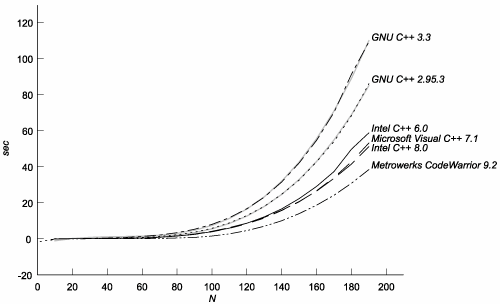
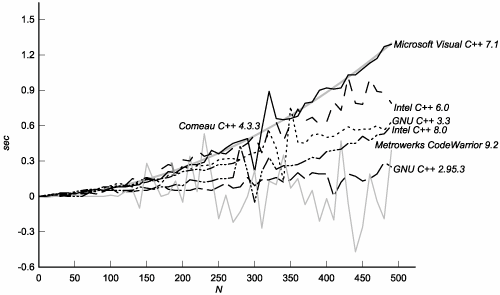
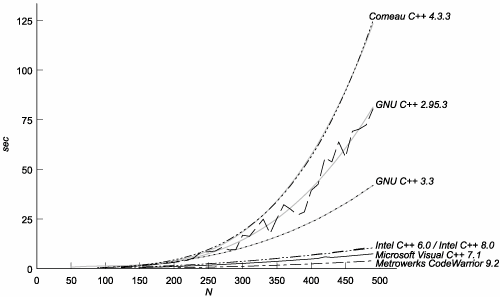
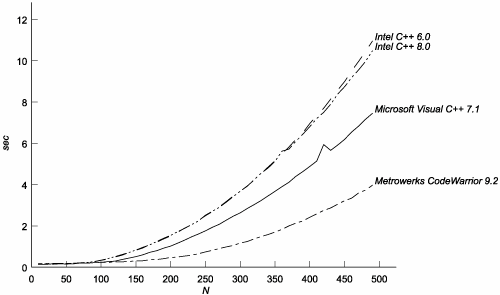
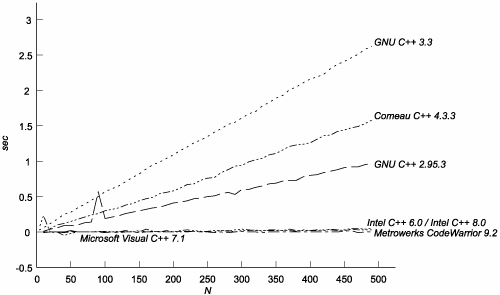
C.3. The TestsC.3.1. Effectiveness of MemoizationAre template instantiations really being memoized? If they are, how much does memoization save? To find out, we can make some minor changes to the fibonacci template:[3]
template<unsigned n, unsigned m = n, bool done = (n < 2)>
struct fibonacci
{
static unsigned const v1
= fibonacci<n-1,m-1>::value;
static unsigned const value
= v1 + fibonacci<n-2,m-STEP>::value;
};
template<unsigned n, unsigned m>
struct fibonacci<n,m,true>
{
static unsigned const value = n;
};
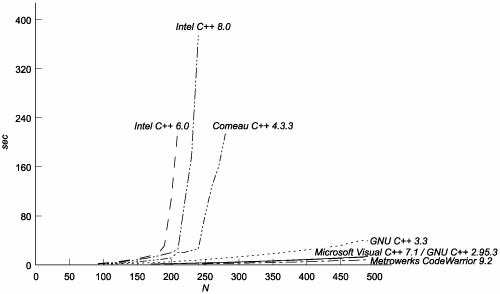
When STEP == 2, invoking fibonacci<N> causes the same number of template instantiations as ever. With STEP == 1, though, we ensure that the computation of fibonacci<N-2,...>::value never invokes fibonacci with an argument set that's been used before. The new parameter, m, provides an "additional dimension" for fibonacci specializations, which we exploit to escape memoization. By subtracting the time it takes to compute fibonacci<N>::value with STEP == 2 from the time it takes with STEP == 1, we can see the savings provided by memoization for increasing values of N (see Figure C.1). Figure C.1. Performance Savings Due to Memoization
The difference in cost between the two computations rises as N3 for all compilers tested, so memoization is indeed a big win. C.3.2. Cost of Memoized LookupsWhat's the cost of looking up a previously mentioned template specialization? To measure that, we can use yet another variation on the Fibonacci test:
template<unsigned n, bool done = (n < 2)>
struct lookup
{
static unsigned const v1
= lookup<n-1>::value;
static unsigned const value = v1
#ifndef BASELINE // do memoized lookup
+ lookup<((n%2) ? 0 : n-2)>::value
#endif
;
};
template<unsigned n>
struct lookup<n,true>
{
static unsigned const value = n;
};
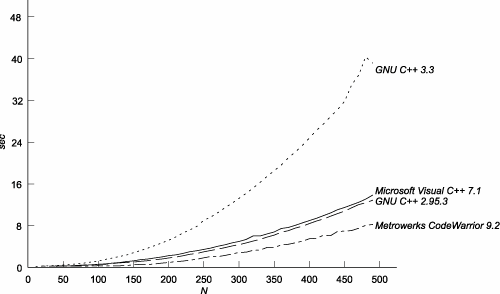
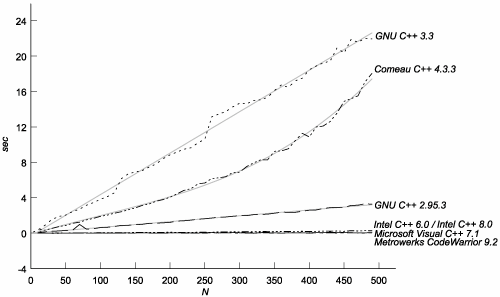
The difference between the costs of computing lookup<N>::value with and without BASELINE defined shows the cost of a memoized lookup when N specializations of the template have already been mentioned. Note that this isn't a Fibonacci computation anymore, though it follows the same instantiation/lookup pattern. We're choosing lookup<0> instead of lookup<n-2> for the memoized lookup half the time, because specializations tend to be stored in linked lists. A compiler that starts looking from the end where the most recently mentioned specializations are stored will always have an advantage with a strict Fibonacci computation. Figure C.2 shows the results. Figure C.2. Cost of Lookups versus Specializations of a Given Template
The first thing to notice is that the numbers are relatively small for all compilers. The time is bounded by that of Microsoft Visual C++ 7.1, which goes as N2just what you'd expect if all specializations of a given template were stored in a single linked list. We have no explanation for the erratic performance of Metrowerks' lookups, but we can say that it is at least averaging somewhere near zero cost per memoized lookup. C.3.3. Mentioning a SpecializationOnce a trivial class template specialization has been mentioned, instantiating it seems to have no cost. For instance:
