Linked List
A linked list is a dynamic data structure with fast prepending and appending and linear searching. A list consists of links. Suppose that we want to store integer id’s in a linked list. A Link will contain a field for an id and a pointer to the next link. To see how it works in practice, let’s look at the picture.
Figure 5. A linked list storing numbers 6, 2 and 1.
The last link in the list has a null (zero) pointer _pNext. That’s the list terminator. A null pointer is never a valid pointer, that is, it cannot be dereferenced. It can however be checked against zero.
source
class Link
{
public:
Link (Link* pNext, int id)
: _pNext (pNext), _id (id) {}
Link * Next () const { return _pNext; }
int Id () const { return _id; }
private:
int _id;
Link * _pNext;
};
|
Notice how the definition of Link is self-referencing--a Link contains a pointer to a Link. It's okay to use pointers and references to types whose definitions haven’t been seen by the compiler, yet. The only thing needed by the compiler in such a case is the declaration of the type. In our case the line
class Link |
A linked List stores a pointer to the first link. Conceptually, a list is a different object than the link. To begin with, it has a different interface. One can add new items to the list, one can remove them. One can iterate the list, etc. These operations make no sense as methods of Link. Yet, in some sense, every link is a beginning of a list. This recursive way of looking at things is very popular in languages like Lisp. We usually try to avoid such recursive concepts in object oriented programming. So for us a List is a different creature than a Link.
Starting from the first link pointed to by _pHead, we can traverse the whole list following the pointers _pNext.
In the beginning, the list is empty and the pointer _pHead is initialized to zero.
class List
{
public:
List (): _pHead (0) {}
~List ();
void Add ( int id );
Link const * GetHead () const { return _pHead; }
private:
Link* _pHead;
};
|
The list has a destructor in which it deallocates all the links. The list owns the links.
List::~List ()
{
// free the list
while ( _pHead != 0 )
{
Link* pLink = _pHead;
_pHead = _pHead->Next(); // unlink pLink
delete pLink;
}
}
|
The algorithm for deallocating a list works as follows: As long as there is something in the list, we point a temporary pointer, pLink, at the first link; point the _pHead at the next link (could be null), which is equivalent to unlinking the first link; and delete this link. The statement
_pHead = _pHead->Next (); |
Again, this is something we wouldn’t be able to do with references.
Figure 6. The unlinking and deleting of the first element of the list.
There is a simpler, recursive, implementation of the linked list destructor:
List::~List ()
{
delete _pHead;
}
Link::~Link ()
{
delete _pNext;
}
|
The recursion stops automatically as soon as it reaches the terminating null pointer.
Simplicity is the obvious advantage of the recursive solution. The price you pay for this simplicity is speed and memory usage. Recursive function calls are more expensive than looping. They also consume the program's stack space. If stack is at premium (e.g., when you’re writing the kernel of an operating system), recursion is out of the question. But even if you have plenty of stack, you might still be better off using the iterative solution for really large linked lists. On the other hand, because of memory thrashing, really large linked lists are a bad idea in itself (we’ll talk about it later). In any case, whichever way you go, it's good to know your tradeoffs.
Adding a new id to the list is done by allocating a new link and initializing it with the id and the pointer to the next item. The next item is the link that was previously at the beginning of the list. (It was pointed to by _pHead.) The new link becomes the head of the list and _pHead is pointed to it (pointer assignment). This process is called prepending.
Figure 7. Prepending a new element in front of the list.
void List::Add ( int id )
{
// add in front of the list
Link * pLink = new Link (_pHead, id);
_pHead = pLink;
}
|
Since the list grows dynamically, every new Link has to be allocated using operator new. When a new object is allocated, its constructor is automatically called. This is why we are passing the constructor arguments in new Link (_pHead, id).
List iteration is simple enough. For instance, here’s how we may do a search for a link containing a given id
for (Link const * pLink = list.GetHead();
pLink != 0;
pLink = pLink->Next ())
{
if (pLink->Id() == id)
break;
}
|
Notice the use of pointers to const. The method GetHead is declared to return a pointer to a const Link.
Link const * GetHead () const; |
The variable we assign it to must therefore be a pointer to a const Link, too.
Link const * pLink = list.GetHead (); |
The meaning of a pointer to const is the same as the meaning of a reference to const--the object pointed to, or referred to, cannot be changed through such a pointer or reference. In the case of a pointer, however, we have to distinguish between a pointer to const and a const pointer. The latter is a pointer that, once initialized, cannot be pointed to anything else (just like a reference). The syntax for these two cases is
Link const * pLink; // pointer to const Link * const pLink = pInitPtr; // const pointer |
Finally, the two can be combined to form a const pointer to const
Link const * const pLink = pInitPtr; // const pointer to const |
This last pointer can only be used for read access to a single location to which it was initialized.
There is some confusion in the naming of pointers and references when combined with const. Since there is only one possibility of const-ness for a reference, one often uses the terms reference to const and const reference interchangeably. Unfortunately, the two cases are often confused when applied to pointers. In this book const pointer will always mean a pointer that cannot be moved, and pointer to const, a pointer through which one cannot write.
But wait, there’s even more to confuse you! There is an equivalent syntax for a pointer to const
const Link * pLink; // pointer to const |
const Link * const pLink = pInitPtr; // const pointer to const |
The source of all this confusion is our insistence on reading text from left to right (people in the Middle East will laugh at us). Since C was written for computers and not humans, the direction of reading didn’t really matter. So, to this day, declaration are best read right to left.
Let’s play with reversing some of the declarations. Just remember that asterisk means "pointer to a."
Link const * pLink; |
becomes Figure 8.
Figure 8. Reading type declarations: pLink is a pointer to a constant Link.
Similarly
Link * const pLink; |
Figure 9. Reading type declarations: pLink is a constant pointer to a Link.
Link const * const pLink = pInitPtr; |
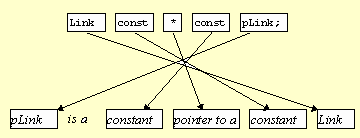
Figure 10. Reading type declarations: pLink is a constant pointer to a constant Link.