Making Use of the Standard Template Library
source
Programming in C++ is so much easier once you start using the Standard Library. If I were to start the whole calculator project from scratch, with the full use of the Standard Library, it would look a lot different. I didn't, though, for several reasons. First of all, the standard library is based on templates--especially the part called the Standard Template Library (STL) that contains all of the containers (most notably, vectors) and algorithms. So I had to explain first what templates were and what kind of problems they solved. Second of all, you wouldn't know how much work they could save you, unless you tried programming without them.
So what would the calculator look like if I had a free run of STL from the very beginning? First of all, I wouldn't bother implementing the hash table. No, there is no ready-made implementation of a hash table in STL--although many compiler vendors will undoubtedly add one to their version of the Standard Library. There is, however, another useful data structure that, although not as efficient as the hash table, fulfills the same role. I'm talking about an associative array, known in STL as std::map.
An associative array is like an array, except that it can be indexed using objects of a type that is not necessarily integral.
You know how to define an array of strings. You index it with an integer and it gives you a string. An associative array can do the inverse--you may index it, for instance, with a string and it could give you an integer. Like this:
int id = assoc ["foo"]; |
This looks very much like what we need in our symbol table. Given the name of an identifier, give me its integer id.
You can easily implement an associative array using the STL's map template. A map is parameterized by two types--the type used to index it, called the key; and the value type. There is only one requirement for the key type--there must be a way to compare keys. Actually, it's not necessary to provide a method to compare keys for (in-) equality. What is important for the map is to be able to tell if one key is less than the other. By default, a map expects the key type to either be directly comparable or have the less-than operator overload.
The naive, and for most purposes incorrect, approach to implementing an associative array of strings would be to use char const * as the key type, like this:
std::map<char const *, int> dictionary; |
The first problem is that there indeed is an operator less-than defined for this key type, but it's totally inappropriate. Consider this:
char const * str1 = "sin";
char const * str2 = "sin";
if (str1 < str2) // <- not what you'd expect!
cout << str1 << " is less than " << str2 << endl;
|
There is a version of the map that takes a third template argument--the predicate functor. A predicate is a function that responds with true or false to a particular question. In our case the question would be, "Is one string less than the other?" A functor is a class that defines a function-call operator. Here's an example of a functor class that's suitable for our purposes:
class LessThan
: public std::binary_function<char const *, char const *, bool>
{
public:
bool operator () (char const * str1,
char const * str2) const
{
return strcmp (str1, str2) < 0;
}
};
std::map<char const *, int, LessThan> dictionary;
|
Notice that the function strcmp returns a number less than zero when the first string precedes the second one lexicographically (i.e., it would precede it in a dictionary--let's forget for a moment about human-language-specific issues). Similarly, it returns a number greater than zero when the first string follows the other; and zero when they're equal.
The way you could use a functor object, other than passing it as a template argument to a map, would be to treat it just like a function (or function pointer).
char const * str1 = "cos";
char const * str2 = "sin";
LessThan lessThan;
if (lessThan (str1, str2))
cout << str1 << " is less than " << str2 << endl;
|
In fact, a functor is even more efficient than a function pointer, because it may be inlined. In the example above, the implicit call to lessThan.operator () will be inlined, according to its declaration in LessThan.
If you think this is too complicated--having to define a predicate functor to do such a simple thing as string comparison in a map--you're right! This is because we are trying to fit a square peg in a round hole. The equivalent of a square peg is the low level data structure that we are insisting on using to represent strings. The Standard Library has a perfectly round peg for this purpose--it's called a string.
And that brings us to the second problem with the naive implementation of the symbol table: the keys could disappear from under the map. When you enter a new association--a pair (key, value)--in the map, the map has to remember both the key and the value. If you use a pointer to character as a key, the map will store the pointer, but you'll have no idea where the actual characters are stored and for how long. Somebody could call the map with a character string that's allocated on the stack and which will disappear as soon as the caller returns. We want the map to own the keys! And no, we can't use auto_ptrs as keys. Standard library containers use value semantics for all its data--they get confused by objects that exhibit transfer semantics. And that's the second reason to use strings.
