanner::GetSymbolName (char * strOut, int lenBuf)
{
assert (lenBuf > maxSymLen);
assert (_lenSymbol < lenBuf);
strncpy (strOut, &_buf[_iSymbol], _lenSymbol);
strOut [_lenSymbol] = 0;
return _lenSymbol;
}
|
The in-argument, lenBuf, is the length of the buffer. The return value is the length of the string copied into the buffer. Thatĺs much less confusing.
Another excuse for all kinds of lame coding practices is any situation that is not really supposed to happen. Our calculator has some built in limitations. For instance, the size of the Store is limited to maxSymbols, which is set to 40. Thatĺs plenty, and we donĺt expect to hit this limitation under normal circumstances. Even if we did, we have a line of defense in Store:
void Store::SetValue (int id, double val)
{
if (id < _size)
{
_cell [id] = val;
_status [id] = stInit;
}
}
|
Thatĺs very fortunate, because it let us get away with some sloppy error checking in the parser (weĺll look at it shortly).
You see what happens when you lower your defenses against defensive programming? You get sloppy and sooner or later it will bite you. So letĺs turn this method into an example of offensive programming: we are so sure of the correctness of our (or othersĺ) code that weĺre not afraid to assert it.
void Store::SetValue (int id, double val)
{
assert (id < _size);
_cell [id] = val;
_status [id] = stInit;
}
|
Weĺll fix the callerĺs code shortly.
A Case of Paranoid Programming
The initialization of the function table is an example of paranoid defensive programming. First we define maxIdFun to be the size of the array of function entries. Then we define the array of size maxIdFun, but we initialize it with a smaller number of entries. We also add a sentinel with a null pointer and an empty string. Then, in the constructor of FunctionTable, we set up the loop to go from zero to maxIdFun - 1, but we break from it when we encounter the sentinel. All this mess is there to prevent the mismatch between the size of the function array and the number of entries in the function table.
Instead, one simple assertion would suffice:
assert (maxIdFun == sizeof FunctionArray / sizeof FunctionArray [0]);
|
The sizeof operator returns the size (in bytes) of its argument. When applied to a static array, it returns the size of the whole array. When applied to a pointer, even if this pointer points to an array, it returns the size of the pointer--4 bytes on a 32-bit computer. (The argument to sizeof may also be a type name, it will return the size of an object of that type.)
Notice that I had to correct an awkward naming conflict for this assertion to work. I had named the argument to FunctionTable constructor the same name as the global array--they were both called funArr. Guess what, when I first wrote the assertion, it didnĺt work as planned: sizeof funArr kept returning 4. I checked the language reference several times, tried using brackets--nothing worked. I was ready to blame the compiler when suddenly I realized that my sizeof was applied to the argument passed to the constructor and not to the global array, as I thought. The local name funArr obscured the global name funArr and, consequently, I was sizing a pointer rather than a static array.
I learned (or rather re-learned for the nth time) two lessons: donĺt use the same name for different variables and, if operator sizeof returns 4 when applied to an array, donĺt blame the compiler. The irony of this situation was that I usually, but not this time, follow the convention of starting a global name with a capital letter (and also making it less abbreviated).
After changing the name of the global array to FunctionArray, I set maxIdFun correctly to 14 and let the compiler size the array by counting the initializers (thatĺs why I left the brackets empty).
const int maxIdFun = 14;
FunctionEntry FunctionArray [] =
{
log, "log",
ů
atan, "atan",
};
|
Now I could finally add the assertion that would catch the mismatch between the size of FunctionArray and the array FunctionTable::_pFun was pointing to.
FunctionTable::FunctionTable (SymbolTable & symTab, FunctionEntry * funArr)
: _size(0)
{
assert (maxIdFun == sizeof FunctionArray / sizeof FunctionArray [0]);
ů
}
|
When I showed this solution to students, they immediately noticed the problem: What if the constructor of FunctionTable is called with a pointer to an array different than FunctionArray? Thereĺs no way to prevent it. Obviously the design was evolving away from the generality of FunctionTable as an object that can be initialized by any array of function entries and towards making FunctionArray a very close partner of FunctionTable. In fact, thatĺs what I was planning to do in the next code review. Hereĺs the code I wrote for that purpose
static FunctionEntry FunctionArray [] = { ů }
FunctionTable::FunctionTable (SymbolTable & symTab)
: _size(0)
{
assert (maxIdFun == sizeof FunctionArray / sizeof FunctionArray [0]);
ů
}
|
I made FunctionArray static, which means that it was invisible outside of the file funtab.cpp where it was defined. In this sense static and extern are on the opposite ends of the spectrum of visibility. Data hiding is always a good idea.
