Code Review 5: Resource Management
source
There's one important flaw in our program. It assumes that memory allocation never fails. This assumption is blatantly false. Granted, in a virtual-memory system allocation limits are rather high. In fact, the computer is not even limited by the size of its physical memory. The only way memory allocation may fail is if you run out of space in the swap file on your disk. Now, that's not something unheard of in the world of huge applications and multimedia files. An industrial-strength program should protect itself from it. The question is, how? What should a program do when the call to new fails? First of all, if we don't do anything about it (as indeed we didn't), the system will terminate us with extreme prejudice. That's totally unacceptable!
The next, slightly more acceptable thing would be to print a good-bye message and exit. For a program such as our calculator that might actually be the correct thing. It's not like the user runs the risk of losing hours of work when the calculator unexpectedly exits.
There are a few different ways to globally intercept a memory failure. One is to catch the bad_alloc exception--more about it in a moment--another, to create your own "new handler" and register it with the runtime at the beginning of your program. The function set_new_handler is defined in the header <new>. It accepts a pointer to a function that's to be called in case new fails. Here's an example of a user-defined new handler:
void NewHandler ()
{
cerr << "Out of memory\n";
exit (1);
// not reached
return 0;
}
|
It displays a message end exits by calling a special function, exit from <cstdlib>.
This is how you register your handler--preferably at the beginning of main.
set_new_handler (&NewHandler); |
| If you have a non-standard-compliant compiler you might have to modify this code. For instance, in Microsoft VC++ 6.0 there is a function called _set_new_handler that serves a similar purpose. Its declaration is in <new.h>. You'll also have to change the signature of the function you pass to it--to int NewHandler (size_t size). |
Although in many cases such a solution is perfectly acceptable, most commercial programs require more sophisticated techniques (and maybe, at some point in the future, will actually apply them!). Just try to imagine a word processor (or a compiler) suddenly exiting without giving you a chance to save your work. Sounds familiar?!
What happens when memory allocation fails? In standard C++, operator new generates an exception. So let's talk about exceptions.
Exceptions
in C++ we deal with exceptional failures using exceptions. Essentially it is up to the programmer to decide what is exceptional and what isn't. A memory allocation failure is considered exceptional--so is a failed disk read or write. On the other hand "file not found" or "end of file" are considered normal events. When an exceptional condition occurs, the program can throw an exception. A throw bypasses the normal flow of control and lands us in the catch part of the nearest enclosing try/catch block. So throw really behaves like a non-local goto (non-local meaning that the control can jump across function calls).
We can best understand the use of exceptions using the calculator as an example. The only exceptional condition that we can anticipate there is the memory allocation failure. As I mentioned before, when new is not able to allocate the requested memory, it throws an exception of the type bad_alloc.
Again, this is true in the ideal world. At the time of this writing most compilers still haven't caught up with the standard. But don't despair, you can work around this problem by providing your own new-failure handler that throws an exception.
|
If we don't catch this exception, the program will terminate in a rather unpleasant way. So we better catch it. The program is prepared to catch an exception as soon as the flow of control enters a try/catch block. So let's open our try block in main before we construct the symbol table (whose constructor does the first memory allocations). At the end of the try block one must start a catch block that does the actual catching of the exception.
int main ()
{
// only if your new doesn't throw by default
_set_new_handler (&NewHandler);
try
{
char buf [maxBuf+1];
Status status;
SymbolTable symTab;
Function::Table funTab (symTab);
Store store (symTab);
...
}
catch (bad_alloc)
{
cerr << "Out of memory!\n";
}
catch (...)
{
cerr << "Internal error\n";
}
}
|
Here we have two catch blocks, one after another. The first will catch only one specific type of exception--the bad_alloc one--the second , with the ellipsis, will catch all the rest. The "internal error" may be a general protection fault or division by zero in our program. Not that we plan on allowing such bugs! But it's always better to display a message end exit than to let the system kill us and display its own message.
| Always enclose the main body of your program within a try/catch block. |
Figure 1 illustrates the flow of control after an exception is thrown during the allocation of the SumNode inside Parser::Expr that was called by Parser::Parse called from within the try block inside main.
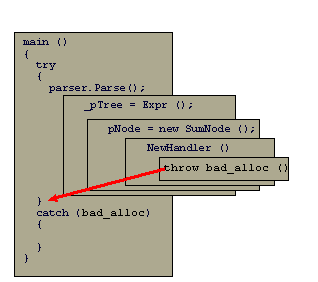
Figure 1. Throw and catch across multiple function calls.
The use of exceptions solves the problem of error propagation (see sidebar) by bypassing the normal flow of control.
|
In the old times, memory allocation failure used to be reported by new returning a null pointer. A programmer who wanted to protect his program from catastrophic failures had to test the result of every allocation. Not only was it tedious and error-prone, but it wasn't immediately clear what to do when such a failure occured. All a low level routine could do is to stop executing and return an error code to the calling routine. That, of course, put the burden of checking for error returns on the caller. In most cases the caller had little choice but to pass the same error code to its caller, and so on. Eventually, at some higher level--maybe even in main--somebody had the right context to do something about the problem, e.g., report it to the user, try to salvage his work, and maybe exit. Not only was such methodology error prone (forgetting to check for error returns), but it contributed dangerously to the obfuscation of the main flow of control. By the way, this problem applies to all kinds of errors, not only memory allocation failures. |
|
Since exceptions should not happen during normal program execution, it would make sense for your debugger to stop whenever an exception is thrown. This is particularly important when you have a catch-all clause in your program. It will not only catch those exceptions that are explicitly thrown--it will catch hardware exceptions caused by accessing a null pointer or division by zero. Those definitely require debugging. Unfortunately, not all debuggers stop automatically on exceptions. For instance, Microsoft Visual C++ defaults to "stop only if not caught". You should change it. The appropriate dialog is available from the Debug menu (which is displayed only during debugging). Select the Exceptions item and change the action on all exceptions to "stop always." |
Stack Unwinding
Figuring out how to propagate an error is the easy part. The real problem is the cleanup. You keep allocating memory in your program and, hopefully, you remember to deallocate it when it's no longer needed. If this weren't hard enough within the normal flow of control, now you have to remember to deallocate this memory when propagating an error.
