| I l@ve RuBoard |
|
10.1 Visitor BasicsLet's consider a class hierarchy whose functionality you want to enhance. To do this, you can either add new classes or add new virtual member functions. Adding new classes is easy. You derive from a leaf class and implement the needed virtual functions. You don't need to change or recompile any existing classes. It's code reuse at its best. In contrast, adding new virtual functions is difficult. To be able to manipulate objects polymorphically (via pointers to the root class), you must add virtual member functions to the root class, and possibly to many other classes in the hierarchy. This is a major operation. It modifies the root class on which all the hierarchy and clients are dependent. As the ultimate result, you have to recompile the world. In a nutshell, from a dependency standpoint, new classes are easy to add, and new virtual member functions are difficult to add. But suppose that you have a hierarchy to which you seldom add new classes, but to which you often need to add virtual member functions. In this case, you have an advantage that you don't need, namely, the ease of adding classes. You also have a drawback that's annoying, namely, the difficulty of adding new virtual member functions. Here's where Visitor can be of help. Visitor trades the advantage you don't care about for an advantage you need. Visitor enables you to add new virtual functions to a hierarchy easily, while also making it more difficult to add new classes. The runtime cost of this wizardry is at least an extra virtual call, as you will see. Visitor applies best when operations on objects are distinct and unrelated. The "state and operations" paradigm for each class becomes of little relevance. A view that separates types from operations is more appropriate. For such cases, it makes more sense to keep various implementations of a conceptual operation together, rather than spread them over the class hierarchy. Suppose, for example, that you develop a document editor. Document elements such as paragraphs, vector drawings, and bitmaps are represented as classes derived from a common root, say, DocElement. The document is a structured collection of pointers to DocElements. You need to iterate through this structure and perform operations such as spell checking, reformatting, and statistics gathering. In an ideal world, you should implement those operations mostly by adding code, not by modifying existing code. Furthermore, you ease maintenance if you put all the code pertaining to, say, getting document statistics in one place. Document statistics may include the number of characters, nonblank characters, words, and images. These would naturally belong to a class called DocStats.
class DocStats
{
unsigned int
chars_,
nonBlankChars_,
words_,
images_;
...
public:
void AddChars(unsigned int charsToAdd)
{
chars_ += charsToAdd;
}
...similarly defined AddWords, AddImages...
// Display the statistics to the user in a dialog box
void Display();
};
If you used a classic object-oriented approach to grabbing statistics, you would define a virtual function in DocElement that deals with gathering statistics.
class DocElement
{
...
// This member function helps the "Statistics" feature
virtual void UpdateStats(DocStats& statistics) = 0;
};
Then each concrete document element would define the function in its own way. For example, class Paragraph and class RasterBitmap, which are derived from DocElement, would implement UpdateStats as follows:
void Paragraph::UpdateStats(DocStats& statistics)
{
statistics.AddChars(number of characters in the paragraph);
statistics.AddWords(number of words in the paragraph);
}
void RasterBitmap::UpdateStats(DocStats& statistics)
{
// A raster bitmap counts as one image
// and nothing else (no characters etc.)
statistics.AddImages(1);
}
Finally, the driver function would look like this:
void Document::DisplayStatistics()
{
DocStats statistics;
for (each DocElement in the document)
{
element->UpdateStats(statistics);
}
statistics.Display();
}
This is a fairly good implementation of the Statistics feature, but it has a number of disadvantages.
A solution that breaks the dependency of DocElement on DocStats is to move all operations into the DocStats class and let it figure out what to do for each concrete type. This implies that DocStats has a member function void UpdateStats(DocElement&). The document then simply iterates through its elements and calls UpdateStats for each of them. This solution effectively makes DocStats invisible to DocElement. However, now DocStats depends on each concrete DocElement that it needs to process. If the object hierarchy is more stable than its operations, the dependency is not very annoying. Now the problem is that the implementation of UpdateStats has to rely on the so-called type switch. A type switch occurs whenever you query a polymorphic object on its concrete type and perform different operations with it depending on what that concrete type is. DocStats::UpdateStats is bound to do such a type switch, as in the following:
void DocStats::UpdateStats(DocElement& elem)
{
if (Paragraph* p = dynamic_cast<Paragraph*>(&elem))
{
chars_ += p->NumChars();
words_ += p->NumWords();
}
else if (dynamic_cast<RasterBitmap*>(&elem))
{
++images_;
}
else ...
