Transactions
Imagine using a word processor. You are editing a large document and, after working on it for several hours, you decide to save your work. Unfortunately, there is not enough disk space on your current drive and the save fails. What do you expect to happen?
Option number one is: the program gives up and exits. You are horrified--you have just lost many hours of work. You try to start the word processor again and you have a heart attack--the document is corrupted beyond recovery. Not only have you lost all recent updates, but you lost the original as well.
If horrors like this don't happen, it is because of transactions. A transaction is a series of operations that move the program from one well defined state to another. A transaction must be implemented in such a way that it either completely succeeds or totally fails. If it fails, the program must return to its original state.
In any professionally written word processor, saving a document is a transaction. If the save succeeds, the on-disk image of the document (the file) is updated with the current version of the document and all the internal data structures reflect this fact. If the save fails, for whatever reason, the on-disk image of the documents remains unchanged and all the internal data structures reflect that fact. A transaction cannot succeed half-way. If it did, it would leave the program and the file in an inconsistent, corrupted, state.
Let's consider one more word-processing scenario. You are in the middle of editing a document when suddenly all lights go out. Your computer doesn't have a UPS (Uninterrupted Power Supply) so it goes down, too. Five minutes later, the electricity is back and the computer reboots. What do you expect to happen?
The nightmare scenario is that the whole file system is corrupt and you have to reformat your disk. Of course, your document is lost forever. Unfortunately, this is a real possibility with some file systems. Most modern file systems, however, are able to limit the damage to a single directory. If this is not good enough for you (and I don't expect it is), you should look for a recoverable file system. Such systems can limit the damage down to the contents of the files that had been open during the crash. It does it by performing transactions whenever it updates the file system metadata (e.g., directory entries). Asking anything more from a file system (e.g., transacting all writes) would be impractical--it would slow down the system to a crawl.
Supposing you have a recoverable file system, you should be able to recover the last successfully saved pre-crash version of your document. But what if the crash happened during the save operation? Well, if the save was implemented as a transaction it is guaranteed to leave the persistent data in a consistent state--the file should either contain the complete previously saved version or the complete new version.
Of course, you can't expect to recover the data structures that were stored in the volatile memory of your computer prior to the crash. That data is lost forever. (It's important to use the auto-save feature of your word processor to limit such losses). That doesn't mean that you can't or shouldn't transact operations that deal solely with volatile data structures. In fact, every robust program must use transactions if it is to continue after errors or exceptions.
What operations require transactions?
Any failure-prone action that involves updating multiple data structures might require a transaction.
Transient Transactions
A transient, or in-memory, transaction does not involve any changes to the persistent (usually on-disk) state of the program. Therefore a transient transaction is not robust in the face of system crashes or power failures.
We have already seen examples of such transactions when we were discussing resource management. A construction of a well implemented complex data structure is a transaction--it either succeeds or fails. If the constructor of any of the sub-objects fails and throws an exception, the construction of the whole data structure is reversed and the program goes back to the pre-construction state (provided all the destructors undo whatever the corresponding constructors did). That's just one more bonus you get from using resource management techniques.
There are however cases when you have to do something special in order to transact an operation. Let's go back to our word processor example. (By the way, the same ideas can be applied to the design of an editor; and what programmer didn't, at one time or another, try to write his or her own editor.) Suppose that we keep text in the form of a list of paragraphs. When the user hits return in the middle of a paragraph, we have to split this paragraph into two new ones. This operation involves several steps that have to be done in certain order:
- Allocate one new paragraph.
- Allocate another new paragraph.
- Copy the first part of the old paragraph into the first new paragraph.
- Copy the second part of the old paragraph into the second new paragraph.
- Plug the two new paragraphs in the place of the old one.
- Delete the old paragraph.
The switch--when you plug in the new paragraphs--is the most sensitive part of the whole operation. It is performed on some master data structure that glues all paragraphs into one continuous body of the document. It is also most likely a dynamic data structure whose modifications might fail--the computer might run out of memory while allocating an extension table or a link in a list. Once the master data structure is updated, the whole operation has been successful. In the language of transactions we say "the transaction has committed." But if the crucial update fails, the transaction aborts and we have to unroll it. That means we have to get the program back to its original state (which also means that we refuse to split the paragraph).
What's important about designing a transaction is to make sure that
- All operations that proceed the commit are undoable in a safe manner (although the operations themselves don't have to--and usually aren't--safe).