Many a scheme was invented to deal with the cleanup during traditional error propagation. Since in most cases memory resources were freed at the end of procedures, one method was to use gotos to jump there whenever an error was detected. A typical procedure might look something like this:
|
Wait, it gets worse before it gets better! When you use exceptions to propagate errors, you don't get a chance to clean-up your allocations unless you put try/catch pairs in every procedure. Or so it seems. The straightforward translation of the sidebar example would look something like this:
void foo ()
{
Type1 * p1 = 0;
Type2 * p2 = 0;
try
{
p1 = new Type1;
call1 (p1);
p2 = new Type2;
status = call2 (p2);
// more of the same
}
catch (...)
{
delete p2;
delete p1;
throw;
}
delete p2;
delete p1;
}
|
This code looks cleaner but it's still very error-prone. Pointers are zeroed in the beginning of the procedure, assigned to in the middle and deallocated at the end (notice the ugly, but necessary, repetition of the two delete statements). Plenty of room for mistakes. By the way, the throw with no argument re-throws the same exceptions that was caught in the enclosing catch block.
At this point you might feel desperate enough to start thinking of switching to Java or some other language that offers automatic garbage collection. Before you do, read on.
There is a mechanism in C++ that just begs to be used for cleanup--the pairing of constructors and destructors of automatic objects. Once an object is constructed in some local scope, it is always automatically destroyed when the flow of control exits that scope. The important thing is that it really doesn't matter how the scope is exited: the flow of control may naturally reach the closing bracket, or it may jump out of the scope through a goto, a break or a return statement. Automatic objects are always destroyed. And yes--this is very important--when the scope is exited through an exception, automatic objects are cleaned up too! Look again at Figure 1--all the stack based objects in all the nested scopes between the outer try block and the inner throw block are automatically destroyed--their destructors are executed in the inverse order of construction.
I'll show you in a moment how to harness this powerful mechanism, called stack unwinding, to do all the cleanup for us. But first let's consider a few tricky situations.
For instance, what happens when an exception is thrown during construction? Imagine an object with two embeddings. In its constructor the two embedded objects are constructed, either implicitly or explicitly (through the preamble). Now suppose that the first embedding has been fully constructed, but the constructor of the second embedding throws an exception. What do you think should happen? Shouldn't the first embedding be destroyed in the process of unwinding? Right on! That's exactly what happens--the destructors of all fully constructed sub-objects are executed during unwinding.
What if the object is dynamically allocated using new and its constructor throws an exception? Shouldn't the memory allocated for this object be freed? Right again! That's exactly what happens--the memory allocated by new is automatically freed if the constructor throws an exception.
What if the heap object has sub-objects and the constructor of the nth embedding throws an exception? Shouldn't the n-1 sub-objects be destroyed and the memory freed? You guessed it! That's exactly what happens.
Remember the rules of object construction? First the base class is constructed, then all the embedded objects are constructed, finally the body of the constructor is executed. If at any stage of the construction an exception is thrown, the whole process is reversed and all the completely constructed parts of the object are destroyed (in the reverse order of construction).
What if an exception is thrown during the construction of the nth element of an array. Shouldn't all the n-1 fully constructed elements be destroyed? Certainly! That's exactly what happens. It all just works!
These rules apply no matter whether the object (array) is allocated on the stack or on the heap. The only difference is that, once a heap object is fully constructed, it (and its parts) will not take part in the process of stack unwinding.
There is only one situation when stack unwinding might not do the right thing. It's when an exception is thrown from within a destructor. So don't even think of allocating some scratch memory, saving a file to disk, or doing any of the many error-prone actions in a destructor. A distructor is supposed to quietly clean up.
| Never perform any action that could throw an exception inside a destructor. |
Now take our symbol table.
class SymbolTable
{
...
private:
HTable _htab;
std::vector<int> _aOffStr;
StringBuffer _bufStr;
};
|
It has three embedded objects, all with nontrivial constructors. The hash table allocates an array of lists, the vector of offsets might allocate some initial storage and the string buffer allocates a buffer for strings. Any one of these allocations may fail and throw an exception.
If the constructor of the hash table fails, there is no cleanup (unless the whole SymbolTable object was allocated using new--in that case the memory for it is automatically freed). If the hash table has been successfully constructed but the vector fails, the destructor of the hash table is executed during unwinding. Finally, if the exception occurs in the constructor of the string buffer, the destructors of the vector and the hash table are called (in that order).
The constructor of the hash table itself could have some potentially interesting modes of failure.
HTable::HTable (int size)
: _size (size)
{
_aList = new List<int> [size];
}
|
Assume for a moment that the constructor of List<int> is nontrivial (for example, suppose that it allocates memory). The array of 65 (cSymInit + 1) lists is constructed in our calculator. Imagine that the constructor of the 8th list throws an exception. The destructors of the first seven entries of the array will automatically be called, after which the memory for the whole array will be freed. If, on the other hand, all 65 constructors succeed, the construction of the hash table will be successful and the only way of getting rid of the array will be through the destructor of the hash table.
But since the hash table is an embedded object inside the symbol table, and the symbol table is an automatic object inside the try block in main, its destruction is guaranteed. Lucky accident? Let's have another look at main.
int main ()
{
_set_new_handler (&NewHandler);
try
{
...
SymbolTable symTab;
Function::Table funTab (symTab);
Store store (symTab);
...
{
Scanner scanner (buf);
Parser parser (scanner, store, funTab, symTab);
...
