| I l@ve RuBoard |
|
4.4 ChunksEach object of type Chunk contains and manages a chunk of memory containing a fixed amount of blocks. At construction time, you configure the block size and the number of blocks. A Chunk contains logic that allows you to allocate and deallocate memory blocks from that chunk of memory. When there are no more blocks available in the chunk, the allocation function returns zero. The definition of Chunk is as follows:
// Nothing is private — Chunk is a Plain Old Data (POD) structure
// structure defined inside FixedAllocator
// and manipulated only by it
struct Chunk
{
void Init(std::size_t blockSize, unsigned char blocks);
void* Allocate(std::size_t blockSize);
void Deallocate(void* p, std::size_t blockSize);
unsigned char* pData_;
unsigned char
firstAvailableBlock_,
blocksAvailable_;
};
In addition to a pointer to the managed memory itself, a chunk stores the following integral values:
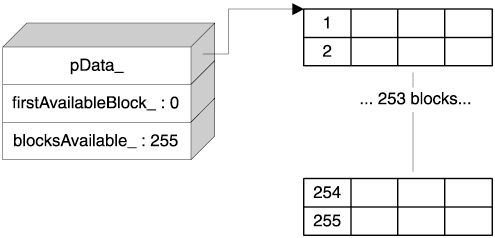
The interface of Chunk is very simple. Init initializes a Chunk object, and Release releases the allocated memory. The Allocate function allocates a block, and Deallocate deallocates a block. You have to pass a size to Allocate and Deallocate because Chunk does not hold it. This is because the block size is known at a superior level. Chunk would waste space and time if it redundantly kept a blockSize_ member. Don't forget we are at the very bottom here—everything matters. Again for efficiency reasons, Chunk does not define constructors, destructors, or assignment operator. Defining proper copy semantics at this level hurts efficiency at upper levels, where we store Chunk objects in a vector. The Chunk structure reveals important trade-offs. Because blocksAvailable_ and firstAvailableBlock_ are of type unsigned char, it follows that you cannot have a chunk that contains more than 255 blocks (on a machine with 8-bit characters). As you will soon see, this decision is not bad at all and saves us a lot of headaches. Now for the interesting part. A block can be either used or unused. We can store whatever we want in an unused block, so we take advantage of this. The first byte of an unused block holds the index of the next unused block. Because we hold the first available index in firstAvailableBlock_, we have a full-fledged singly linked list of unused blocks without using any extra memory. At initialization, a chunk looks like Figure 4.4. The code that initializes a Chunk object looks like this:
void Chunk::Init(std::size_t blockSize, unsigned char blocks)
{
pData_ = new unsigned char[blockSize * blocks];
firstAvailableBlock_ = 0;
blocksAvailable_ = blocks;
unsigned char i = 0;
unsigned char* p = pData_;
for (; i != blocks; p += blockSize)
{
*p = ++i;
}
}
Figure 4.4. A chunk of 255 blocks of 4 bytes each
This singly linked list melted inside the data structure is an essential goodie. It offers a fast, efficient way of finding available blocks inside a chunk—without any extra cost in size. Allocating and deallocating a block inside a Chunk takes constant time, which is exclusively thanks to the embedded singly linked list. Now you see why the number of blocks is limited to a value that fits in an unsigned char. Suppose we used a larger type instead, such as unsigned short (which is 2 bytes on many machines). We would now have two problems—a little one and a big one.
The solution is simple: We use unsigned char as the type of the "stealth index." A character type has size 1 by definition and does not have any alignment problem because even the pointer to the raw memory points to unsigned char. This setting imposes a limitation on the maximum number of blocks in a chunk. We cannot have more than UCHAR_MAX blocks in a chunk (255 on most systems). This is acceptable even if the size of the block is really small, such as 1 to 4 bytes. For larger blocks, the limitation doesn't make a difference because we don't want to allocate chunks that are too big anyway. The allocation function fetches the block indexed by firstAvailableBlock_ and adjusts firstAvailableBlock_ to refer to the next available block—typical list stuff.
void* Chunk::Allocate(std::size_t blockSize)
{
if (!blocksAvailable_) return 0;
unsigned char* pResult =
pData_ + (firstAvailableBlock_ * blockSize);
// Update firstAvailableBlock_ to point to the next block
firstAvailableBlock_ = *pResult;
——blocksAvailable_;
return pResult;
}
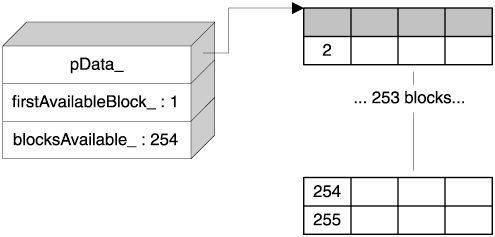
The cost of Chunk::Allocate is one comparison, one indexed access, two dereference operations, an assignment, and a decrement—quite a small cost. Most important, there are no searches. We're in pretty good shape so far. Figure 4.5 shows the layout of a Chunk object after the first allocation. Figure 4.5. A Chunk object after the one allocation. The allocated memory is shown in gray
The deallocation function does exactly the opposite: It passes the block back to the free blocks list and increments blocksAvailable_. Don't forget that because Chunk is agnostic regarding the block size, you must pass the size as a parameter to Deallocate.
void Chunk::Deallocate(void* p, std::size_t blockSize)
{
assert(p >= pData_);
unsigned char* toRelease = static_cast<unsigned char*>(p);
// Alignment check
assert((toRelease - pData_) % blockSize == 0);
*toRelease = firstAvailableBlock_;
firstAvailableBlock_ = static_cast<unsigned char>(
(toRelease - pData_) / blockSize);
// Truncation check
assert(firstAvailableBlock_ ==
(toRelease - pData_) / blockSize);
++blocksAvailable_;
}
The deallocation function is lean, but it does a lot of assertions (which still don't catch all error conditions). Chunk respects the grand C and C++ tradition in memory allocation: Prepare for the worst if you pass the wrong pointer to Chunk::Deallocate. |
| I l@ve RuBoard |
|