5-3 Counting Leading 0's
There are several simple ways to count leading 0's with a binary search technique. Below is a model that has several variations. It executes in 20 to 29 instructions on the basic RISC. The comparisons are "logical" (unsigned integers).
if (x == 0) return(32); n = 0; if (x <= 0x0000FFFF) {n = n +16; x = x <<16;} if (x <= 0x00FFFFFF) {n = n + 8; x = x << 8;} if (x <= 0x0FFFFFFF) {n = n + 4; x = x << 4;} if (x <= 0x3FFFFFFF) {n = n + 2; x = x << 2;} if (x <= 0x7FFFFFFF) {n = n + 1;} return n;
One variation is to replace the comparisons with and's:
if ((x & 0xFFFF0000) == 0) {n = n +16; x = x <<16;} if ((x & 0xFF000000) == 0) {n = n + 8; x = x << 8} ...
Another variation, which avoids large immediate values, is to use shift right instructions.
The last if statement is simply adding 1 to n if the high-order bit of x is 0, so an alternative, which saves a branch instruction, is:
n = n + 1 - (x >> 31);
The "+ 1" in this assignment can be omitted if n is initialized to 1 rather than to 0. These observations lead to the algorithm (12 to 20 instructions on the basic RISC) shown in Figure 5-6. A further improvement is possible for the case in which x begins with a 1-bit: change the first line to
if ((int)x <= 0) return (~x >> 26) & 32;
Figure 5-6 Number of leading zeros, binary search.
int nlz(unsigned x) {牋 int n;
牋 if (x == 0) return(32);
牋爊 = 1;
牋爄f ((x >> 16) == 0) {n = n +16; x = x <<16;} 牋爄f ((x >> 24) == 0) {n = n + 8; x = x << 8;} 牋爄f ((x >> 28) == 0) {n = n + 4; x = x << 4;} 牋爄f ((x >> 30) == 0) {n = n + 2; x = x << 2;} 牋爊 = n - (x >> 31);
牋爎eturn n;
}
Figure 5-7 illustrates a sort of reversal of the above. It requires fewer operations the more leading 0's there are, and avoids large immediate values and large shift amounts. It executes in 12 to 20 instructions on the basic RISC.
Figure 5-7 Number of leading zeros, binary search, counting down.
int nlz(unsigned x) {牋 unsigned y;
牋爄nt n;
牋 n = 32;
牋爕 = x >>16; 爄f (y != 0) {n = n -16;?x = y;} 牋爕 = x >> 8;?if (y != 0) {n = n - 8;?x = y;} 牋爕 = x >> 4;?if (y != 0) {n = n - 4;?x = y;} 牋爕 = x >> 2;?if (y != 0) {n = n - 2;?x = y;} 牋爕 = x >> 1;?if (y != 0) return n - 2;
牋爎eturn n - x;
}
This algorithm is amenable to a "table assist": the last four executable lines can be replaced by
static char table[256] = {0,1,2,2,3,3,3,3,4,4,...,8); return n - table[x];
Many algorithms can be aided by table lookup, but this will not often be mentioned here.
For compactness, this and the preceding algorithms in this section can be coded as loops. For example, the algorithm of Figure 5-7 becomes the algorithm shown in Figure 5-8. This executes in 23 to 33 basic RISC instructions, ten of which are conditional branches.
Figure 5-8 Number of leading zeros, binary search, coded as a loop.
int nlz(unsigned x) {牋 unsigned y;
牋爄nt n, c;
牋 n = 32;
牋燾 = 16;
牋燿o {牋牋?y = x >> c;?if (y != 0) {n = n - c;?x = y;} 牋牋牋c = c >> 1;
牋爙 while (c != 0);
牋爎eturn n - x;
}
One can, of course, simply shift left one place at a time, counting, until the sign bit is on; or shift right one place at a time until the word is all 0. These algorithms are compact and work well if the number of leading 0's is expected to be small or large, respectively. One can combine the methods, as shown in Figure 5-9. We mention this because the technique of merging two algorithms and choosing the result of whichever one stops first is more generally applicable. It leads to code that runs fast on superscalar and VLIW machines, because of the proximity of independent instructions. (These machines can execute two or more instructions simultaneously, provided they are independent.)