}
}
catch (...)
{
...
}
}
|
It looks like all the resources associated with the symbol table, the function table, the store, the scanner and the parser are by design guaranteed to be released. We'll see in a moment that this is indeed the case.
Resources
So far we've been dealing with only one kind of resource--memory. Memory is acquired from the runtime system by calling new, and released by calling delete. There are many other kinds of resources: file handles, semaphores, reference counts, etc. They all have one thing in common--they have to be acquired and released. Hence the definition:
| A resource is something that can be acquired and released. |
The acquiring part is easy--it's the releasing that's the problem. An unreleased resource, or resource leak, can be anywhere from annoying (the program uses more memory than is necessary) to fatal (the program deadlocks because of an unreleased semaphore).
We can guarantee the matching of the acquisition and the release of resources by following the simple First Rule of Acquisition:
| Acquire resources in constructors, release resources in matching destructors. |
In particular, the acquisition of memory through new should be only done in a constructor, with the matching delete in the destructor. You'll find such matching pairs in the constructors and destructors of FunctionTable, HTable (and std::vector<T>, if you look it up in <vector>). (The other occurrences of new in our program will be explained later.)
However, if you look back at the symbol table right before we separated out the string buffer, you'll see something rather disturbing:
SymbolTable::SymbolTable (int size)
: _size (size), _curId (0), _curStrOff (0), _htab (size + 1)
{
_offStr = new int [size];
_bufSize = size * 10;
_strBuf = new char [_bufSize];
}
SymbolTable::~SymbolTable ()
{
delete []_offStr;
delete []_strBuf;
}
|
The First Rule of Acquisition is being followed all right, but the code is not exception safe. Consider what would happen if the second allocation (of _strBuf) failed. The first allocation of _offStr would have never been freed.
To prevent such situations, when programming with exceptions, one should keep in mind the following corollary to the First Rule of Acquisition:
| Allocation of resources should either be the last thing in the constructor or be followed by exception safe code. |
If more than one resource needs to be allocated in a constructor, one should create appropriate sub-objects to hold these resources. They will be automatically released even if the constructor fails before completion.
As you can see, there are many different arguments that lead to the same conclusion--it makes sense to separate sub-objects! We can even enhance our rule of thumb that suggested the separation of sub-object when a class had too many data members: Create sub-objects when more than one data member points to a resource. In our symbol table it was the introduction of the following two sub-objects that did the job.
std::vector<int> _aOffStr;
StringBuffer _bufStr;
|
Ownership of Resources
An object or a block of code owns a resource if it is responsible for its release. The concept of ownership of resources is central to the resource management paradigm. The owns-a relationship between objects parallels the more traditional is-a (inheritance) and has-a (embedding) relationships. There are several forms of ownership.
A block of code owns all the automatic objects defined in its scope. The job of releasing these resources (calling the destructors) is fully automated.
Another form of ownership is by embedding. An object owns all the objects embedded in it. The job of releasing these resources is automated as well (the destructor of the big object calls the destructors for the embedded objects).
In both cases the lifetime of the resource is limited to the lifetime of the embedding entity: the activation of a given scope or the lifetime of an embedding object. Because of that, the compiler can fully automate destructor calls.
The same cannot be said for dynamically allocated objects that are accessed through pointers. During their lifetimes, pointers can point to a sequence of resources. Also, several pointers can point to the same resource. The release of such resources is not automated. If the object is being passed from pointer to pointer and the ownership relations cannot easily be traced, the programmer is usually in for a trouble. The symptoms may be various: uninitialized pointers, memory leaks, double deletions, etc.
Imposing the First Rule of Acquisition clarifies the ownership relationships and guarantees the absence of most errors of the types we have just listed. A block of code can only own its automatic objects--no naked pointers should be allowed there. An object can own other objects by embedding as well as through pointers. In the latter case though, the acquisition of the resources (initialization of pointers) has to take place in the object's constructor, and their release in the destructor. Constructors are the only places where a naked pointer may appear and then only for a very short time.
Notice that if all resources have owners, they are guaranteed to be released. The objects that own resources are either defined in the global scope, or in a local scope or are owned by other objects--through embeddings or through dynamic allocation in constructors. Global objects are destroyed after exit from main, local objects are destroyed upon exit from their scope, embeddings are either destroyed when the enclosing objects are destroyed, or when the enclosing constructor is aborted through an exception. Since all the owners are eventually destroyed, or the resources are eventually freed.
Access to Resources
A block of code or an object may operate on a resource without owning it, that is, without being responsible for its release. When granting or passing access, as opposed to ownership, one should try to use references whenever possible. We have already learned that the has-access-to relationship is best expressed using references. A reference cannot express ownership because an object cannot be deleted through a reference (at least not without some trickery).
There are rare cases when using a reference is awkward or impossible. In such cases one can use a weak pointer--a pointer that doesn't express ownership--only access. In C++ there is no syntactic difference between strong and week pointers, so this distinction should be made by the appropriate commenting of the code.
We will graphically represent the has-access-to relationship (either through a reference or through a weak pointer) by a dotted arrow, as in Figure 2.
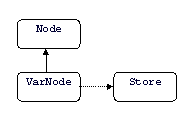
Figure 2. Graphical representation of the has-access-to relationship between VarNode and Store.
| If access to a resource is reference-counted, the ownership rules apply to the reference count itself. Reference count should be acquired (incremented) in a constructor and released (decremented) in a destructor. The object itself may be passed around using a reference or a pointer, depending on whether there is one distinguished owner, or the ownership is distributed (the last client to release the reference count, destroys the object). |
Smart Pointers
Our calculator was implemented with no regard for resource management. There are naked pointers all over the place, especially in the parser. Consider this fragment.
do
{
_scanner.Accept();
Node * pRight = Term ();
pMultiNode->AddChild (pRight, (token == tPlus));
token = _scanner.Token();
} while (token == tPlus || token == tMinus);
|
The call to Term returns a node pointer that is temporarily stored in pRight. Then the MultiNode's method AddChild is called, and we know very well that it might try to resize its array of children. If the reallocation fails and an exception is thrown, the tree pointed to by pRight will never be deallocated. We have a memory leak.