A standard string not only has value semantics, but it also comes with a lot of useful methods--one of them being operator less-than. As a matter of fact, string and map are a perfect match. Implementing an associative array of strings is a no-brainer. So let's do it first, and ask detailed questions later. Here's the declaration of the new symbol table:
#include <map>
#include <string>
class SymbolTable
{
public:
enum { idNotFound = -1 };
SymbolTable () : _id (0) {}
int ForceAdd (char const * str);
int Find (char const * str) const;
private:
std::map<std::string, int> _dictionary;
int _id;
};
|
Notice that we are still clinging to the old char const * C-style strings in the symbol table interface. That's because I want to show you how you can start converting old legacy code without having to rewrite everything all at once. The two representations of strings can co-exist quite peacefully. Of course, we'll have to make some conversions at the boundaries of the two worlds. For instance, the method ForceAdd starts by creating a standard string from the C-string argument. It then stores the corresponding integer id under this string in the associative array.
int SymbolTable::ForceAdd (char const * str)
{
std::string name (str);
_dictionary [name] = _id;
return _id++;
}
|
Here, the mere act of accessing a map using a key will create an entry, if one wasn't there.
| Don't get fooled by the syntactic simplicity of accessing a map. The time it takes to index an associative array that's implemented as a standard map is not constant, like it is with regular arrays or hash tables, but it depends on its size (number of elements). The good news is that it's not linear--the array is not searched element-by-element. The recommended implementation of an STL map is in terms of a balanced tree that can be searched in logarithmic time. Logarithmic access is pretty good for most applications. |
There is also a more explicit way of adding entries to a map by calling its insert method. You insert a pair (key, value) using a standard pair template. For instance, ForceAdd may be also implemented this way:
int SymbolTable::ForceAdd (char const * str)
{
std::string name (str);
std::pair<std::string, int> p (str, _id);
_dictionary.insert (p);
return _id++;
}
|
The Find method of the symbol table could be simply implemented by returning _dictionary [str], if it weren't for the fact that we sometimes want to know whether the name wasn't there. We have to use a more explicit approach.
int SymbolTable::Find (char const * str) const
{
std::map<std::string, int>::const_iterator it;
it = _dictionary.find (str);
if (it != _dictionary.end ())
return it->second;
return idNotFound;
}
|
The find method of map returns an iterator. This iterator could either point to the end of the dictionary, or to a pair (key, value). A pair has two public data members, first and second, with obvious meanings.
Notice also that I called find with a C-style string. It was possible, because the standard string has a constructor that accepts a C-string. This constructor can be used for implicit conversions.
We can use this property of strings to further simplify the implementation of the symbol table. We can change the signature of its methods to accept strings rather than C-strings.
int ForceAdd (std::string const & str); int Find (std::string const & str) const; |
This will work without any changes to the callers, because of the implicit conversions. The trick is that both methods take const references to strings. The compiler will have no trouble creating temporary strings at the point of call and passing out const references. This would not work, however, if symbol table methods required non-const references (we already talked about it, but this point is worth repeating--the compiler will refuse to create a non-const reference to a temporary object).
There is an interesting twist on this topic--we may pass strings by value.
int ForceAdd (std::string str); int Find (std::string str) const; |
This would work, because, as I mentioned, strings have value semantics. They behave as if every copy were a deep copy. However, since memory allocation and copying is rather expensive, a good implementation of a standard string uses all kinds of clever tricks to avoid, or at least postpone, these operations. Let's talk about this in some more detail.
Reference Counting and Copy-On-Write
source
Strings.
First, let's make sure we understand what is meant by value semantics as applied to strings. Here's a simple implementation of a value string. Notice the copy constructor and the assignment operator.
class StringVal
{
public:
StringVal (char const * cstr = 0)
:_buf (0)
{
if (cstr != 0)
Init (cstr);
}
StringVal (StringVal const & str)
:_buf (0)
{
if (str.c_str () != 0)
Init (str.c_str ());
}
~StringVal ()
{
delete _buf;
}
StringVal & operator= (StringVal const & str);
char const * c_str () const { return _buf; }
void Upcase ()
private:
void Init (char const * cstr)
{
assert (cstr != 0);
_buf = new char [strlen (cstr) + 1];
strcpy (_buf, cstr);
}
private:
char * _buf;
};
|
When overloading the assignment operator, we have to take care of a few special cases. For instance, we should do noting if the source is equal to the target, as in str = str. Then we have to be smart about null strings. Finally, we have to reallocate the buffer if there isn't enough space in it for the new string.
