| [ Team LiB ] |
|
Gotcha #69: Type CodesOne of the surest signs of "my first C++ program" is the presence of a type code as a class data member. (I used them in my first C++ program, and they caused me no end of misery.) In object-oriented programming, the type of an object is represented by the way it behaves, not by its state. Only rarely is a specific type code necessary in a well-designed C++ program, and it's never necessary to store the type code as a data member. class Base { public: enum Tcode { DER1, DER2, DER3 }; Base( Tcode c ) : code_( c ) {} virtual ~Base(); int tcode() const { return code_; } virtual void f() = 0; private: Tcode code_; }; class Der1 : public Base { public: Der1() : Base( DER1 ) {} void f(); }; The code above is a pretty typical manifestation of this problem. The problem is that the designer is not yet confident enough to commit fully to an object-oriented design that employs dynamic binding consistently in a well-designed hierarchy. The type code is there in case (the designer thinks) a switch (that comfortingly pathological old C construct) is ever needed or if it's necessary to find out exactly what type of Base we're dealing with. Wrong. Using a type code in an object-oriented design is like trying to dive while keeping one foot on the diving board: it's not going to work, and the landing is going to be painful. In C++, we never switch on type codes in the object-oriented segments of our design. Never. The major problem is obvious from the enum Tcode in Base. A source code change is required to add a new derived class, and the base class effectively knows about, and is coupled to, its derived classes. There is no guarantee that all the existing code that examines the Tcode enumerators is going to be properly updated. A common problem in the maintenance of C programs is updating only 98% of the statements that switch over a modified set of type codes. This is a problem that simply does not occur with virtual functions, and it's a problem a designer should not expend effort to reintroduce. Type codes stored as data members cause subtler problems as well. It's possible that the type code may be copied from one type of Base to another. In a large and complex program that employs type codes, it's likely:
Base *bp1 = new Der1;
Base *bp2 = new Der2;
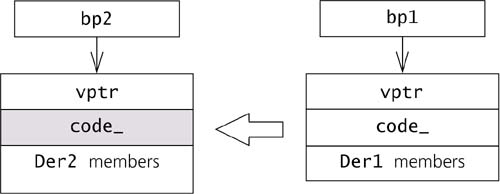
*bp2 = *bp1; // disaster!
Note that the type of the Der2 object hasn't changed. Type is defined by behavior, and much of the behavior of the Der2 object is determined by the mechanism that the constructor for the Der2 object set up when the object was initialized. For example, the virtual function table pointer, which is implicitly inserted by the compiler and determines what implementation an object's functions will use in dynamic binding, will not be changed by the code above, though the explicitly declared Base data members will be. (See Gotchas #50 and #78.) In Figure 7-1, only the shaded areas of the object referred to by bp2 will be modified by the assignment. Figure 7-1. Effect of assigning a base class subobject from one derived class object to another. Only the declared data members of the base class subobject are copied. Implicit, compiler-inserted class mechanism is not.
Once an object's type has been set during construction, it doesn't change. However, the Der2 object referred to by bp2 will claim to be a Der1 object. Any switch-based code is going to believe the object's claim, and any (proper) dynamic-binding-based code will ignore it. A schizophrenic object. If a particular rare design situation actually does require a type code, it's generally best to observe two implementation guidelines. First, don't store the code as a data member. Use a virtual function instead, because this has the effect of associating the type code more directly with the actual type (behavior) of the object and will avoid the schizophrenic problems inherent in a more casual association:
class Base {
public:
enum Tcode { DER1, DER2, DER3 };
Base();
virtual ~Base();
virtual int tcode() const = 0;
virtual void f() = 0;
// . . .
};
class Der1 : public Base {
public:
Der1() : Base() {}
void f();
int tcode() const
{ return DER1; }
};
Second, it's best if the base class can remain ignorant of its derived classes, since this reduces coupling within the hierarchy and facilitates the addition and removal of derived classes during maintenance. This generally implies that the set of type codes be maintained outside the program itself, perhaps as part of an official standard that maintains the lists of type codes or specifies an algorithm or procedure for generating the set of type codes. Each individual derived class may be aware of its own code, but this information should be hidden from the rest of the program. One common situation that forces a designer to consider the use of a type code occurs when an object-oriented design must communicate with a non-object-oriented module. For example, a "message" of some sort may be read from an external source, and the type of the message is indicated by an initial integral code. The length and structure of the remainder of the message is determined by the code. What's a designer to do? Generally, the best approach is to erect a design firewall. In this case, the portion of the design that communicates with the external representation of a message will switch on the integral code to generate a proper object that doesn't contain a type code. The bulk of the design can then safely ignore the type codes and employ dynamic binding. Note that it's trivial to regenerate the original message from the object, if necessary, since the object can be aware of its corresponding type code without actually storing it as a data member. One drawback of this scheme is that it's necessary to modify and recompile that single switch-statement whenever the set of possible messages changes. However, because of the design firewall, any such modification is limited to the firewall code itself:
Msg *firewall( RawMsgSource &src ) {
switch( src.msgcode ) {
case MSG1:
return new Msg1( src );
case MSG2:
return new Msg2( src );
// etc.
}
In some cases, even this limited recompilation is not acceptable. For example, it may be necessary to add new message types to an application while it's running. In cases like this, one can take advantage of the "fungible" nature of control structures and substitute an interpreted runtime data structure for compiled conditional code. In the case of our message example, we can get by with a simple sequence of objects, each of which represents a different type of message:
class MsgType {
public:
virtual ~MsgType() {}
virtual int code() const = 0;
virtual Msg *generate( RawMsgSource & ) const = 0;
};
class Firewall { // Monostate
public:
void addMsgType( const MsgType * );
Msg *genMsg( RawMsgSource & );
private:
typedef std::vector<MsgType *> C;
typedef C::iterator I;
static C types_;
};
The interpreter is trivial in this case: we simply traverse the sequence looking for the message code of interest. If we find the code, we generate an object of the corresponding message type:
Msg *Firewall::genMsg( RawMsgSource &src ) {
int code = src.msgcode;
for( I i( types_.begin() ); i != types_.end(); ++i )
if( code == i->code() )
return i->generate( src );
return 0;
}
The data structure is easily augmented to recognize new message types:
void Firewall::addMsgType( const MsgType *mt )
{ types_.push_back(mt); }
The individual message types are trivial:
class Msg1Type : public MsgType {
public:
Msg1Type()
{ Firewall::addMsgType( this ); }
int code() const
{ return MSG1; }
Msg *generate( RawMsgSource &src ) const
{ return new Msg1( src ); }
};
The list can be populated with MsgTypes in a number of ways. The simplest way is just to declare a static variable of the type. The constructor will have the side effect of adding the MsgType to the static list in Firewall: static Msg1Type msg1type; Note that the order of initialization of these static objects is not an issue. If it were, the provisos of Gotcha #55 would apply. New MsgType objects can be added to the list at runtime through the use of dynamic loading. Speaking of static objects, note that the implementation of the Firewall class above contains only static data members but that these members are manipulated by non-static member functions. This is an instance of the Monostate pattern. Monostate is an alternative to Singleton as a way to avoid the use of global variables. Singleton forces its users to access the one-and-only object through the instance static member function. If Firewall had been implemented as a Singleton, we would have had to do just that: Firewall::instance().addMessageType( mt ); A Monostate, on the other hand, permits an unbounded number of objects, but they all refer to the same static member data, and no special access protocol is required: Firewall fw; fw.genMsg( rawsource ); FireWall().genMsg( rawsource ); // different object, same state |
| [ Team LiB ] |
|