Before I show you the systematic solution to this problem, let's try the obvious thing. Since our problem stems from the presence of a naked pointer, let's create a special purpose class to encapsulate it. This class should acquire the node in its constructor and release it in the destructor. In addition to that, we would like objects of this class to behave like regular pointers. Here's how we can do it.
class NodePtr
{
public:
NodePtr (Node * pNode) : _p (pNode) {}
~NodePtr () { delete _p; }
Node * operator->() const { return _p; }
Node & operator * () const { return *_p; }
private:
Node * _p;
};
|
Such objects are called safe or smart pointers. The pointer-like behavior is implemented by overloading the pointer-access and pointer-dereference operators. This clever device makes an object behave like a pointer. In particular, one can call all the public methods (and access all public data members, if there were any) of Node by "dereferencing" an object of the type NodePtr.
{
Node * pNode = Expr ();
NodePtr pSmartNode (pNode);
double x = pSmartNode->Calc (); // pointer-like behavior
...
// Automatic destruction of pSmartNode.
// pNode is deleted by its destructor.
}
|
Of course, a smart pointer by itself will not solve our problems in the parser. After all we don't want the nodes created by calling Term or Factor to be automatically destroyed upon normal exit from the scope. We want to be able to build them into the parse tree whose lifetime extends well beyond the local scope of these methods. To do that we have to relax our First Rule of Acquisition .
Ownership Transfer: First Attempt
When the lifetime of a given resource can be mapped into the lifetime of some scope, we encapsulate this resource in a smart pointer and we're done. When this can't be done, we have to pass the resource between scopes. There are two possible directions for such transfer: up and down. A resource may be passed up from a procedure to the caller (returned), or it can be passed down from a caller to the procedure (as an argument). We assume that before being passed, the resource is owned by some type of owner object (e.g., a smart pointer).
Passing a resource down to a procedure is relatively easy. We can simply pass a reference to the owner object (a smart pointer, in our case) and let the procedure acquire the ownership from it. We'll add a special method, Release, to our smart pointer to release the ownership of the resource.
Node * NodePtr::Release ()
{
Node * tmp = _p;
_p = 0;
return tmp;
}
|
The important thing about Release is that it zeroes the internal pointer, so that the destructor of NodePtr will not delete the object (delete always checks for a null pointer and returns immediately). After the call to Release the smart pointer no longer owns the resource. So who owns it? Whoever called it better provide a new owner!
This is how we can apply this method in our program. Here, the node resource is passed from the Parser's method Expr down to the MultiNode's method AddChild.
do
{
_scanner.Accept();
NodePtr pRight (Term ());
pMultiNode->AddChild (pRight, (token == tPlus));
token = _scanner.Token();
} while (token == tPlus || token == tMinus);
|
AddChild acquires the ownership of the node by calling the Release method and passes it immediately to the vector _aChild (if you see a problem here, read on, we'll tackle it later).
void MultiNode::AddChild (NodePtr & pNode, bool isPositive)
{
_aChild.push_back (pNode.Release ());
_aIsPositive.push_back (isPositive);
}
|
Passing a resource up is a little trickier. Technically, there's no problem. We just have to call Release to acquire the resource from the owner and then return it back. For instance, here's how we can return a node from Parser::Expr.
Node * Parser::Expr ()
{
// Parse a term
NodePtr pNode (Term ());
...
return pNode.Release ();
}
|
What makes it tricky is that now the caller of Expr has a naked pointer. Of course, if the caller is smart, he or she will immediately find a new owner for this pointer--presumably a smart pointer--just like we did a moment ago with the result of Term. But it's one thing to expect everybody to take special care of the naked pointers returned by new and Release, and quite a different story to expect the same level of vigilance with every procedure that happens to return a pointer. Especially that it's not immediately obvious which ones are returning strong pointers that are supposed to be deleted, and which return weak pointers that must not be deleted.
Of course, you may choose to study the code of every procedure you call and find out what's expected from you. You might hope that a procedure that transfers ownership will be appropriately commented in its header file. Or you might rely on some special naming convention--for instance start the names of all resource-returning procedures with the prefix "Query" (been there!).
Fortunately, you don't have to do any of these horrible things. There is a better way. Read on!
To summarize, even though there are some big holes in our methodology, we have accomplished no mean feat. We have encapsulated all the resources following the First Rule of Acquisition. This will guarantee automatic cleanup in the face of exceptions. We have a crude method of transfering resources up and down between owners.
Ownership Transfer: Second Attempt
So far our attempt at resource transfer through procedure boundaries have been to release the resource from its owner, pass it in its "naked" form and then immediately encapsulate it again. The obvious danger is that, although the passing happens within a few nanosecond in a running program, the code that accepts the resource may be written months or even years after the code that releases it. The two sides of the procedure barrier don't necessarily talk to each other.
But who says that we have to "undress" the resource for the duration of the transfer? Can't we pass it together with its encapsulator? The short answer is a resounding yes! The longer answer is necessary in order to explain why it wouldn't work without some unorthodox thinking.
First of all, if we were to pass a smart pointer "as is" from a procedure to the caller, we'd end up with a dangling pointer.