add one 'if' statement for each type of object you inspect
}
(The definition of p inside the if test is legal because of to a little-known addition to C++. You can define and test a variable right in an if statement. The lifetime of that variable extends to that if statement and its else part, if any. Although it's not an essential feature and writing cute code per se is not recommended, the feature was invented especially to support type switches, so why not reap the benefits?) Whenever you see something like this, a mental alarm bell should go off. Type switching is not at all a desirable solution. (Chapter 8 presents a detailed argument.) Code that relies on type switching is hard to understand, hard to extend, and hard to maintain. It's also open to insidious bugs. For example, what if you put the dynamic_cast for a base class before the dynamic_cast for a derived class? The first test will match derived objects, so the second one will never succeed. One of the goals of polymorphism is to eliminate type switches because of all the problems they have. Here's where the Visitor pattern can be helpful. You need new functions to act virtual, but you don't want to add a new virtual function for each operation. To effect this, you must implement a unique bouncing virtual function in the DocElement hierarchy, a function that "teleports" work to a different hierarchy. The DocElement hierarchy is called the visited hierarchy, and the operations belong to a new visitor hierarchy. Each implementation of the bouncing virtual function calls a different function in the visitor hierarchy. That's how visited types are selected. The functions in the visitor hierarchy called by the bouncing function are virtual. That's how operations are selected. Following are a few lines of code to illustrate this idea. First, we define an abstract class DocElementVisitor that defines an operation for each type of object in the DocElement hierarchy.
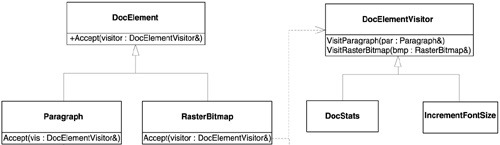
class DocElementVisitor
{
public:
virtual void VisitParagraph(Paragraph&) = 0;
virtual void VisitRasterBitmap(RasterBitmap&) = 0;
... other similar functions ...
};
Next we add the bouncing virtual function, called Accept, to the class DocElement hierarchy, one that takes a DocElementVisitor& and invokes the appropriate VisitXxx function on its parameter.
class DocElement
{
public:
virtual void Accept(DocElementVisitor&) = 0;
...
};
void Paragraph::Accept(DocElementVisitor& v)
{
v.VisitParagraph(*this);
}
void RasterBitmap::Accept(DocElementVisitor& v)
{
v.VisitRasterBitmap(*this);
}
Now here's DocStats in all its splendor:
class DocStats : public DocElementVisitor
{
public:
virtual void VisitParagraph(Paragraph& par)
{
chars_ += par.NumChars();
words_ += par.NumWords();
}
virtual void VisitRasterBitmap(RasterBitmap&)
{
++images_;
}
...
};
(Of course, a real-world implementation would likely pull out the functions' implementations from the class definition to a separate source file.) This small example also illustrates a drawback of Visitor: You don't really add virtual member functions. True virtual functions have full access to the object for which they're defined, whereas from inside VisitParagraph you can access only the public part of Paragraph. The driver function Document::DisplayStatistics creates a DocStats object and invokes Accept on each DocElement, passing that DocStats object as a parameter. As the DocStats object visits various concrete DocElements, it gets nicely filled up with the appropriate data—no type switching needed!
void Document::DisplayStatistics()
{
DocStats statistics;
for (each DocElement in the document)
{
element->Accept(statistics);
}
statistics.Display();
}
Let's analyze the resulting context. We have added a new hierarchy, rooted in DocElementVisitor. This is a hierarchy of operations—each of its classes is actually an operation, like DocStatsis. Adding a new operation becomes as easy as deriving a new class from DocElementVisitor. No element of the DocElement hierarchy needs to be changed. For instance, let's add a new operation, IncrementFontSize, as a helper in implementing an Increase Font Size hot key or toolbar button.
class IncrementFontSize : public DocElementVisitor
{
public:
virtual void VisitParagraph(Paragraph& par)
{
par.SetFontSize(par.GetFontSize() + 1);
}
virtual void VisitRasterBitmap(RasterBitmap&)
{
// nothing to do
}
...
};
That's it. No change to the DocElement class hierarchy is needed, and there is no change to the other operations. You just add a new class. DocElement::Accept bounces IncrementFontSize objects just as well as it bounces DocStats objects. The resulting class structure is represented in Figure 10.1. Figure 10.1. The visitor and visited hierarchies, and how operations are teleported
Recall that, by default, new classes are easy to add, whereas new virtual member functions are not easy. We transformed classes into functions by bouncing back from the DocElement hierarchy to the DocElementVisitor hierarchy; thus, DocElementVisitor's derivatives are objectified functions. This is how the Visitor design pattern works. |
| I l@ve RuBoard |
|