Is it possible to make FunctionArray and FunctionTable even more intimately related? How about making FunctionArray a member of the class FunctionTable? Now, remember, the whole idea of FunctionArray was to be able to statically initialize it--compile-time instead of run-time. It turns out that there is a construct in C++ called--notice the overloading of this keyword--a static member.
|
A static member can be viewed as a member of the class object, rather than a member of the particular instance object. In some object-oriented languages, for example in Smalltalk, there is a clear distinction between the instance object and the class object. There can be many instances of objects of the same class, but they all share the same class object. A class object may have its own data members and methods. The values of class object data members are shared between all instances. One can access class data or call class methods without having access to any instance object. Class methods can only operate on class data, not on the data of a particular instance. Although in C++ there is no notion of class object, static data members and static methods effectively provide the equivalent functionality. There is only one instance of each static data member per class, no matter how many objects of a given class are created. A static method is essentially a regular function (in that it doesnĺt have the this pointer); with the visibility restricted by its membership in the class. |
This is the syntax for declaring a private static data member
class FunctionTable
{
ů
private:
static FunctionEntry _functionArray [];
ů
};
|
And this is how itĺs initialized in the implementation file:
FunctionEntry FunctionTable::_functionArray [] =
{
log, "log",
ů
};
|
Notice that, even though _functionArray is private, its initialization is done within global scope.
Unfortunately, when _functionArray is made a static member with undefined size (look at the empty brackets in the declaration), the sizeof operator does not return the initialized size of the array, as we would like it. The compiler looks only at the declaration in FunctionTable and it doesnĺt find the information about the size there. When you think about it, it actually makes sense.
There was another interesting suggestion. Why not use directly sizeof FunctionArray / sizeof FunctionArray [0] as the size of the array _pFun inside the declaration of FunctionTable?
Pfun _pFun [sizeof FunctionArray / sizeof FunctionArray [0]];
|
In principle itĺs possible, but in practice we would have to initialize FunctionArray before the declaration of FunctionTable, so that the compiler could calculate the sizeof. That would mean putting the initialization in the header file and, since the header had to be included in several implementation files, we would get a linker error (multiple definition).
The proposed solution was then modified to make FunctionTable a const array (or, strictly speaking, an array of constants) so that the linker wouldnĺt complain that it is initialized in multiple files. After all, constructs like this
const int maxLen = 10;
|
are perfectly acceptable in header files. So should
const FunctionEntry FunctionArray [] =
{
log, "log",
ů
};
|
And indeed, the linker didnĺt complain. This solution is good, because it makes the table of function pointers automatically adjust its size when the function array grows. Thatĺs better than hitting the assertion and having to adjust the size by hand. On the other hand, the array FunctionArray that is only needed internally to initialize the function table, suddenly becomes visible to the whole world. This is exactly the opposite of the other proposal, which made the array a private static member of the function table. It violates the principle of data hiding.
So what are we to do? Hereĺs my solution: Letĺs hide the function array in the implementation file funtab.cpp by making it static (but not a static data member). But instead of trying at all costs to size _pFun statically, letĺs use dynamic allocation. At the point of allocation, the static size of FunctionTable is well known to the compiler.
FunctionTable::FunctionTable (SymbolTable& symTab)
: _size (sizeof FunctionArray / sizeof FunctionArray [0])
{
_pFun = new PFun [_size];
for (int i = 0; i < _size; ++i)
{
int len = strlen (FunctionArray[i].strFun);
_pFun [i] = FunctionArray [i].pFun;
cout << FunctionArray[i].strFun << endl;
int j = symTab.ForceAdd (FunctionArray[i].strFun, len);
assert (i == j);
}
}
|
Letĺs not forget to deallocate the array
FunctionTable::~FunctionTable ()
{
delete []_pFun;
}
|
We have already seen examples of classes forming patterns (stack and its sequencer). Here we see an example of a static array teaming up with a class. In practice such patterns will share the same header and implementation file.