template <class T> struct trivial { typedef T type; };
typedef mpl::vector<trivial<int> > v; // just a "mention"
trivial<int>::type x; // cost-free instantiation
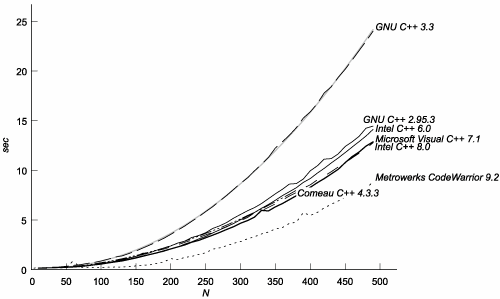
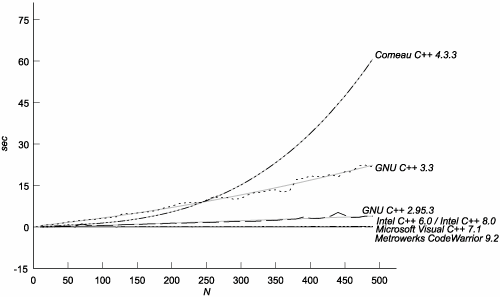
This result may surprise you, considering that we are measuring efficiency in terms of template instantiationsit certainly surprised us at firstbut we think we now understand the reasons for it. As you know, trivial<int> is a perfectly legitimate type even before it is instantiated. Compilers need some unique identifier for that type so that, for example, they can recognize that two occurrences of mpl::vector<trivial<int> > are also the same type. They could identify trivial<int> by its human-readable name, but as types get more complicated, matching long names becomes more costly. We believe that most C++ compilers allocate a "memoization record" at the first mention of a template specialization, and leave it in an "empty" state until the moment the specialization is instantiated. The address of a specialization's memoization record can then be used as a unique identifier. The simpler a class template's definition, the closer its memoization record's "empty" and "full" states are to one another, and the less time is taken by instantiation. You may be asking yourself whether it really makes sense to measure metaprogram efficiency by counting template instantiations, if some instantiations are effectively instantaneous. The answer is yes; it does. Because there is no looping, a metafunction's implementation can only directly mention a constant number of template specializations. What you see is what you getthat is, until the metafunction instantiates one of those templates it mentions. Thus, each metafunction invocation can only directly create a constant number of new memoization records. The only way to "escape" this constant-factor limitation is for the metafunction to instantiate another template. The graph in Figure C.3 shows the cost of simply mentioning, but not instantiating, N distinct specializations of the same template. As you can see, there's quite a spread. The complexity for Comeau and both GCCs is O(N3). Figure C.3. Cost of Mentioning N Specializations of the Same Template
By eliminating the O(N3) curves from the graph, (see Figure C.4), we can see that the cost of mentioning N specializations of the same template on the other compilers is O(N2). Figure C.4. Cost of Mentioning N Specializations of the Same Template
C.3.4. Nested Template InstantiationsNested template instantiations are the bread-and-butter of compile time programming. Even if you can avoid seeing the recursion by using MPL's algorithms, it's there under the covers. To test the effect of doing recursive template instantiations, we compiled this simple program for increasing values of N:
template< int i, int test > struct deep
: deep<i-1,test>
{};
template< int test> struct deep<0,test>
{
