Scanner
Pointer to pointer type, passing simple types by reference, C++ identifiers, passing buffers.
The list of tokens was enlarged to include four arithmetic operators, the assignment operator, parentheses and a token representing an identifier. An identifier is a symbolic name, like pi, sin, x, etc.
source
enum EToken
{
tEnd,
tError,
tNumber, // literal number
tPlus, // +
tMult, // *
tMinus, // -
tDivide, // /
tLParen, // (
tRParen, // )
tAssign, // =
tIdent // identifier (symbolic name)
};
|
The Accept method was expanded to recognize the additional arithmetic symbols as well as floating point numbers and identifiers. Decimal point was added to the list of digits in the scanner’s switch statement. This is to recognize numbers like .5 that start with the decimal point. The library function strtod (string to double) not only converts a string to a floating point number, but it also updates the pointer to the first character that cannot possibly be part of the number. This is very useful, since it lets us easily calculate the new value of _iLook after scanning the number.
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
case '.':
{
_token = tNumber;
char * p;
_number = strtod (&_buf [_iLook], &p);
_iLook = p - _buf; // pointer subtraction
break;
}
|
The function strtod has two outputs: the value of the number that it has recognized and the pointer to the first unrecognized character.
double strtod (char const * str, char ** ppEnd); |
How can a function have more than one output? The trick is to pass an argument that is a reference or a pointer to the value to be modified by the function. In our case the additional output is a pointer to char. We have to pass a reference or a pointer to this pointer. (Since strtod is a function from the standard C library it uses pointers rather than references. )
Let’s see what happens, step-by-step. We first define the variable which is to be modified by strtod. This variable is a pointer to a char
char * p; |
Notice that we don’t have to initialize it to anything. It will be overwritten in the subsequent call anyway. Next, we pass the address of this variable to strtod
_number = strtod (&_buf [_iLook], &p); |
The function expects a pointer to a pointer to a char
double strtod (char const * str, char ** ppEnd); |
By dereferencing this pointer to pointer, strtod can overwrite the value of the pointer. For instance, it could do this:
*ppEnd = pCurrent; |
This would make the original p point to whatever pCurrent was pointing to.
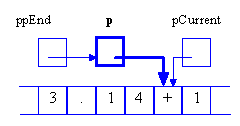
Figure 2-6
In C++ we could have passed a reference to a pointer instead (not that it's much more readable).
char *& pEnd |
It is not clear that passing simple types like char* or int by reference leads to more readable code. Consider this
char * p; _number = StrToDouble (&_buf [_iLook], p); |
It looks like passing an uninitialized variable to a function. Only by looking up the declaration of StrToDouble would you know that p is passed by reference
double StrToDouble (char const * str, char *& rpEnd)
{
...
rpEnd = pCurrent;
...
}
|
Although it definitely is a good programming practice to look up at least the declaration of the function you are about to call, one might argue that it shouldn’t be necessary to look it up when you are reading somebody else’s code. Then again, how can you understand the code if you don’t know what StrToDouble is doing? And how about a comment that will immediately explain what is going on?
char * p; // p will be initialized by StrToDouble _number = StrToDouble (&_buf [_iLook], p); |
You should definitely put a comment whenever you define a variable without immediately initializing it. Otherwise the reader of your code will suspect a bug.
Taking all that into account my recommendation would be to go ahead and use C++ references for passing simple, as well as user defined types by reference.
Of course, if strtod were not written by a human optimizing compiler, the code would probably look more like this
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
case '.':
{
_token = tNumber;
_number = StrToDouble (_buf, _iLook); // updates _iLook
break;
}
|
with StrToDouble declared as follows
double StrToDouble (char const * pBuf, int& iCurrent); |
It would start converting the string to a double starting from pBuf [iCurrent] advancing iCurrent past the end of the number.