NodePtr Parser::Expr ()
{
// Parse a term
NodePtr pNode = Term (); // <- assignment
...
return pNode; // <- by value
}
NodePtr Parser::Term ()
{
NodePtr pNode = Factor (); // <- assignment
...
return pNode; // <- by value
}
|
Here's why: Remember how objects are returned from procedures? First, a copy constructor is called to construct a temporary, then the assignment operator is called to copy this temporary into the caller's variable. If an object doesn't define its own copy constructor (or assignment operator), one will be provided for it by the compiler. The default copy constructor/assignment makes a shallow copy of the object. It means that default copying of a smart pointer doesn't copy the object it points to. That's fine, we don't want a copy of our resource. We end up, however, with two smart pointers pointing to the same resource. That's bad in itself. To make things even worse, one of them is going out of scope--the smart pointer defined inside the procedure. It will delete the object it points to, not realizing that its clone brother has a pointer to it, too. We've returned a smart pointer, all right, but it points to a deleted object.
What we need is to enforce the rule that there may only be one owner of a given resource at a time. If somebody tries to clone a smart pointer, we have to steal the resource from the original owner. To that end we need to define our own copy constructor and assignment operator.
NodePtr::NodePtr (NodePtr & pSource)
: _p (pSource.Release ())
{}
NodePtr & NodePtr::operator= (NodePtr & pSource)
{
if (_p != pSource._p)
{
delete _p;
_p = pSource.Release ();
}
}
|
Notice that these are not your usual copy constructor and assignment operator. For one, they don't take const references to their source objects. They can't, because they modify them. And modify they do, drastically, by zeroing out their contents. We can't really call it "copy semantics," we call it "transfer semantics." We provide a class with transfer semantics when we give it a "transfer constructor" and overload its assigment operator such that each of these operations takes away the ownership of a resource from its argument.
It's time to generalize our accomplishments. We need a template class that is a smart pointer with transfer semantics. We can actually find it in the standard library, in the header <memory>, under the name auto_ptr. Instead of NodePtr, we'll start using std::auto_ptr<Node> whenever node ownership is concerned.
| The standards committee struggled with the definition of auto_ptr almost till the last moment. Don't be surprised then if your compiler's library contains an older version of this template. For instance, you might discover that your auto_ptr contains an ownership flag besides the pointer. Such implementation is now obsolete. |
Let's begin with UMinusNode, which has to accept the ownership of its child node in the constructor. The child node is passed, of course, in an auto_ptr. We could retrieve it from the auto_ptr by calling its release method. We could then store the pointer and delete it in the destructor of UminusNode--all in the spirit of Resource Management. But there's a better way! We can embed an auto_ptr inside UminusNode and let it deal with ownership chores.
class UMinusNode: public Node
{
public:
UMinusNode (auto_ptr<Node> & pNode)
: _pNode (pNode) // <- "transfer" constructor
{}
double Calc () const;
private:
auto_ptr<Node> _pNode;
};
|
Look what happened--there no longer is a need for UMinusNode to have a destructor, because embeddings are destroyed automatically. We don't have to call release on the argument to the constructor, because we can pass it directly to the "transfer" constructor of our embedded auto_ptr. Internally, the implementation of UMinusNode::Calc remains unchanged, because the syntax for accessing a pointer and an auto_ptr is identical.
We can immediately do the same conversion with FunNode, BinNode and AssignNode. BinNode contains two auto_ptrs.
class BinNode: public Node
{
public:
BinNode (auto_ptr<Node> & pLeft, auto_ptr<Node> & pRight)
: _pLeft (pLeft), _pRight (pRight)
{}
protected:
auto_ptr<Node> _pLeft;
auto_ptr<Node> _pRight;
};
class AssignNode : public BinNode
{
public:
AssignNode (auto_ptr<Node> & pLeft, auto_ptr<Node> & pRight)
: BinNode (pLeft, pRight)
{}
double Calc () const;
};
|
As before, we were able to get rid of explicit destructors.
We can continue our destructor derby with the Parser itself. It can own its parsing tree through an auto_ptr and gone is its explicit destructor.
auto_ptr<Node> _pTree; |
We can't get rid of the destructor of MultiNode yet. For the time being, let's just rewrite it so that it accepts auto_ptrs as arguments to its methods. We'll return to the issue "owning containers" later.
class MultiNode: public Node
{
public:
MultiNode (auto_ptr<Node> & pNode)
{
AddChild (pNode, true);
}
~MultiNode ();
void AddChild (auto_ptr<Node> & pNode, bool isPositive)
{
_aChild.push_back (pNode.release ());
_aIsPositive.push_back (isPositive);
}
protected:
std::vector<Node*> _aChild;
std::vector<bool> _aIsPositive;
};
|
And now let's look at the Parser::Expr method after it's been generously sprinkled with auto_ptrs.
auto_ptr<Node> Parser::Expr ()
{
// Parse a term
auto_ptr<Node> pNode = Term ();
if (pNode.get () == 0)
return pNode;
EToken token = _scanner.Token ();
if (token == tPlus || token == tMinus)
{
// Expr := Term { ('+' | '-') Term }
auto_ptr<MultiNode> pMultiNode (new SumNode (pNode));
do
{
_scanner.Accept ();
auto_ptr<Node> pRight = Term ();
pMultiNode->AddChild (pRight, (token == tPlus));
token = _scanner.Token ();
} while (token == tPlus || token == tMinus);
// with member template support
pNode = pMultiNode; // <- Up-casting!
// pNode = up_cast<Node> (pMultiNode);
}
else if (token == tAssign)
{
_scanner.Accept ();
// Expr := Term = Expr
auto_ptr<Node> pRight = Expr ();
// provided the Term is an lvalue
if (pNode->IsLvalue ())
{
// Assignment node
pNode = auto_ptr<Node> (new AssignNode (pNode, pRight));
}
else
{
_status = stError;
pNode = Expr ();
}
}
// otherwise Expr := Term
return pNode;
}
|
There is one tricky point in this code that requires some explaining. We are dealing with two types of auto_ptrs--one encapsulating a Node and another encapsulating a MultiNode (only MultiNode has the AddChild method). At some point, when we are done adding children, we must convert a pointer to MultiNode to a pointer to Node. With pointers it was no trouble, because a MultiNode "is-a" Node (they are related through inheritance). But auto_ptr<Node> is a totally different class from auto_ptr<MultiNode>. So this simple line of code:
pNode = pMultiNode; // <- Up-casting! |
Look at the following code--a transfer constructor and an assignment operator override are added to the auto_ptr template.
template<class T>
class auto_ptr
{
public:
...