Figure 5-9 Number of leading zeros, working both ends at the same time.
int nlz(int x) {牋 int y, n;
牋 n = 0;
牋爕 = x;
L: if (x < 0) return n;
牋爄f (y == 0) return 32 - n;
牋爊 = n + 1;
牋爔 = x << 1;
牋爕 = y >> 1;
牋爂oto L;
}
On the basic RISC, this executes in min(3 + 6nlz(x), 5 + 6(32 - nlz(x))) instructions, or 99 worst case. However, one can imagine a superscalar or VLIW machine executing the entire loop body in one cycle if the comparison results are obtained as a by-product of the shifts, or in two cycles otherwise, plus the branch overhead.
It is straightforward to convert either of the algorithms of Figure 5-6 or Figure 5-7 to a branch-free counterpart. Figure 5-10 shows a version that does the job in 28 basic RISC instructions.
Figure 5-10 Number of leading zeros, branch-free binary search.
int nlz(unsigned x) {牋 int y, m, n;
牋 y = -(x >> 16);牋牋?// If left half of x is 0,
牋爉 = (y >> 16) & 16;?// set n = 16. If left half
牋爊 = 16 - m;牋牋牋牋?// is nonzero, set n = 0 and
牋爔 = x >> m;牋牋牋牋?// shift x right 16.
牋牋牋牋牋牋牋牋牋牋牋牋// Now x is of the form 0000xxxx.
牋爕 = x - 0x100;牋牋牋 // If positions 8-15 are 0,
牋爉 = (y >> 16) & 8;牋 // add 8 to n and shift x left 8.
牋爊 = n + m;
牋爔 = x << m;
牋 y = x - 0x1000;牋牋?// If positions 12-15 are 0,
牋爉 = (y >> 16) & 4;牋 // add 4 to n and shift x left 4.
牋爊 = n + m;
牋爔 = x << m;
牋 y = x - 0x4000;牋牋?// If positions 14-15 are 0,
牋爉 = (y >> 16) & 2;牋 // add 2 to n and shift x left 2.
牋爊 = n + m;
牋爔 = x << m;
牋 y = x >> 14;牋牋牋牋 // Set y = 0, 1, 2, or 3.
牋爉 = y & ~(y >> 1);牋 // Set m = 0, 1, 2, or 2 resp.
牋爎eturn n + 2 - m;
}
If your machine has the population count instruction, a good way to compute the number of leading zeros function is given in Figure 5-11. The five assignments to x may be reversed, or in fact done in any order. This is branch-free and takes 11 instructions. Even if population count is not available, this algorithm may be useful. Using the 21-instruction code for counting 1-bits given in Figure 5-2 on page 66, it executes in 32 branch-free basic RISC instructions.
Figure 5-11 Number of leading zeros, right-propagate and count 1-bits.
int nlz(unsigned x) {牋 int pop(unsigned x);
牋 x = x | (x >> 1);
牋爔 = x | (x >> 2);
牋爔 = x | (x >> 4);
牋爔 = x | (x >> 8);
牋爔 = x | (x >>16);
牋爎eturn pop(~x);
}
Floating-Point Methods
The floating-point post-normalization facilities can be used to count leading zeros. It works out quite well with IEEE-format floating-point numbers. The idea is to convert the given unsigned integer to double-precision floating-point, extract the exponent, and subtract it from a constant. Figure 5-12 illustrates a complete procedure for this.
Figure 5-12 Number of leading zeros, using IEEE floating-point.
int nlz(unsigned k) {牋 union {牋牋?unsigned asInt[2];
牋牋牋double asDouble;
牋爙;
牋爄nt n;
牋 asDouble = (double)k + 0.5;
牋爊 = 1054 - (asInt[LE] >> 20);
牋爎eturn n;
}
The code uses the C++ "anonymous union" to overlay an integer with a double-precision floating-point quantity. Variable LE must be 1 for execution on a little-endian machine, and 0 for big-endian. The addition of 0.5, or some other small number, is necessary for the method to work when k = 0.
We will not attempt to assess the execution time of this code, because machines differ so much in their floating-point capabilities. For example, many machines have their floating-point registers separate from the integer registers, and on such machines data transfers through memory may be required to convert an integer to floating-point and then move the result to an integer register.
The code of Figure 5-12 is not valid C or C++ according to the ANSI standard, because it refers to the same memory locations as two different types. Thus, one cannot be sure it will work on a particular machine and compiler. It does work with IBM's XLC compiler on AIX, and with the GCC compiler on AIX and on Windows 2000, at all optimization levels (as of this writing, anyway). If the code is altered to do the overlay defining with something like
xx = (double)k + 0.5;
n = 1054 - (*((unsigned *)&xx + LE) >> 20);
it does not work on these systems with optimization turned on. This code, incidentally, violates a second ANSI standard, namely, that pointer arithmetic can be performed only on pointers to array elements [Cohen]. The failure, however, is due to the first violation, involving overlay defining.