What have I sacrificed by choosing this solution? I have sacrificed static allocation of an array. The drawbacks of dynamic allocation are twofold: having to remember to deallocate the object--a maintainability drawback--and an infinitesimal increase in the cost of access, which I mention here only for the sake of completeness, because it is really irrelevant. In exchange, I can keep the function array and its initializer list hidden, which is an important maintainability gain.
The code of the FunctionTable is not immediately reusable, but I could easily make it so by changing the constructor to accept an array of function entries and the count of entries. Since I donĺt see a lot of potential for reuse, I wonĺt do it. This way I reduce the number of objects visible at the highest abstraction level--at the level of main.
Fringes
Dealing with boundary cases and error paths is the area where beginning programmers make most mistakes. Not checking for array bounds, not testing error returns, ignoring null pointers, etc., are the type of errors that usually donĺt manifest themselves during superficial testing. The program works, except for weird cases. Such an approach is not acceptable in writing professional software. Weird cases are as important as the main execution path--in fact they often contribute to the bulk of code (although we will learn to avoid such imbalances).
Iĺve found an example of sloppy error checking in the parser. It so happens that the method SymbolTable::ForceAdd may fail if there is no more space for symbolic variables. Yet we are not testing for it in the parser. The code works (sort of) due to the case of defensive programming in the symbol table. Now that we have just replaced the defensive code with the offensive one, we have to fix this fragment too:
// Factor := Ident
if (id == idNotFound)
{
// add new identifier to the symbol table
id = _symTab.ForceAdd (strSymbol, lenSym);
if (id == idNotFound)
{
cerr << "Error: Too many variables\n";
_status = stError;
pNode = 0;
}
}
if (id != idNotFound)
pNode = new VarNode (id, _store);
|
The rule of thumb is to check for the error as soon as possible. In this case we shouldnĺt have waited until VarNode was created and then silently break the contract of that class (VarNode::Calc was not doing the correct thing!).
Improving Communication Between Classes
So far, we've been passing strings between classes always accompanied by the count of characters. At some point it looked like a good idea, but lately it became more and more obvious that the count is superfluous. For instance, it is very easy to eliminate the count from the hash functions. Since we are scanning the string anyway, we can just as easily look for the terminating null,.
int HTable::hash (char const * str) const
{
// must be unsigned, hash should return positive number
unsigned h = str [0];
assert (h != 0); // no empty strings, please
for (int i = 1; str[i] != 0; ++i)
h = (h << 4) + str [i];
return h % _size; // small positive integer
}
|
In ForceAdd, where we use the length in several places, we can simply apply strlen to it.
int SymbolTable::ForceAdd (char const * str)
{
int len = strlen (str);
assert (len > 0);
ů
}
|
Next, letĺs have a closer look at the interactions between various classes inside the symbol table. The hash table is an array of lists. The search for a string in the hash table returns a short list of candidates. Symbol table code then iterates over this short list and tries to find the string using direct comparison. Hereĺs the code that does it:
int SymbolTable::Find (char const * str) const
{
// Get a short list from hash table
List const & list = _htab.Find (str);
// Iterate over this list
for (Link const * pLink = list.GetHead();
pLink != 0;
pLink = pLink->Next ())
{
int id = pLink->Id ();
int offStr = _offStr [id];
// char * strStored = &_strBuf [offStr];
char const * strStored = _strBuf + offStr;
if (strcmp (str, strStored) == 0) // they're equal
{
return id; // success!
}
}
return idNotFound;
}
|
Objects of class List play the role of communication packets between the hash table and the code of the symbol table. As a code reviewer I feel uneasy about it. Something is bothering me in this arrangement--does the HTable have to expose the details of its implementation, namely linked lists, to its client? After all there are implementations of hash tables that donĺt use linked lists. As a code reviewer I can express my uneasiness even if I donĺt know how to fix the situation. In this case, however, I do know what to do. The one common feature of all implementations of hash tables is that they have to be able to deal with collisions (unless they are perfect hash tables--but we wonĺt worry about those here). So they will always, at least conceptually, return an overflow list. All the client has to do is sequence through this list in order to finish the search.