// "transfer" from derived class
template<class U>
auto_ptr (auto_ptr<U> & pSrc)
{
_p = pSrc.release ();
}
// assignment of derived class
template<class U>
auto_ptr & operator= (auto_ptr<U> & pSrc)
{
if (this != &pSrc)
_p = pSrc.release ();
return *this;
}
};
|
The new transfer constructor can be used to construct an auto_ptr of one type, parametrized by T, from an auto_ptr of another type, parametrized by U. So, in fact, this constructor is a template parametrized by two types, T and U.
The new overload of the assignment operator can accept an auto_ptr parametrized by an arbitrary type U. It's this override that's invoked in the statement:
pNode = pMultiNode; // <- Up-casting from MultiNode to Node |
_p = pSrc.release (); |
pMultiNode = pNode; // <- Error! Down-casting |
The bottom line is that the assignment of auto_ptrs will only work for those types for which the assignment of pointers works. Notice that the types don't have to be related by inheritance. You can, for instance, implicitly convert a pointer to Node to a void pointer. It follows than you can convert auto_ptr<Node> to auto_ptr<void>.
If your compiler doesn't support member templates, don't despair! I have a workaround for you. Since you won't be able to do implicit auto_ptr conversion, you'll have to do it explicitly.
|
It's pretty straightforward to convert the rest of the Parser to use auto_ptrs.
To summarize: Memory resources can be safely kept and transferred from one point to another using auto_ptrs. You can easily transform an existing program to use Resource Management techniques. Just search your project for all calls to new and make sure the resulting pointers are safely tucked inside auto_ptrs.
Safe Containers
We are not done yet. There are still some parts of our program that are not 100% resource safe. Let's go back to one such place inside the class MultiNode.
class MultiNode: public Node
{
public:
MultiNode (auto_ptr<Node> & pNode)
{
AddChild (pNode, true);
}
~MultiNode ();
void AddChild (auto_ptr<Node> & pNode, bool isPositive)
{
_aChild.push_back (pNode.release ());
_aIsPositive.push_back (isPositive);
}
protected:
std::vector<Node*> _aChild;
std::vector<bool> _aIsPositive;
};
|
Look what happens inside AddChild. We call release on pNode and then immediately call push_back on a vector. We know that push_back might re-allocate the vector's internal array. A re-allocation involves memory allocation which, as we know, might fail. You see the problem? The pointer that we have just released from pNode will be caught naked in the middle of an allocation failure. This pointer will never get a chance to be properly deleted. We have a memory leak!
What is needed here is for the vector to be re-allocated before the pointer is released. We could force the potential reallocation by first calling
_aChild.reserve (_aChild.size () + 1); |
The culprit here is the vector of pointers, which has no notion of ownership. Notice that the deallocation of nodes is done not in the vector's destructor but rather in the MultiNode's destructor. What we need is some type of a vector that really owns the objects stored in it through pointers.
Could we use a vector of auto_ptrs?
std::vector<auto_ptr<Node> > _aChild; |
Although in principle this is a valid solution to our problem, in practice it's hardly acceptable. The trouble is that the vector's interface is totally unsuitable for storing objects with weird copy semantics. For instance, on a const vector, the array-access operator returns an object by value. This is fine, except that returning an auto_ptr by value involves a resource transfer. Similarly, if you try to iterate over such a vector, you might get a resource transfer every time you dereference an iterator. Unless you are very careful, you're bound to get some nasty surprizes from a vector of auto_ptrs.
At this point you might expect me to come up with some clever data structure from the standard library. Unfortunately, there are no ownership-aware containers in the standard library, so we'll have to build one ourselves. Fortunately--we have all the necessary tools. So let's start with the interface.
template <class T>
class auto_vector
{
public:
explicit auto_vector (size_t capacity = 0);
~auto_vector ();
size_t size () const;
T const * operator [] (size_t i) const;
T * operator [] (size_t i);
void assign (size_t i, auto_ptr<T> & p);
void assign_direct (size_t i, T * p);
void push_back (auto_ptr<T> & p);
auto_ptr<T> pop_back ();
};
|
Notice a rather defensive attitude in this design. I could have provided an array-access operator that would return an lvalue but I decided against it. Instead, if you want to set a value, you have to use one of the assign or assign_direct methods. My philosophy is that resource transfer shouldn't be taken lightly and, besides, it isn't needed all that often--an auto_vector is usually filled using the push_back method.
As far as implementation goes, we can simply use a dynamic array of auto_ptrs.
template <class T>
class auto_vector
{
~auto_vector () { delete []_arr; }
private:
void grow (size_t reqCapacity);
auto_ptr<T> *_arr;
size_t _capacity;
size_t _end;
};
|
The grow method allocates a larger array of auto_ptr<T>, transfers all the items from the old array, swaps it in, and deletes the old array.
template <class T>
void auto_vector<T>::grow (size_t reqCapacity)
{
size_t newCapacity = 2 * _capacity;
if (reqCapacity > newCapacity)
newCapacity = reqCapacity;
// allocate new array
auto_ptr<T> * arrNew = new auto_ptr<T> [newCapacity];
// transfer all entries
for (size_t i = 0; i < _capacity; ++i)
arrNew [i] = _arr [i];
_capacity = newCapacity;
// free old memory
delete []_arr;
// substitute new array for old array
_arr = arrNew;
}
|
The rest of the implementation of auto_vector is pretty straightforward, since all the complexity of resource management is built into auto_ptr. For instance, the assign method simply utilizes the overloaded assignment operator to both deallocate the old object and transfer the new object in one simple statement.
void assign (size_t i, auto_ptr<T> & p)
{
assert (i < _end);
_arr [i] = p;
}
|
The method assign_direct takes advantage of the reset method of auto_ptr:
void assign_direct (size_t i, T * p)
{
assert (i < _end);
_arr [i].reset (ptr);
}
|
The pop_back method returns auto_ptr by value, because it transfers the ownership away from auto_vector.
auto_ptr<T> pop_back ()
{
assert (_end != 0);
return _arr [--_end];
}
|
Indexed access to auto_vector is implemented in terms of the get method of auto_ptr, which returns a "weak" pointer.