StringVal & StringVal::operator= (StringVal const & str)
{
if (this != & str)
{
char const * cstr = str.c_str ();
if (cstr == 0)
{
delete _buf;
_buf = 0;
}
else
{
int len = strlen (cstr);
if (_buf == 0 || strlen (_buf) < len)
{
delete _buf;
Init (cstr);
}
else
strcpy (_buf, cstr);
}
}
return *this;
}
|
I added the Upcase method to demonstrate what happens when a string is modified.
void StringVal::Upcase ()
{
if (_buf)
{
int len = strlen (_buf);
for (int i = 0; i < len; ++i)
_buf [i] = toupper (_buf [i]);
}
}
|
In particular, we can create two copies of the same string and, when we Upcase one of them, the other should remain unchanged.
StringVal str1 ("foo");
StringVal str2 (str1); // copy
str2.Upcase ();
cout << str1.c_str () << endl;
cout << str2.c_str () << endl;
|
Semantically, this is how we want our string to behave. Performance-wise, we might not be too happy with this implementation. Consider, as an exercise, how many memory allocations and string copies are made when, for instance, a StringVal is returned by value:
StringVal ByValue ()
{
StringVal ret ("foo");
return ret;
}
StringVal str;
str = ByValue ();
|
To save on allocating and copying, we might consider a scheme where multiple copies of the same string would internally share the same representation object--they'd have a pointer to the same buffer. But then the question of ownership arises. Who's supposed to delete the buffer? We have to somehow keep track of how many shared owners of the buffer there are at any point in time. Then, when the last owner disappears, we should delete the buffer.
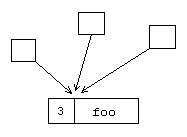
Multiple object sharing the same reference-counted representation.
The best way to implement it is to divide the responsibilities between two classes of objects. One class encapsulates the reference counted shared object--in our case this object will also hold the string buffer. The other class deals with the ownership issues--it increments and decrements the shared object's reference count--in our case this will be the "string" object. When it discovers that the reference count of the shared object has gone down to zero (nobody else references this object) it deletes it.
You might think of reference count as a type of resource--it is acquired by incrementing it and it must subsequently be released by decrementing it. Like any other resource, it has to be encapsulated. Our "string" object will be such an encapsulator. In fact, since reference count is a common type of resource, we will build the equivalent of a smart pointer to deal with reference counted objects.
template <class T>
class RefPtr
{
public:
RefPtr (RefPtr<T> const & p)
{
_p = p._p;
_p->IncRefCount ();
}
~RefPtr ()
{
Release ();
}
RefPtr const & operator= (RefPtr const & p)
{
if (this != &p)
{
Release ();
_p = p._p;
_p->IncRefCount ();
}
return *this;
}
protected:
RefPtr (T * p) : _p (p) {}
void Release ()
{
if (_p->DecRefCount () == 0)
delete _p;
}
T * _p;
};
|
Notice that the reference-counted type T must provide at least two methods, IncRefCount and DecRefCount. We also tacitly assume that it is created with a reference count of one, before being passed to the protected constructor of RefPtr.
Although it's not absolutely necessary, we might want the type T to be a descendant of a base class that implements reference counting interface.
class RefCounted
{
public:
RefCounted () : _count (1) {}
int GetRefCount () const { return _count; }
void IncRefCount () const { _count++; }
int DecRefCount () const { return --_count; }
private:
mutable int _count;
};
|
Notice one interesting detail, the methods IncRefCount and DecRefCount are declared const, even though they modify the object's data. You can do that, without the compiler raising an eyebrow, if you declare the relevant data member mutable. We do want these methods to be const (or at least one of them, IncRefCount) because they are called on const objects in RefPtr. Both the copy constructor and the assignment operator take const references to their arguments, but they modify their reference counts. We decided not to consider the updating of the reference count a "modification" of the object. It will make even more sense when we get to the copy-on-write implementation.