In spite of the flakiness of this code, [1] three variations are given below.
[1] The flakiness is due to the way C is used. The methods illustrated would be perfectly acceptable if coded in machine language, or generated by a compiler, for a particular machine.
asDouble = (double)k;
n = 1054 - (asInt[LE] >> 20);
n = (n & 31) + (n >> 9);
k = k & ~(k >> 1);
asFloat = (float)k + 0.5f;
n = 158 - (asInt >> 23);
k = k & ~(k >> 1);
asFloat = (float)k;
n = 158 - (asInt >> 23);
n = (n & 31) + (n >> 6);
In the first variation, the problem with k = 0 is fixed not by a floating-point addition of 0.5, but by integer arithmetic on the result n (which would be 1054, or 0x41E, if the correction were not done).
The next two variations use single-precision floating-point,
with the "anonymous union" changed in an obvious way. Here there is a
new problem: Rounding can throw off the result when the rounding mode is either
round to nearest (almost universally used) or round toward +![]() . For round to nearest mode, the
rounding problem occurs for k in
the ranges hexadecimal FFFFFF80 to FFFFFFFF, 7FFFFFC0 to 7FFFFFFF, 3FFFFFE0 to
3FFFFFFF, and so on. In rounding, an add of 1 carries all the way to the left,
changing the position of the most significant 1-bit. The correction steps used
above clear the bit to the right of the most significant 1-bit, blocking the
carry.
. For round to nearest mode, the
rounding problem occurs for k in
the ranges hexadecimal FFFFFF80 to FFFFFFFF, 7FFFFFC0 to 7FFFFFFF, 3FFFFFE0 to
3FFFFFFF, and so on. In rounding, an add of 1 carries all the way to the left,
changing the position of the most significant 1-bit. The correction steps used
above clear the bit to the right of the most significant 1-bit, blocking the
carry.
The GNU C/C++ compiler has a unique feature that allows coding any of these schemes as a macro, giving in-line code for the function references [Stall]. This feature allows statements, including declarations, to be inserted in code where an expression is called for. The sequence of statements would usually end with an expression, which is taken to be the value of the construction. Such a macro definition is shown below, for the first single-precision variation. (In C, it is customary to use uppercase for macro names.)
#define NLZ(k) \
牋?{union {unsigned _asInt; float _asFloat;}; \ 牋牋爑nsigned _kk = (k) & ~((unsigned)(k) >> 1); \
牋牋燺asFloat = (float)_kk + 0.5f; \
牋牋?58 - (_asInt >> 23);})
The underscores are used to avoid name conflicts with parameter k; presumably, user-defined names do not begin with underscores.
Relation to the Log Function
The "nlz" function is, essentially, the
"integer log base 2" function. For unsigned x ![]() 0,
0,
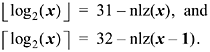
See also Section 11- 4, "Integer Logarithm," on page 215.
Another closely related function is bitsize, the number of bits required to represent its argument as a signed quantity in two's-complement form. We take its definition to be
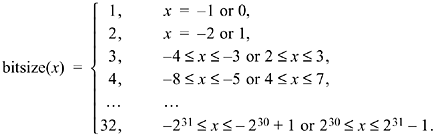
From this definition, bitsize(x) = bitsize(- x - 1). But - x - 1 = ?span class=docemphbolditalic1>x, so an algorithm for bitsize is (where the shift is signed)
x = x ^ (x >> 31);牋牋牋牋?// If (x < 0) x = -x - 1; return 33 - nlz(x);
Applications
Two important applications of the number of leading zeros function are in simulating floating-point arithmetic operations and in various division algorithms (see Figure 9-1 on page 141, and Figure 9-3 on page 152). The instruction seems to have a miscellany of other uses.
It can be used to get the "x = y " predicate in only three instructions (see "Comparison Predicates" on page 21), and as an aid in computing certain elementary functions (see pages 205, 208, 214, and 218).
A novel application is to generate exponentially distributed random integers by generating uniformly distributed random integers and taking "nlz" of the result [GLS1]. The result is 0 with probability 1/2, 1 with probability 1/4, 2 with probability 1/8, and so on. Another application is as an aid in searching a word for a consecutive string of 1-bits (or 0-bits) of a certain length, a process that is used in some disk block allocation algorithms. For these last two applications, the number of trailing zeros function could also be used.