6-2 Find First String of 1-Bits of a Given Length
The problem here is to search a word in a register for the first string of 1-bits of a given length n or longer, and to return its position, with some special indication if no such string exists. Variants are to return only the yes/no indication, and to locate the first string of exactly n 1-bits. This problem has application in disk-allocation programs, particularly for disk compaction (rearranging data on a disk so that all blocks used to store a file are contiguous). The problem was suggested to me by Albert Chang, who pointed out that it is one of the uses for the number of leading zeros instruction.
We assume here that the number of leading zeros instruction, or a suitable subroutine for that function, is available.
An algorithm that immediately comes to mind is to first count the number of leading 0's and skip over them by shifting left by the number obtained. Then count the leading 1's by inverting and counting leading 0's. If this is of sufficient length, we are done. Otherwise, shift left by the number obtained and repeat from the beginning. This algorithm might be coded as shown below. If n consecutive 1-bits are found, it returns a number from 0 to 31, giving the position of the leftmost 1-bit in the leftmost such sequence. Otherwise, it returns 32 as a "not found" indication.
int ffstr1(unsigned x, int n) { int k, p; p = 0; // Initialize position to return. while (x != 0) { ?k = nlz(x); // Skip over initial 0's x = x << k; // (if any). p = p + k; k = nlz(~x); ?// Count first/next group of 1's. if (k >= n) // If enough, return p; ?// return. x = x << k; // Not enough 1's, skip over p = p + k; ?// them. } return 32; }
This algorithm is reasonable if it is
expected that the loop will not be executed very many timesfor example, if it
is expected that x will have long sequences of 1's and of 0's. This might very well be
the expectation in the disk-allocation application. Its worst-case execution
time, however, is not very good; for example, about 178 full RISC instructions
executed for x = 0x55555555 and n ![]() 2.
2.
An algorithm that is better in worst-case execution time is based on a sequence of shift left and and instructions. To see how this works, consider searching for a string of eight or more consecutive 1-bits in a 32-bit word x. This might be done as follows:
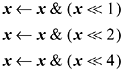
After the first assignment, the 1's in x indicate the starting positions of strings of length 2. After the second assignment, the 1's in x indicate the starting positions of strings of length 4 (a string of length 2 followed by another string of length 2). After the third assignment, the 1's in x indicate the starting positions of strings of length 8. Executing number of leading zeros on this word gives the position of the first string of length 8 (or more), or 32 if none exists.
To develop an algorithm that works for any length n from 1 to 32, we will look at this a little differently. First, observe that the above three assignments may be done in any order. Reverse order will be more convenient. To illustrate the general method, consider the case n = 10:

The first statement shifts by n/2. After executing it, the problem is reduced to
finding a string of five consecutive 1-bits in x1.
This may be done by shifting left by ![]() and'ing, and
searching the result for a string of length 3 (5 - 2). The last two statements
identify where the strings of length 3 are in x2.
The sum of the shift amounts is always n - 1.
The algorithm is shown in Figure 6-5. The
execution time ranges from 3 to 36 full RISC instructions, as n ranges from
1 to 32.
and'ing, and
searching the result for a string of length 3 (5 - 2). The last two statements
identify where the strings of length 3 are in x2.
The sum of the shift amounts is always n - 1.
The algorithm is shown in Figure 6-5. The
execution time ranges from 3 to 36 full RISC instructions, as n ranges from
1 to 32.
If n is often moderately
large, it is not unreasonable to unroll this loop by repeating the loop body
five times and omitting the test n > 1. (Five is
always sufficient for a 32-bit machine.) This gives a branch-free algorithm
that runs in a constant time of 20 instructions executed (the last assignment
to n can be omitted). Although for small values of n the three
assignments are executed more than necessary, the result is unchanged by the
extra steps because variable n sticks at the value 1, and for this value the three steps have no
effect on x or n. The unrolled version is faster than the looping version for n ![]() 5, in
terms of number of instructions executed.
5, in
terms of number of instructions executed.
Figure 6-5 Find first string of n 1's, shift-and-and sequence.
int ffstr1(unsigned x, int n) { int s; while (n > 1) { ?s = n >> 1; x = x & (x << s); n = n - s;
}
return nlz(x); }
A string of exactly n 1-bits can be found in six more instructions (four if and not is available). The quantity x computed by the algorithm of Figure 6-5 has 1-bits wherever a string of length n or more 1-bits begins. Hence, using the final value of x computed by that algorithm, the expression
![]()
contains a 1-bit wherever the final x contains an isolated 1-bit, which is to say wherever the original x began a string of exactly n 1-bits.
The algorithm is also easily adapted to finding strings of length n that begin at certain locations. For example, to find strings that begin at byte boundaries, simply and the final x with 0x80808080.
It can be used to find strings of 0-bits either by complementing x at the start, or by changing the and's to or's and complementing x just before invoking "nlz." For example, below is an algorithm for finding the first (leftmost) 0-byte (see Section 6-1, "Find First 0-Byte," on page 91, for a precise definition of this problem).
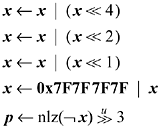
This executes in 12 instructions on the full RISC (not as good as the algorithm of Figure 6-2 on page 92, which executes in eight instructions).