Just for the demonstration purposes, let's create a reference-counted string representation using our original StringVal. Normally, one would do it more efficiently, by combining the reference count with the string buffer.
class StringRep: public RefCounted
{
public:
StringRep (char const * cstr)
:_string (cstr)
{}
char const * c_str () const { return _string.c_str (); }
void Upcase ()
{
_string.Upcase ();
}
private:
StringVal _string;
};
|
Our actual string class is built on the base of RefPtr which internally represents string data with StringRep.
class StringRef: public RefPtr<StringRep>
{
public:
StringRef (char const * cstr)
: RefPtr<StringRep> (new StringRep (cstr))
{}
StringRef (StringRef const & str)
: RefPtr<StringRep> (str)
{}
char const * c_str () const { return _p->c_str (); }
void Upcase ()
{
_p->Upcase ();
}
};
|
Other than in the special C-string-taking constructor, there is no copying of data. The copy constructor just increments the reference count of the string-representation object. So does the (inherited) assignment operator. Consequently, "copying" and passing a StringRef by value is relatively cheap. There is only one tiny problem with this implementation. After you call Upcase on one of the copies of a StringRef, all other copies change to upper case.
StringRef strOriginal ("text");
StringRef strCopy (strOriginal);
strCopy.Upcase ();
// The original will be upper-cased!
cout << "The original: " << strOriginal.c_str () << endl;
|
There is, however, a way to have a cake and eat it, too. It's called copy-on-write, or COW for short. The idea is to share a single representation between multiple copies, as long as they don't want to make any modifications. Every modifying method would have to make sure that its modifications are not shared. It would check the reference count of its representation and, if it's greater than one, make a private copy. This way, the copying is delayed as long as possible. Passing by value is as cheap as in the case of shared representation, but modifications are no longer shared between copies.
class StringCow: public RefPtr<StringRep>
{
public:
StringCow (char const * cstr)
: RefPtr<StringRep> (new StringRep (cstr))
{}
StringCow (StringCow const & str)
: RefPtr<StringRep> (str)
{}
char const * c_str () const { return _p->c_str (); }
void Upcase ()
{
Cow ();
_p->Upcase ();
}
private:
void Cow ()
{
if (_p->GetRefCount () > 1)
{
// clone it
StringRep * rep = new StringRep (_p->c_str ());
Release ();
_p = rep;
}
}
};
|
The beauty of this implementation is that, from the point of view of the user, StringCow behaves exactly like StringVal, down to the const-reference-taking copy constructor and assignment operator. Except that, when it comes to passing around by value, its performance is superior.
There is a good chance that your standard library implements string using some version of copy-on-write.
End of Restrictions
Now that we are no longer scared of passing strings by value, we might try some more code improvements. For instance, we can replace this awkward piece of code:
int Scanner::GetSymbolName (char * strOut, int lenBuf)
{
assert (lenBuf > maxSymLen);
assert (_lenSymbol < lenBuf);
strncpy (strOut, &_buf [_iSymbol], _lenSymbol);
strOut [_lenSymbol] = 0;
return _lenSymbol;
}
|
When you use strings, you don't have to worry about sending in appropriately sized buffers. You let the callee create a string of the correct size and return it by value.
std::string Scanner::GetSymbolName ()
{
return std::string (&_buf [_iSymbol], _lenSymbol);
}
|
And that's what it looks like on the receiving side.
std::string strSymbol = _scanner.GetSymbolName (); int id = _symTab.Find (strSymbol); ... cerr << "Unknown function \""; cerr << strSymbol << "\"" << endl; |
By the way, as you can see, a string may be sent to the standard output (or standard error) and it will be printed just like a c-string. Actually, it gets even better than that. You can read text from the standard input directly into a string. The beauty of it is that, because a string can dynamically resize itself, there is practically no restriction on the size of acceptable text. The string will accommodate as much text as the user wishes to type into it. Of course, there has to be a way terminate the string. Normally, the standard input will stop filling a string once it encounters any whitespace character. That means you may read one word at a time with simple code like this:
std::string str; std::cin >> str; |
In our program, we have a slightly different requirement. We want to be able to read one line at a time. The standard library has an appropriate function to do that, so let's just use it directly in main.