- The commit operation is safe.
- All operations that follow it are also safe.
Operations that involve memory allocation are not safe--they may fail, e.g., by throwing an exception. In our case, it's the allocation of new paragraphs that's unsafe. The undo operation, on the other hand, is the deletion of these paragraphs. We assume that deletion is safe--it can't fail. So it is indeed okay to do paragraph allocation before the commit.
The commit operation, in our case, is the act of plugging in new paragraphs in the place of the old paragraph. It is most likely implemented as a series of pointer updates. Pointer assignment is a safe operation.
The post-commit cleanup involves a deletion, which is a safe operation. Notice that, as always, we assume that destructors never throw any exceptions.
The best way to implement a transaction is to create a transaction object. Such an object can be in one of two states: committed or aborted. It always starts in the aborted state. If its destructor is called before the state is changed to committed, it will unroll all the actions performed under the transaction. Obviously then, the transaction object has to keep track of what's already been done--it keeps the log of actions. Once the transaction is committed, the object changes its state to committed and its destructor doesn't unroll anything.
Here's how one could implement the transaction of splitting the current paragraph.
void Document::SplitCurPara ()
{
Transaction xact;
Paragraph * para1 = new Paragraph (_curOff);
xact.LogFirst (para1);
Paragraph * para2 = new Paragraph (_curPara-->Size () - _curOff);
xact.LogSecond (para2);
Paragraph * oldPara = _curPara;
// May throw an exception!
SubstCurPara (para1, para2);
xact.Commit ();
delete oldPara;
// destructor of xact executed
}
|
This is how the transaction object is implemented.
class Transaction
{
public:
Transaction () : _commit (false), _para1 (0), _para2 (0) {}
~Transaction ()
{
if (!_commit)
{
// unroll all the actions
delete _para2;
delete _para1;
}
}
void LogFirst (Paragraph * para) { _para1 = para; }
void LogSecond (Paragraph * para) { _para2 = para; }
void Commit () { _commit = true; }
private:
bool _commit;
Paragraph * _para1;
Paragraph * _para2;
};
|
Notice how carefully we prepare all the ingredients for the transaction. We first allocate all the resources and log them in our transaction object. The new paragraphs are now owned by the transaction. If at any point an exception is thrown, the destructor of the Transaction, still in its non-committed state, will perform a rollback and free all these resources.
Once we have all the resources ready, we make the switch--new resources go into the place of the old ones. The switch operation usually involves the manipulation of some pointers or array indexes. Once the switch has been done, we can commit the transaction. From that point on, the transaction no longer owns the new paragraphs. The destructor of a committed transaction usually does nothing at all. The switch made the document the owner of the new paragraphs and, at the same time, freed the ownership of the old paragraph which we then promptly delete. All simple transactions follow this pattern:
- Allocate and log all the resources necessary for the transaction.
- Switch new resources in the place of old resources and commit.
- Clean up old resources.
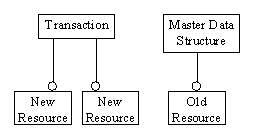
Figure: Prepared transaction. The transaction owns all the new resources. The master data structure owns the old resources.
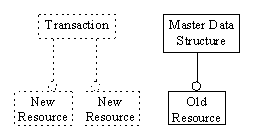
Figure: Aborting a transaction. The transaction's destructor frees the resources.
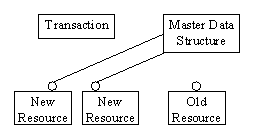
Figure 3--11 The switch. The master data structure releases the old resources and takes the ownership of the new resources.
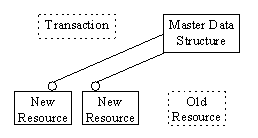
Figure 3--12 The cleanup. Old resources are freed and the transaction is deleted.
Persistent Transactions
When designing a persistent transaction--one that manipulates persistent data structures--we have to think of recovering from such disasters as system crashes or power failures. In cases like those, we are not so much worried about in-memory data structures (these will be lost anyway), but about the persistent, on-disk, data structures.
A persistent transaction goes through similar stages as the transient one.
- Preparation: New information is written to disk.
- Commitment: The new information becomes current, the old is disregarded.
- Cleanup: The old information is removed from disk.