enum { value = 0 };
};
template< int n > struct test
{
enum { value = deep<N,n>::value };
};
int main()
{
return test<0>::value + test<1>::value + test<2>::value
+ test<3>::value + test<4>::value + test<5>::value
+ test<6>::value + test<7>::value + test<8>::value
+ test<9>::value;
}
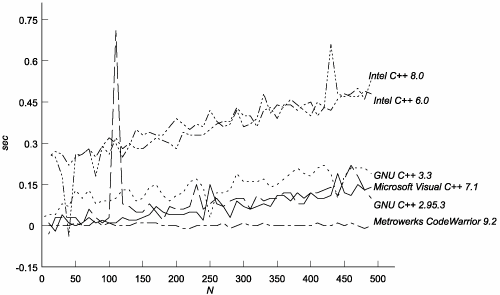
As you can see in Figure C.5, for low values of N, all the compilers behave similarly, but when N reaches 100 or so, the EDG-based compilers begin to spend seconds more, and somewhere around 200 their compilation times simply "explode." Figure C.5. Time versus Nesting Depth
If we remove the EDG-based compilers from the graph (see Figure C.6), we can see the behavior of the others, all of which exhibit O(N2) complexity. Figure C.6. Time versus Nesting Depth
C.3.4.1 Nested Instantiations Without ForwardingThe following version of the deep template, which restates its ::value at each level rather than inheriting it, reveals that the explosion is triggered by deeply nested metafunction forwarding:
template< int i, int test > struct deep
{
enum { value = deep<i-1,test>::value }; // no forwarding
};
template< int test> struct deep<0,test>
{
enum { value = 0 };
};
As you can see in Figure C.7, EDG's pathological behavior is gone; its times are clustered with most of the other compilers. GNU C++ (GCC) 3.3 also improved its performance somewhat, but its big-O behavior didn't change. It is still O(N2) like the rest. Figure C.7. Time versus Nesting Depth (Without Forwarding)
Metafunction forwarding is so valuable for simplifying programs that we're reluctant to recommend against it, even for EDG users. As far as we know, we've never hit "the EDG wall" in real code;[4] in fact, we only discovered it by writing test cases for this book. That said, if you find your metaprogram is slower to execute on EDG-based compilers than on others, you might want to review it for cases of deep forwarding.
C.3.4.2 Using Recursion Unrolling to Limit Nesting DepthEven O(N2) behavior is really unattractive for what should be an O(N) operation. While we can't go in and fix the compiler implementation, we can reduce the depth of nested instantiations. Since the time goes as the square of the depth, a factor of two reduction in depth is worth a factor of four in time, and a factor of four reduction in depth will make a recursive metafunction sixteen times as fast, and so on. Furthermore, when a compiler has a pathological behavior like the "EDG wall," or simply a hardcoded depth limit (as some do), reducing the depth can make the difference between throwing in the towel and having a productive day at the office. Consider this implementation of the guts of mpl::find:
namespace boost { namespace mpl {
template <class First, class Last, class T>
struct find_impl;
// find_impl on the tail of the sequence
template <class First, class Last, class T>
struct find_impl_tail
: find_impl<
typename next<First>::type
, Last
, T
>
{};
// true if First points at T
template <class First, class T>
struct deref_is_same
: is_same<typename deref<First>::type,T>
{};
template <class First, class Last, class T>
struct find_impl
: eval_if<
deref_is_same<First,T> // found?