The keyword here is sequence. A sequencer object is easyly implemented on top of a linked list. Itĺs just a repackaging of the code weĺve seen above. But a sequencer has a much bigger potential. We've already seen a stack sequencer; one can write a sequencer over an array, a sequencer that would skip entries, and so on. We could make the hash table return a sequencer rather than a list. That way we would isolate ourselves from one more implementation detail of the hash table. (If you're wondering why I'm calling it a sequencer and not an iterator--I reserve the name iterator for the pointer-like objects of the standard library--we'll get there in due time.)
Figure 1 shows the interaction of the clientĺs code (SymbolTable code) with the hash table using the sequencer object which encapsulates the results of the hash table search.
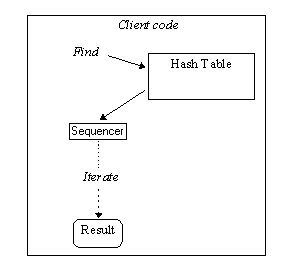
Figure: Using a sequencer for communications between the hash table and the client
The straightforward and simple-minded translation of Figure 3-1 into code would produce a method like this:
ListSeq * HashTable::Find (char const * str); // BAD BAD BAD !!! |
The sequencer would be allocated inside Find using new and would have to be deleted once the sequencing is finished.
We have created a monster! We substituted simple, fool-proof code with a dangerous kludge of a code. Donĺt laugh! Youĺll find this kind of coding practices turned into methodology in some commercially available libraries or API sets.
Our solution to this is object inversion. Instead of creating an auxiliary object inside the callee and making the caller responsible for deleting it, weĺll let the caller create an auxiliary local object (on the stack) which will be freed automatically on exit from the scope. The constructor of this object will take a reference to the source object (in our case, the hash table) and negotiate with it the transfer of data. In fact, weĺve already seen this mechanism in action when we first introduced a sequencer. (It was a stack sequencer whose constructor took reference to the stack object.)
Hereĺs the new implementation of SymbolTable::Find that makes use of such a sequencer, IdSeq. It takes a reference to the hash table and obtains, from it, a list corresponding to string str.
int SymbolTable::Find (char const * str) const
{
// Iterate over a short list from hash table
for (IdSeq seq (_htab, str);
!seq.AtEnd ();
seq.Advance ())
{
int id = seq.GetId ();
int offStr = _offStr [id];
// char const * strStored = &_strBuf [offStr];
char const * strStored = _strBuf + offStr;
if (strcmp (str, strStored) == 0) // they're equal
{
return id; // success!
}
}
return idNotFound;
}
|
Thatĺs how it looks from the clientĺs side. Searching through the hash table is reduced to the act of creating a sequencer corresponding to the pair: hash table, string. In other words, we have transformed a situation where a string sent to a hash table resulted in a sequencer into an equivalent one, where a sequencer is created from the interaction between the hash table and a string.
I still havenĺt explained how the whole thing is implemented. Obviously IdSeq is a special class that knows something about the workings of the hash table. Behind our backs it still obtains a linked list from the hash table and uses it for sequencing. The difference though is that the hash table no longer gives linked lists away to just anybody. The HTable::Find method is private and it can only be accessed by our friend--and now HTableĺs friend--IdSeq.
class HTable
{
friend class IdSeq;
ů
private:
List & Find (char const * str) const;
ů
};
|
One more cosmetic issue: The linked list sequencer is really a more general class, i. e., it belongs in the file vlist.h and should have nothing to do with the hash table. Something like that would be perfect:
// List sequencer
// Usage:>
// for (ListSeq seq (list);
// !seq.AtEnd ();
// seq.Advance ())
// {
// int id = seq.GetId ();
// ...
// }
class ListSeq
{
public:
ListSeq (List const & list)
: _pLink (list.GetHead ()) {}
bool AtEnd () const { return _pLink == 0; }
void Advance () { _pLink = _pLink->Next (); }
int GetId () const { return _pLink->Id (); }
private:
Link const * _pLink; // current link
};
|
On the other hand, we need a specialized sequencer that interacts with the hash table in its constructor.
Nothing is simpler than that. Hereĺs a sequencer that inherits everything from the generic sequencer. It only provides its own constructor, which obtains the linked list from the hash table and passes it to the parentĺs constructor. Thatĺs exactly what we needŚ-no less no more.
// The short list sequencer
// The client creates this sequencer
// to search for a given string
class IdSeq: public ListSeq
{
public:
IdSeq (HTable const & htab, char const * str)
: ListSeq (htab.Find (str)) {}
};
|
Letĺs summarize the situation. There are five actors in this game, so it is still possible to keep them all in mind at once. Table 1 lists them and explains their roles.