A system crash can happen before or after commitmentment (I'll explain in a moment why it can't happen during the commit). When the system comes up again, we have to find all the interrupted transactions (they have to leave some trace on disk) and do one of two things: if the transaction was interrupted before it had a chance to commit, we must unroll it; otherwise we have to complete it. Both cases involve cleanup of some on-disk data. The unrolling means deleting the information written in preparation for the transaction. The completing means deleting the old information that is no longer needed.
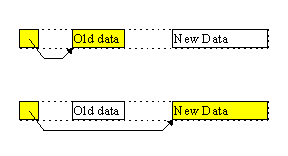
Figure: The Switch. In one atomic write the on-disk data structure changes its contents.
The crucial part of the transaction is, of course, commitmentment. It's the "flipping of the switch." In one atomic operation the new information becomes current and the old becomes invalid. An atomic operation either succeeds and leaves a permanent trace on disk, or fails without leaving a trace. That shouldn't be difficult, you'd say. How about simply writing something to a file? It either succeeds or fails, doesn't it?
Well, there's the rub! It doesn't! In order to understand that, we have to delve a little into the internals of a file system. First of all, writing into a file doesn't mean writing to disk. Or, at least, not immediately. In general, file writes are buffered and then cached in memory before they are physically written to disk. All this is quietly done by the runtime (the buffering) and by the operating system (the caching) in order to get reasonable performance out of your machine. Disk writes are so incredibly slow in comparison with memory writes that caching is a must.
What's even more important: the order of physical disk writes is not guaranteed to follow the order of logical file writes. In fact the file system goes out of its way to combine writes based on their physical proximity on disk, so that the magnetic head doesn't have to move too much. And the physical layout of a file might have nothing to do with its contiguous logical shape. Not to mention writes to different files that can be quite arbitrarily reordered by the system, no matter what your program thinks.
Thirdly, contiguous writes to a single file may be split into several physical writes depending on the disk layout set up by your file system. You might be writing a single 32-bit number but, if it happens to straddle sector boundaries, one part of it might be written to disk in one write and the other might wait for another sweep of the cache. Of course, if the system goes down between these two writes, your data will end up partially written. So much for atomic writes.
Now that I have convinced you that transactions are impossible, let me explain a few tricks of trade that make them possible after all. First of all, there is a file system call, Flush, that makes 100% sure that the file data is written to the disk. Not atomically, mind you--Flush may fail in the middle of writing a 32--bit number. But once Flush succeeds, we are guaranteed that the data is safely stored on disk. Obviously, we have to flush the new data to disk before we go about committing a transaction. Otherwise we might wake up after a system crash with a committed transaction but incomplete data structure. And, of course, another flush must finish the committing a transaction.
How about atomicity? How can we atomically flip the switch? Some databases go so far as to install their own file systems that support atomic writes. We won't go that far. We will assume that if a file is small enough, the writes are indeed atomic. "Small enough" means not larger than a sector. To be on the safe side, make it less than 256 bytes. Will this work on every file system? Of course, not! There are some file systems that are not even recoverable. All I can say is that this method will work on NTFS--the Windows NT(tm) file system. You can quote me on this.
We are now ready to talk about the simplest implementation of the persistent transaction--the three file scheme.
The Three-File Scheme
An idealized word processor reads an input file, lets the user edit it and then saves the result. It's the save operation that we are interested in. If we start overwriting the source file, we're asking for trouble. Any kind of failure and we end up with a partially updated (read: corrupted!) file.
So here's another scheme: Write the complete updated version of the document into a separate file. When you are done writing, flush it to make sure the data gets to disk. Then commit the transaction and clean up the original file. To keep permanent record of the state of the transaction we'll need one more small file. The transaction is committed by making one atomic write into that file.
So here is the three-file scheme: We start with file A containing the original data, file B with no data and a small 1-byte file S (for Switch) initializedcontaintain a zero. The transaction begins.
- Write the new version of the document into file B.
- Flush file B to make sure that the data gets to disk.
- Commit: Write 1 into file S and flush it.
- Empty file A.
The meaning of the number stored in file S is the following: If its value is zero, file A contains valid data. If it's one, file B contains valid data. When the program starts up, it checks the value stored in S, loads the data from the appropriate file and empties the other file. That's it!
Let's now analyze what happens if there is a system crash at any point in our scheme. If it happens before the new value in file S gets to the disk, the program will come up and read zero from S. It will assume that the correct version of the data is still in file A and it will empty file B. We are back to the pre-transaction state. The emptying of B is our rollback.