Back to Scanner::Accept(). Identifiers are recognized in the default statement of the big switch. The idea is that if the character is not a digit, not a decimal point, not an operator, then it must either be an identifier or an error. We require an identifier to start with an uppercase or lowercase letter, or with an underscore. By the way, this is exactly the same requirement that C++ identifiers must fulfill. We use the isalpha() function (really a macro) to check for the letters of the alphabet. Inside the identifier we (and C++) allow digits as well. The macro isalnum() checks if the character is alphanumeric. Examples of identifiers are thus i, pEnd, _token, __iscsymf, Istop4digits, SERIOUS_ERROR_1, etc.
default:
if (isalpha (_buf [_iLook]) || _buf [_iLook] == '_')
{
_token = tIdent;
_iSymbol = _iLook;
int cLook; // initialized in the do loop
do {
++_iLook;
cLook = _buf [_iLook];
} while (isalnum (cLook) || cLook == '_');
_lenSymbol = _iLook - _iSymbol;
if (_lenSymbol > maxSymLen)
_lenSymbol = maxSymLen;
}
else
_token = tError;
break;
|
To simplify our lives as programmers, we chose to limit the size of symbols to maxSymLen. Remember, we are still weekend programmers!
Once the Scanner recognizes an identifier, it should be able to provide its name for use by other parts of the program. To retrieve a symbol name, we call the following method
void Scanner::SymbolName (char * strOut, int & len)
{
assert (len >= maxSymLen);
assert (_lenSymbol <= maxSymLen);
strncpy (strOut, &_buf [_iSymbol], _lenSymbol);
strOut [_lenSymbol] = 0;
len = _lenSymbol;
}
|
Notice that we have to make a copy of the string, since the original in the buffer is not null terminated. We copy the string to the caller’s buffer strOut of length len. We do it by calling the function strncpy (string-n-copy, where n means that there is a maximum count of characters to be copied). The length is an in/out parameter. It should be initialized by the caller to the size of the buffer strOut. After SymbolName returns, its value reflects the actual length of the string copied.
How do we know that the buffer is big enough? We make it part of the contract—see the assertions.
The method SymbolName is an example of a more general pattern of passing buffers of data between objects. There are three main schemes: caller’s fixed buffer, caller-allocated buffer and callee-allocated buffer. In our case the buffer is passed by the caller and its size is fixed. This allows the caller to use a local fixed buffer—there is no need to allocate or re-allocate it every time the function is called. Here’s the example of the Parser code that makes this call—the buffer strSymbol is a local array
char strSymbol [maxSymLen + 1]; int lenSym = maxSymLen; _scanner.SymbolName (strSymbol, lenSym); |
Notice that this method can only be used when there is a well-defined and reasonable maximum size for the buffer, or when the data can be retrieved incrementally in multiple calls. Here, we were clever enough to always truncate the size of our identifiers to maxSymLen.
If the size of the data to be passed in the buffer is not limited, we have to be able to allocate the buffer on demand. In the case of caller-allocated buffer we have two options. Optimally, the caller should be able to first ask for the size of data, allocate the appropriate buffer and call the method to fill the buffer. There is a variation of the scheme—the caller re-allocated buffer—where the caller allocates the buffer of some arbitrary size that covers, say, 99% of the cases. When the data does not fit into the buffer, the callee returns the appropriate failure code and lets the caller allocate a bigger buffer.
char * pBuf = new char [goodSize];
int len = goodSize;
if (FillBuffer (pBuf, len) == errOverflow)
{
// rarely necessary
delete [] pBuf;
pBuf = new char [len]; // len updated by FillBuffer
FillBuffer (pBuf, len);
}
|
This may seem like a strange optimization until you encounter situations where the call to ask for the size of data is really expensive. For instance, you might be calling across the network, or require disk access to find the size, etc.
The callee-allocated buffer seems a simple enough scheme. The most likely complication is a memory leak when the caller forgets to deallocate the buffer (which, we should remember, hasn’t been explicitly allocated by the caller). We’ll see how to protect ourselves from such problems using smart pointers (see the chapter on managing resources). Other complications arise when the callee uses a different memory allocator than the caller, or when the call is remoted using, for instance, remote procedure call (RPC). Usually we let the callee allocate memory when dealing with functions that have to return dynamic data structures (lists, trees, etc.). Here’s a simple code example of callee-allocated buffer
char * pBuf = AcquireData (); // use pBuf delete pBuf; |
The following decision tree summarizes various methods of passing data to the caller
if (max data size well defined)
{
use caller’s fixed buffer
}
else if (it's cheap to ask for size)
{
use caller-allocated buffer
}
else if ((caller trusted to free memory
&& caller uses the same allocator
&& no problems with remoting)
|| returning dynamic data structures)
{
use callee-allocated buffer
}
else
{
use caller-re-allocated buffer
}
|
In the second part of the book we'll talk about some interesting ways of making the callee-allocated buffer a much more attractive and convenient mechanism.
Next