Table:
| List | vlist.h | Generic singly linked list storing data by value |
| ListSeq | vlist.h | Generic seqencer of a singly linked list |
| IdSeq | htab.h | Specialized sequencer: friend of HTable, inherits behavior from ListSeq. |
| HTable | htab.h | Hash table. For clients, the access is only through IdSeq. For friends, private method Find returns a List |
| SymbolTable | symtab.h | The client of HTable. Accesses HTable only through specialized IdSeq. |
Notice how the classes are grouped: List and ListSeq form one team. They are generic enough to be ready for reuse. IdSeq and HTable form another team that depends for its implementation on the List team. They are also ready for reuse. The SymbolTable depends on the HTable and a rather disorganized mix of objects to store strings. (Letĺs make a note to revisit this part of the code at a later time and do some cleanup.)
How do we measure our accomplishment? Suppose that we decide to change the implementation of the hash table to something that is called closed hashing. In such scheme the overflow entries are stored in the same array as the direct entries. The overflow list is no longer a linked list, but rather a prescription how to jump around that array. It can be encapsulated in a sequencer (which, of course, has to be a friend of the hash table).
So whatĺs the meta-program that transforms the symbol table from one implementation of the hash table to another? Provided we named our new classes the same names as before (HTable and IdSeq), the meta-program is empty. We donĺt have to touch a single line of code in the symbol table. Thatĺs quite an accomplishment!
Correcting Design Flaws
As I mentioned before, our parser of arithmetic expressions has a flaw--its grammar is right associative. That means that an expression like this
8 - 2 + 1
|
will be parsed as
8 - (2 + 1) = 5
|
(8 - 2) + 1 = 7.
|
We could try to correct the grammar to contain left associative productions of the type
Expression := Expression '+' Term
|
but they would immediately send our recursive parser into an infinite recursive spin (Expr would start by calling Expr that would start by calling Expr, that wouldů). There are more powerful parsing algorithms that can deal with left recursion but they are too complicated for our simple calculator. There is however a middle-of-the-road solution that shifts associativity from grammar to execution. In that approach, the expression parser keeps parsing term after term and stores them all in a new type of multi-node. All terms that are the children of the multi-node have the same status, but when it comes to calculation, they are evaluated from left to right. For instance, the parsing of the expression
8 - 2 + 1
|
would result in a tree in Figure 3-2.
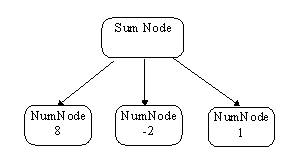
Figure. The result of parsing 8 - 2 + 1 using a multi-node.
The Calc method of the multi-node SumNode sums the terms left to right, giving in the correct answer
8 - 2 + 1 = 7
|
We can do the same trick with the parsing of terms--to correct the associativity of factors.
The grammar is modified to contain productions of the type (this is called the extended BNF notation)
Expr := Term { ('+' | '-') Term }
Term := Factor { ('*' | '/') Factor }
|
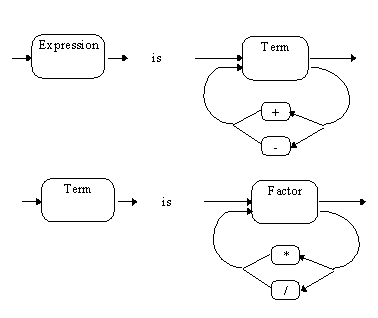
Figure. Extended productions for expressions and terms.
The phrase "zero or more occurrences" translates directly into the do/while loop in a recursive parser. Below is the corrected implementation of Parser::Expr.
Node * Parser::Expr ()
{
// Parse a term
Node * pNode = Term ();
EToken token = _scanner.Token ();
if (token == tPlus || token == tMinus)
{
// Expr := Term { ('+' | '-') Term }
MultiNode * pMultiNode = new SumNode (pNode);
do
{
_scanner.Accept ();
Node * pRight = Term ();
pMultiNode->AddChild (pRight, (token == tPlus));
token = _scanner.Token ();
} while (token == tPlus || token == tMinus);
pNode = pMultiNode;
}
else if (token == tAssign)
{
_scanner.Accept ();
// Expr := Term = Expr
Node * pRight = Expr ();
// provided the Term is an lvalue
if (pNode->IsLvalue ())
{
// Assignment node
pNode = new AssignNode (pNode, pRight);
}
else
{
_status = stError;
delete pNode;
pNode = Expr ();
}
}
// otherwise Expr := Term
return pNode;
}
|
The coding of Parser::Term undergoes a similar transformation.