T * operator [] (size_t i)
{
return _arr [i].get ();
}
|
With the new auto_vector the implementation of MultiNode is not only 100% resource-safe, but also simpler. One more explicit destructor bites the dust!
class MultiNode: public Node
{
public:
MultiNode (auto_ptr<Node> & pNode)
{
AddChild (pNode, true);
}
void AddChild (auto_ptr<Node> & pNode, bool isPositive)
{
_aChild.push_back (pNode);
_aIsPositive.push_back (isPositive);
}
protected:
auto_vector<Node> _aChild;
std::vector<bool> _aIsPositive;
};
|
How do we know when we're done? How do we know when our code is completely resource-safe? There is a simple set of tests, at least as far as memory resources are concerned, that will answer this question. We have to search our code for all occurrences of new and release and go through the following series of test:
- Is this a direct transfer to an auto_ptr?
- Or, are we inside a constructor of an object? Is the result of the call immediately stored within the object, with no exception prone code following it in the constructor?
- If so, is there a corresponding delete in the destructor of the object?
- Or, are we inside a method that immediately assigns the result of the call to a pointer owned by the object, making sure the previous value is deleted?
Iterators
Like any other standard container, our auto_vector needs iterators. I will not attempt to provide the full set of iterators--it's a tedious work best left to library implementors. All we'll ever need in our calculator is a forward-only constant iterator, so that's what I'll define.
An iterator is an abstraction of a pointer to an element of an array. It is also usually implemented as a pointer. It can be cheaply passed around and copied. Our auto_vector is implemented as an array of auto_ptr, so it's only natural that we should implement its iterator as a pointer to auto_ptr. It will be cheap to create, pass around and copy. Moreover, incrementing such an iterator is as easy as incrementing a pointer. The only thing that prevents us from just typedefing an auto_vector iterator to a pointer to auto_ptr is its dereferencing behavior. When you dereference a pointer to an auto_ptr, you get an auto_ptr with all its resource-transfer semantics. What we need is an iterator that produces a regular weak pointer upon dereferencing (and in the case of a constant iterator, a weak pointer to const). Operator overloading to the rescue!
template<class T>
class const_auto_iterator: public
std::iterator<std::forward_iterator_tag, T const *>
{
public:
const_auto_iterator () : _pp (0) {}
const_auto_iterator (auto_ptr<T> const * pp) : _pp (pp) {}
bool operator != (const_auto_iterator<T> const & it) const
{ return it._pp != _pp; }
const_auto_iterator operator++ (int) { return _pp++; }
const_auto_iterator operator++ () { return ++_pp; }
T const * operator * () { return _pp->get (); }
T const * operator-> () { return _pp->get (); }
private:
auto_ptr<T> const * _pp;
};
|
First of all, a well-bahaved iterator should inherit from the std::iterator template, so that it can be passed to various standard algorithms. This template is parametrized by an iterator tag (forward_iterator_tag in our case), which specifies the iterators's capabilities; and its value type (pointer to const T, in our case). (Strictly speaking, there is a third parameter, the difference type--the type that you get when you subtract one iterator from another, but this one correctly defaults to ptrdiff_t.)
We have two constructors--one default and one taking a pointer to a const auto_ptr. We have a not-equal operator. We have two increment operators. One of them overloads the post-increment and the other the pre-increment operator. To distinguish between the declarations of these two, you provide a dummy int argument to your declaration of the post-increment operator (yet another quirk of C++ syntax).
| In many cases the implementation of the pre-increment operator is simpler and more efficient then the corresponding implementation of the post-increment operator. It's easy to first increment something and then return it. Post-increment, on the other hand, could be tricky. In principle, you have to somehow remember the original state of the iterator, increment its internal variables and return an iterator that's created using the remembered state. Fortunately, when you're dealing with pointers, the compiler does all the work for you, so that the statement return p++; does the right things. But try implementing post-increment for a linked list iterator and you'll see what I mean. By the way, this is the reason why I'm biased towards using pre-increment in my code, unless post-increment is specifically called for. |
Our iterator has two dereference operators, both returning a weak pointer to const. The second one is useful if you want to call a method implemented by class T.
Inside the class auto_vector, we provide a traditional typedef and two methods begin () and end () to support iteration. Notice again that the end iterator poits one beyond the last element of the array. Notice also how in both methods a pointer to auto_ptr is automatically converted to a const_iterator. That's because we haven't restricted the appropriate constructor of const_auto_iterator to be explicit.
typedef const_auto_iterator<T> const_iterator;
const_iterator begin () const { return _arr; }
const_iterator end () const { return _arr + _end; }
|
Finally, let's look at an example of how our iterator might be used in the Calc method of SumNode.
double SumNode::Calc () const
{
double sum = 0.0;
auto_vector<Node>::const_iterator childIt = _aChild.begin ();
std::vector<bool>::const_iterator isPosIt = _aIsPositive.begin ();
for (; childIt != _aChild.end (); ++childIt, ++isPosIt)
{
assert (isPosIt != _aIsPositive.end ());
double val = childIt->Calc ();
if (*isPosIt)
sum += val;
else
sum -= val;
}
assert (isPosIt == _aIsPositive.end ());
return sum;
}
|
I said "might," because it's not immediately obvious that this style of coding, using iterators, is more advantageous that the traditional array-index iteration; especially when two parallel arrays are involved. I had to use the comma sequencing operator to squeeze two increment operations into one slot in the for-loop header. (Expressions separated by commas are evaluated in sequence. The value of the sequence is equal to the value of its last expression.)