cerr << "> "; // prompt
std::string str;
std::getline (cin, str);
Scanner scanner (str);
|
| Bug Alert! The standard library that comes with VC++ 6.0 has a bug that makes getline expect two newlines rather than one, as line terminator. A fix for this and many other bugs is available on the Internet at www.dinkumware.com. |
Let's stop here for a moment. We have just removed the last built-in limitation from our program. There is no longer any restriction on the length of the input line, or on the length of an identifier. The file params.h is gone!
How did that happen? Well, we started using dynamic data structures. Is our program more complex because of that? No, it's not! In fact it's simpler now. Is there any reason to introduce limitations into programs? Hardly!
Now let's follow the fate of the input string from main and into the scanner. It makes little sense to store a naked c-string in the scanner. So let's rewrite it to use a standard string instead.
class Scanner
{
public:
Scanner (std::string const & buf);
bool IsDone () const { return _iLook == std::string::npos; }
bool IsEmpty () const { return _buf.length () == 0; }
EToken Token () const { return _token; }
EToken Accept ();
std::string GetSymbolName ();
double Number ();
private:
void EatWhite ();
typedef std::string::size_type size_type;
std::string const & _buf;
size_type _iLook;
EToken _token;
double _number;
size_type _iSymbol;
size_type _lenSymbol;
static char _whiteChars [];
};
|
The natural way of marking the fact that we are beyond the end of string is to use a special index value, string::npos. This is the value that is returned by string's various "find" methods when end of string is reached. For instance, we can use one such method, find_first_not_of, to skip whitespace in our buffer.
char Scanner::_whiteChars [] = " \t\n\r";
void Scanner::EatWhite ()
{
_iLook = _buf.find_first_not_of (_whiteChars, _iLook);
}
|
The method find_first_not_of takes a null-terminated array of characters to be skipped (in our case the array contains a space, a tab, a newline and a carriage return) and the optional starting index which defaults to zero. It returns the index of the first occurrence of acharacterr that is not in the skip list. If no such character is found, it returns string::npos.
By the way, the value string::npos is guaranteed to be greater than any valid index, as long as you are comparing the same integral types. That's why we made sure we use the same type, size_type, for our index as the one used internally by the string itself.
GetSymbolName is returning a substring of the buffer.
std::string Scanner::GetSymbolName ()
{
return _buf.substr (_iSymbol, _lenSymbol);
}
|
An alternative would be to use the string constructor that takes the source string, the starting offset and the length.
The rest of the implementation of the scanner works with almost no change. We only have to make sure that, at the end of Accept, we set the position to string::npos after the buffer has been consumed.
if (_iLook == _buf.length ())
_iLook = std::string::npos;
|
In particular, code like this, although not the most elegant, will work with strings as well as it used to work with straight character arrays:
char * p; _number = strtod (&_buf [_iLook], &p); _iLook = p - &_buf [0]; |
This is not the preferred way of writing a program, if you've decided to use the standard library from the onset of the project. But I wanted to show you that it's quite possible to start the conversion in a legacy program and not have to go all the way at once.
Exploring Streams
source
So what is the preferred way; if we really wanted to use the standard library to its full advantage? I guess we wouldn't bother reading the line from the standard input into a string. We would just pass the stream directly to the scanner. After all, we don't need random access to the input line--we are parsing it more or less one character at a time. Except in rare cases, we don't have to go back in the string to re-parse it (there are some grammars that require it--ours doesn't). And when we do, it's only by one character.
Let's start from the top. We can create the scanner, passing it the standard input stream as an argument. By the way, the type of cin is std::istream.
cerr << "> "; // prompt Scanner scanner (cin); |
Here's the new definition of the Scanner class.
class Scanner
{
public:
explicit Scanner (std::istream & in);
bool IsDone () const { return _token == tEnd; }
bool IsEmpty () const { return _isEmpty; }
EToken Token () const { return _token; }
void Accept ();
std::string GetSymbolName ();
double Number ();
private:
void ReadChar ();
std::istream & _in;
int _look; // lookahead character
bool _isEmpty;
EToken _token;
double _number;
std::string _symbol;
};
|
I did a little reorganizing here. I'm keeping a lookahead character in _look. I also decided to have a Boolean flag _isEmpty, to keep around the information that the stream was empty when the scanner was constructed (I can no longer look back at the beginning of input, once Accept has been called). I changed the test for IsDone to simply compare the current token with tEnd. Finally, I needed a string to keep the name of the last symbolic variable read from the input.