Node * Parser::Term ()
{
Node * pNode = Factor ();
EToken token = _scanner.Token ();
if (token == tMult || token == tDivide)
{
// Term := Factor { ('*' | '/') Factor }
MultiNode * pMultiNode = new ProductNode (pNode);
do
{
_scanner.Accept ();
Node * pRight = Factor ();
pMultiNode->AddChild (pRight, (token == tMult));
token = _scanner.Token ();
} while (token == tMult || token == tDivide);
pNode = pMultiNode;
}
// otherwise Term := Factor
return pNode;
}
|
We have introduced two new types of Nodes: SumNode and ProductNode. They both share the property that they can have multiple children, and that these children have a 'sign' associated with each of them. In the SumNode the sign is plus or minus, in the ProductNode it could be the multiplication or the division sign. We will store pointers-to-children in one array and the corresponding signs in another array. The convention will be that addition and multiplication signs are stored as true while subtraction and division signs are stored as false in the _isPositive Boolean array. The distinction will be obvious in the classes derived from the (abstract) base class MultiNode. MultiNode will represent whatĺs common between SumNode and ProductNode. For our first sloppy implementation we will arbitrarily restrict the number of children to 8--to be fixed later! Sloppy or not, we will test for the overflow and return an error when the user writes an expression (or term) with more than 8 children nodes.
const int MAX_CHILDREN = 8;
// Generic multiple node: an abstract class
class MultiNode: public Node
{
public:
MultiNode (Node * pNode)
: _isError (false)
{
_aChild [0] = pNode;
_aIsPositive[0] = true;
_iCur = 1;
}
~MultiNode ();
void AddChild (Node * pNode, bool isPositive)
{
if (_iCur == MAX_CHILDREN)
{
_isError = true;
return;
}
_aChild [_iCur] = pNode;
_aIsPositive [_iCur] = isPositive;
++_iCur;
}
protected:
bool _isError;
int _iCur;
Node * _aChild [MAX_CHILDREN];
bool _aIsPositive [MAX_CHILDREN];
};
|
|
An array of Boolean values can be most simply implemented as an array of bool. It is however not the most space efficient implementation. To store two possible values, true and false, all one needs is a bit. The standard C++ library uses this optimization in its implementation of the Boolean array. |
Here are the definitions of the two derived classes. Notice that since MultiNode is a Node, so is SumNode and ProductNode (the is-a relation is transitive).
// Summing
class SumNode: public MultiNode
{
public:
SumNode (Node * pNode)
: MultiNode (pNode) {}
double Calc () const;
};
// Multiplying and dividing.
// Sign in this case refers to
// the exponent: positive means multiply,
// negative means divide
class ProductNode: public MultiNode
{
public:
ProductNode (Node * pNode)
: MultiNode (pNode) {}
double Calc () const;
};
|
Donĺt forget to delete the children after weĺre done.
MultiNode::~MultiNode ()
{
for (int i = 0; i < _iCur; ++i)
delete _aChild [i];
}
|
And here comes our pièce de résistance. The Calc methods that makes our algebra left associative.
double SumNode::Calc () const
{
if (_isError)
{
cerr << "Error: too many terms\n";
return 0.0;
}
double sum = 0.0;
for (int i = 0; i < _iCur; ++i)
{
double val = _aChild [i]->Calc ();
if (_aIsPositive [i])
sum += val;
else
sum -= val;
}
return sum;
}
// Notice: the calculation is left associative
double ProductNode::Calc () const
{
if (_isError)
{
cerr << "Error: too many terms\n";
return 0.0;
}
double prod = 1.0;
for (int i = 0; i < _iCur; ++i)
{
double val = _aChild [i]->Calc ();
if (_aIsPositive [i])
prod *= val;
else if (val != 0.0)
{
prod /= val;
}
else
{
cerr << "Error: division by zero\n";
return HUGE_VAL;
}
}
return prod;
}
|
Next.