, identity<First>
, find_impl_tail<First,Last,T> // search on the tail
>
{};
// terminating case
template <class Last, class T>
struct find_impl<Last, Last, T>
{
typedef typename Last type;
};
}}
Right now, find_impl incurs one level of recursion for each element of the sequence it traverses. Now let's rewrite it using recursion unrolling:
// a single step of the find algorithm
template <
class First, class Last, class T
, class EvalIfUnmatched = next<First>
>
struct find_step
: eval_if<
or_<
is_same<First,Last> // sequence empty
, deref_is_same<First,T> // or T is found
>
, identity<First>
, EvalIfUnmatched
>
{};
template <class First, class Last, class T>
struct find_impl
{
typedef typename find_step<First,Last,T>::type step1;
typedef typename find_step<step1,Last,T>::type step2;
typedef typename find_step<step2,Last,T>::type step3;
typedef typename find_step<
step3,Last,T, find_impl_tail<step3,Last,T>
>::type type;
};
Now each invocation of find_impl does up to four steps of the algorithm, reducing instantiation depth by a factor of four. When the sequence being searched supports random access, it's possible to make this idiom even more efficient by specializing the algorithm for lengths less than the unrolling factor, thereby avoiding iterator identity checks at each step. The MPL's algorithms use these techniques whenever appropriate to the target compiler. C.3.5. Number of Partial SpecializationsThe graph in Figure C.8 shows the effect of increasing numbers of partial specializations on the time it takes to instantiate a class template. Figure C.8. Instantiation Time versus Number of Partial Specializations
Comeau C++ is omitted from this graph because it was pathologically slow, even at N == 0, for reasons seemingly unrelated to partial specialization. Most other compilers show some effect, but such a small one that you can safely ignore it. C.3.6. Long SymbolsSymbol name length seems to have no effect on compilation time.[5] For example, all other things being equal, instantiating either of these two templates incurs the same cost:
wee<int>
a_ridiculously_loooooooooooooooooong_class_template_name<int>
Also, passing long symbol names to templates has no measurable effect on compilation time, so these two are equally expensive to instantiate:
mpl::vector<a_ridiculously_loooooooooooooooooong_class_name>
mpl::vector<int>
C.3.7. Structural Complexity of Metafunction ArgumentsWe considered three ways of describing the complexity of template specializations that might be passed as metafunction arguments.
For instance, mpl::vector30 has arity 30, and we're interested in the cost of passing templates with high arities to a metafunction. For another example, if you think of every unique template specialization as being a "node," the following "list" type has four nodes and a depth of four:
node<int, node<long, node<char, node<void, void> > > >
while this "DAG" type has four nodes and a depth of three:
// 1 2 3 <== Depths Nodes
node< // #1
node< // #2
node<void,void> // #3
, node<int,void> // #4
>
, node<void, void> // #3 again
>
C.3.7.1 Structural Complexity TestsWe measured the cost of passing various kinds of complex structures through a chain of recursive metafunction invocations, over and above the cost of passing a simple type like int. As you can see in Figure C.9, there is no cost associated with argument arity except on GCC and Comeau, where the cost rises linearly with N.[6]
Figure C.9. Recursive Instantiation Time versus Argument Arity
We then passed a balanced binary tree of N unique nodes (and depth log2N). The results in Figure C.10 show quite a spread: Comeau takes O(N2) time, the GCCs are linear with the modern version doing much worse than 2.95.3, and the rest show no cost at all.[7]
Figure C.10. Recursive Instantiation Time versus Number of Argument Tree Nodes
Finally, passing a list of N unique nodes with depth N yielded the graph shown in Figure C.11. Figure C.11. Recursive Instantiation Time versus Argument Nesting Depth
This change may have improved the results for GCC slightly, which we're at a loss to explain. The others, except for Comeau, didn't change at all. Comeau's results got noticeably worse, so clearly it responds not only to the number of nodes but also nesting depth. That said, there are no changes in big-O complexity here for any of the compilers. C.3.7.2 Using Sequence Derivation to Limit Structural ComplexitySequence derivation, as described in Chapter 5, is a powerful weapon in the fight against the effects of argument complexity on compilation time, especially for vector-like sequences. In large part this is due to the structure of their iterators. Recall the declaration of tiny_iterator:
template <class Tiny, class Pos>
struct tiny_iterator;
A tiny_iterator specialization mentions the entire name of the sequence it traverses as a template argument. If we extrapolate to sequences with greater capacity, it's easy to see that:
mpl::vector_iterator<my_vector, mpl::int_<3> >
may be faster to manipulate than:
mpl::vector_iterator<mpl::vector30<int,..., Foo>, mpl::int_<3> >
|