On the other hand, this code would be easier to convert if we were to re-implement MultiNode to use linked lists instead of vectors. That, however, seems rather unlikely.
Error Propagation
Now that our code is exception-safe, we should reconsider our error-handling policy. Look what we've been doing so far when we detected a syntax error. We set the parser's status to stError and returned a null pointer from whatever parsing method we were in. It so happened that all syntax errors were detected at the lowest level, inside Parser::Factor. However, both Parser::Term and Parser::Expr had to deal with the possibility of a null node coming from a lower-level parsing method. In fact, Parser::Factor itself had to deal with the possibility that the recursive call to Expr might return a null. Our code was sprinkled with error-propagation artifacts like this one:
if (pNode.get () == 0)
return pNode;
|
Whenever there is a situation where an error has to be propagated straight through a set of nested calls, one should consider using exceptions. If we let Parser::Factor throw an exception whenever it detects a syntax error, we won't have to worry about detecting and propagating null pointers through other parsing methods. All we'll need is to catch this exception at the highest level--say in Parser::Parse.
class Syntax {};
Status Parser::Parse ()
{
try
{
// Everything is an expression
_pTree = Expr ();
if (!_scanner.IsDone ())
_status = stError;
}
catch (Syntax)
{
_status = stError;
}
return _status;
}
|
Notice that I defined a separate class of exceptions, Syntax, for propagating syntax errors. For now this class is empty, but its type lets me distinguish it from other types of exceptions. In particular, I don't want to catch bad_alloc exceptions in Parser::Parse, since I don't know what to do with them. They will be caught and dealt with in main.
Here's an example of code from Parser::Factor converted to use exceptions for syntax error reporting. Notice that we no longer test for null return from Expr (in fact we can assert that it's not null!).
if (_scanner.Token () == tLParen) // function call
{
_scanner.Accept (); // accept '('
pNode = Expr ();
assert (pNode.get () != 0);
if (_scanner.Token () == tRParen)
_scanner.Accept (); // accept ')'
else
throw Syntax ();
if (id != SymbolTable::idNotFound && id < _funTab.Size ())
{
pNode = auto_ptr<Node> (
new FunNode (_funTab.GetFun (id), pNode));
}
else
{
cerr << "Unknown function \"";
cerr << strSymbol << "\"" << endl;
throw Syntax ();
}
}
|
There is also some leftover code that dealt with symbol table overflows.
// Factor := Ident
if (id == SymbolTable::idNotFound)
{
id = _symTab.ForceAdd (strSymbol);
if (id == SymbolTable::idNotFound)
{
cerr << "Error: Too many variables\n";
_status = stError;
}
if (id != SymbolTable::idNotFound)
pNode = auto_ptr<Node> (new VarNode (id, _store));
}
|
Since we don't expect overflows, and memory allocation failures are dealt with by exceptions, we can simplify this code:
// Factor := Ident
if (id == SymbolTable::idNotFound)
{
id = _symTab.ForceAdd (strSymbol);
}
pNode = auto_ptr<Node> (new VarNode (id, _store));
|
Conversion
By now you should be convinced that any program that doesn't follow the principles of Resource Management described in this chapter has little chance of ever getting anywhere near the state of being bug-free. So what should you do if you already have a project that's ridden with resource bugs? Do you have to convert the whole project all at once, just like we did in our little program? Fortunately, not! You can do the conversion one step at a time.
Start by finding all occurrences of new in the whole project. If this is too much, divide your project into smaller areas and convert each of them in turn.
- For these calls to new that occur in constructors, make sure there is a corresponding delete in the destructor. Consider embedding an auto_ptr in your class to hold the result of such new.
- Outside constructors, make sure the result of new is:
- Immediately stored in a member variable that accepts the ownership--i.e., there is a matching delete in the destructor and the previous value is released prior to assignment, or
- Immediately stored in an auto_ptr.
- If you had to create a local auto_ptr in the previous step, call its release method before passing it down or up the chain of ownership. This is a temporary solution that will allow you to work in small increments.
- Once you're done with new, search for all occurrences of release that you have introduced in previous steps. They mark those spots where resource transfer takes place.
- If a resource is being passed down, change the signature of the called procedure to accept an auto_ptr (by reference or by value). If that procedure has to pass the ownership of the pointer still further, call release. You'll come back to this of release later.
- If a resource is being passed up, return auto_ptr by value. Fix all the callers to accept the returned auto_ptr. If they have to pass the ownership of the pointer still further, call release.
- If the ownership of a resource is being passed down to a container, consider converting that container to auto_vector.
- Whenever a pointer is converted to auto_ptr, the compiler will detect all the calls to delete that are no longer needed. Remove them.
This conversion procedure is recursive. At each step you might create some calls to release that will have to be fixed later. You are done converting when you can convince yourself that all the remaining calls to new and release are absolutely necessary and they pass the ownership directly into the member variables that know how to deal with it.
There are many other types of resources besides memory. They are usually obtained from the operating system and have to be returned back to it. They, too, should be encapsulated in smart objects. We'll see some examples later.
Conclusion
We started with a simple question: "What should a program do when memory allocation fails?" The answer turned out to be much more complex than anticipated. We had to go through exceptions, stack unwinding, error propagation, resource management, resource transfer, smart pointers, auto pointers, smart containers, auto iterators and a lot of really advanced features of C++. But once you've assimilated all the material presented in this chapter and used the techniques described in it, you will have graduated from the level of Weekend Programming to the new level of Industrial Strength Programming. Congratulations!