Once the value 1 in S gets to the disk, the transaction is committed. A system crash after that will result in the program coming back, reading the value 1 from S and assuming that the correct data is in file B. It will empty file A, thus completing the transaction. Notice that data in file B is guaranteed to be complete at that point: Since the value in S is one, file B must have been flushed successfully.
If we want to start another save transaction after that, we can simply interchange the roles of files A and B and commit by changing the value in S from one to zero. To make the scheme even more robust, we can choose some random (but fixed) byte values for our switch, instead of zero and one. In this way we'll be more likely to discover on-disk data corruption--something that might always happen as long as disks are not 100% reliable and other applications can access our files and corrupt them. Redundancy provides the first line of defense against data corruption.
This is how one might implement a save transaction.
class SaveTrans
{
enum State
{
// some arbitrary bit patterns
stDataInA = 0xC6,
stDataInB = 0x3A
};
public:
SaveTrans ()
: _switch ("Switch"), _commit (false)
{
_state = _switch.ReadByte ();
if (_state != stDataInA && state != stDataInB)
throw "Switch file corrupted";
if (_state == stDataInA)
{
_data.Open ("A");
_backup.Open ("B");
}
else
{
_data.Open ("B");
_backup.Open ("A");
}
}
File & GetDataFile () { return _data; }
File & GetBackupFile () { return _backup; }
~SaveTrans ()
{
if (_commit)
_data.Empty ();
else
_backup.Empty ();
}
void Commit ()
{
State otherState;
if (_state == stDataInA)
otherState = stDataInB;
else
otherState = stDataInA;
_backup.Flush ();
_switch.Rewind ();
_switch.WriteByte (otherState);
_switch.Flush ();
_commit = true;
}
private:
bool _commit;
File _switch;
File _data;
File _backup;
State _state;
};
|
This is how this transaction might be used in the process of saving a document.
void Document::Save ()
{
SaveTrans xact;
File &file = xact.GetBackupFile ();
WriteData (file);
xact.Commit ();
}
|
And this is how it can be used in the program initialization.
Document::Document ()
{
SaveTrans xact;
File &file = xact.GetDataFile ();
ReadData (file);
// Don't commit!
// the destructor will do the cleanup
}
|
The same transaction is used here for cleanup. Since we are not calling Commit, the transaction cleans up, which is exactly what we need.
The Mapping-File Scheme
You might be a little concerned about the performance characteristics of the three-file scheme. After all, the document might be a few megabytes long and writing it (and flushing!) to disk every time you do a save creates a serious overhead. So, if you want to be a notch better than most word processors, consider a more efficient scheme.
The fact is that most of the time the changes you make to a document between saves are localized in just a few places . Wouldn't it be more efficient to update only those places in the file instead of rewriting the whole document? Suppose we divide the document into "chunks" that fit each into a single "page." By "page" I mean a power-of-two fixed size subdivision. When updating a given chunk we could simply swap a page or two. It's just like swapping a few tiles in a bathroom floor--you don't need to re-tile the whole floor when you just want to make a small change around the sink.
Strictly speaking we don't even need fixed size power-of-two pages, it just makes the flushes more efficient and the bookkeeping easier. All pages may be kept in a single file, but we need a separate "map" that establishes the order in which they appear in the document. Now, if only the "map" could fit into a small switch file, we would perform transactions by updating the map.
Suppose, for example, that we want to update page two out of a ten-page file. First we try to find a free page in the file (we'll see in a moment how transactions produce free pages). If a free page cannot be found, we just extend the file by adding the eleventh page. Then we write the new updated data into this free page. We now have the current version of a part of the document in page two and the new version of the same part in page eleven (or whatever free page we used). Now we atomically overwrite the map, making page two free and page eleven take its place.
What if the map doesn't fit into a small file? No problem! We can always do the three-file trick with the map file. We can prepare a new version of the map file, flush it and commit by updating the switch file.
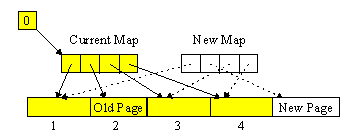
Figure: The Mapping File Scheme: Before committing.
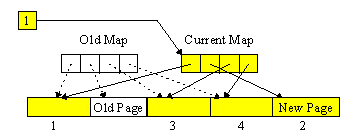
Figure: The Mapping File Scheme: After committing.
This scheme can be extended to a multi-level tree. In fact several databases and even file systems use something similar, based on a data structure called a B-tree.