Here's the constructor of the Scanner:
Scanner::Scanner (std::istream & in)
: _in (in)
{
Accept ();
_isEmpty = (Token () == tEnd);
}
|
The Accept method needs a little rewriting. Where we used to call EatWhite (), we now call ReadChar (). It skips whitespace as before, but it also initializes the lookahead character to the first non-white character. Since the lookahead has been consumed from the input stream, we don't have to do any incrementing after we've recognized it in Accept.
void Scanner::Accept ()
{
ReadChar ();
switch (_look)
{
case '+':
_token = tPlus;
// no incrementing
break;
...
}
}
|
This is the implementation of ReadChar:
void Scanner::ReadChar ()
{
_look = _in.get ();
while (_look == ' ' || _look == '\t')
_look = _in.get ();
}
|
I had to rethink the handling of the end of input. Before, when we used getline to read input, we actually never had to deal with a newline. By definition, getline eats the newline and terminates the string appropriately (i.e., the c-string version appends a null, the std::string version updates the internal length). The get method, on the other hand, reads every character as is, including the newline. So I let the scanner recognize a newline as the end of input.
case '\n': // end of input
case '\r':
case EOF: // end of file
_token = tEnd;
break;
|
Incidentally, I did some thinking ahead and decided to let the scanner recognize the end of file. The special EOF value is returned by the get () method when it encounters the end of file. This value is not even a character (that's why get is defined to return an int, rather than char).
How can a standard input stream encounter an end of file? There's actually more than one way it may happen. First, you may enter it from the keyboard--in DOS it's the combination Ctrl-Z. Second, the program might be called from the command line with redirected input. You may create a text file, say calc.txt, filled with commands for the calculator and then call it like this:
calc < calc.txt |
The operating system will plug the contents of this file into the program's standard input and execute it. You'll see the results of calculations flashing on your standard output. That is unless you redirect it too, like this:
calc < calc.txt > results.txt |
Let's continue with our rewrite of the scanner. Here's what we do when we recognize a number:
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
case '.':
{
_token = tNumber;
_in.putback (_look);
_in >> _number; // read the whole number
break;
}
|
Reading a floating-point number from the standard input is easy. The only complication arises from the fact that we've already read the first character of the number--our lookahead. So before we read the whole number, we have to put our lookahead back into the stream. Don't worry, this is a simple operation. After all, the input stream is buffered. When you call get, the character is simply read from a buffer (unless the buffer is empty--in that case the system replenishis it by actually reading the input). Ungetting a character just means putting it back into that buffer. Input streams are implemented in such a way that it's always possible to put back one character.
When reading an identifier, we do a slight variation of the same trick.
default:
if (isalpha (_look) || _look == '_')
{
_token = tIdent;
_symbol.erase (); // erase string contents
do {
_symbol += _look;
_look = _in.get ();
} while (isalnum (_look));
_in.putback (_look);
}
else
_token = tError;
break;
|
We don't have to putback a lookahead at the beginning of reading an identifier. Instead, we have to putback the last character, the one that is not part of the identifier, so that the next call to ReadChar () can see it.
Haven't we lost some generality by switching from a string to a stream in our implementation of the scanner? After all, you can always convert a stream to a string (e.g., using getline ()). Is the opposite possible? Not to worry! Converting a string into a stream is as easy. The appropriate class is called istringstream and is defined in the header <sstream>. Since istringstream inherits from istream, our scanner won't notice the difference. For instance, we can do this:
std::istringstream in ("sin (2 * pi / 3)");
Scanner scanner (in);
|
We have just skimmed the surface of the standard library and we've already found a lot of useful stuff. It really pays to study it, rather than implement your own solutions from scratch.