Table Lookup
Before explaining how the hash table works, let me make a little digression about algorithms that use table lookup. Accessing a table is a very fast operation (unless the table doesn’t fit in physical memory; but that’s a different story). So, if we have a function whose values can be pre-computed and stored in a table, we can trade memory for speed. The isdigit function (macro) is a prime example of such a tradeoff. The naive implementation would be
inline bool IsDigitSlow (char c)
{
return c >= '0' && c <= '9';
}
|
However, if we notice that there can only be 256 different arguments to isdigit, we can pre-compute them all and store in a table. Let’s define the class CharTable that stores the pre-computed values
class CharTable
{
public:
CharTable ();
bool IsDigit (unsigned char c) { return _tab [c]; }
private:
bool _tab [UCHAR_MAX + 1]; // limits.h
};
CharTable::CharTable ()
{
for (int i = 0; i <= UCHAR_MAX; ++i)
{
// use the slow method
if (i >= '0' && i <= '9')
_tab [i] = true;
else
_tab [i] = false;
}
}
CharTable TheCharTable;
|
Now we could quickly find out whether a given character is a digit by calling
TheCharTable.IsDigit (c) |
In reality the isdigit macro is implemented using a lookup of a statically initialized table of bit fields, where every bit corresponds to one property, such as being a digit, being a white space, being an alphanumeric character, etc.
Hash Table
The hash table data structure is based on the idea of using table lookup to speed up an arbitrary mapping. For our purposes, we are interested in mapping strings into integers. We cannot use strings directly as indices into an array. However, we can define an auxiliary function that converts strings into such indices. Such a function is called a hash function. Thus we could imagine a two-step process to map a string into an integer: for a given string calculate the hash function and then use the result to access an array that contains the pre-computed value of the mapping at that offset.
Such hashing, called perfect hashing, is usually difficult to implement. In the imperfect world we are usually satisfied with a flawed hash function that may occasionally map two or more different strings into the same index. Such situation is called a collision. Because of collisions, the hash table maps a string not into a single value but rather into a "short list" of candidates. By further searching this list we can find the string we are interested in, together with the value into which it is mapped.
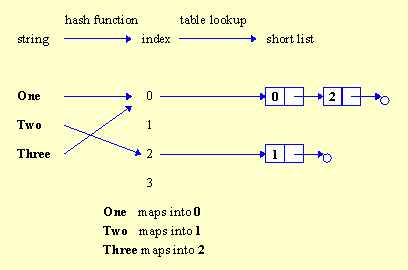
Figure 13. The hash function for the string One is the same as for the string Three. The collision is dealt with by creating a short list that contains the id’s for both strings.
This algorithm becomes efficient when the number of strings to be mapped is large enough. Direct linear search among N strings would require, on average, N/2 comparisons. On the other hand, if the size of the hash table is larger than N, the search requires, on average, one comparison (plus the calculation of the hash function). For instance, in our string table we can store at most 100 strings. Finding a given string directly in such a table would require, on average, 50 string comparisons. If we spread these strings in a 127-entry array using a hashing function that randomizes the strings reasonably well, we can expect slightly more than one comparison on the average. That’s a significant improvement.
Here is the definition of the class HashTable . The table itself is an array of lists (these are the "short lists" we were talking about). Most of them will contain zero or one element. In the rare case of a conflict, that is, two or more strings hashed into the same index, some lists may be longer than that.
source
const int sizeHTable = 127;
// Hash table of strings
class HTable
{
public:
// return a short list of candidates
List const & Find (char const * str) const;
// add another string->id mapping
void Add (char const * str, int id);
private:
// the hashing function
int hash (char const * str) const;
List _aList [sizeHTable]; // an array of (short) lists
};
// Find the list in the hash table that may contain
// the id of the string we are looking for
List const & HTable::Find (char const * str) const
{
int i = hash (str);
return _aList [i];
}
void HTable::Add (char const * str, int id)
{
int i = hash (str);
_aList [i].Add (id);
}
|
The choice of a hash function is important. We don’t want to have too many conflicts. The shift-and-add algorithm is one of the best string randomizers.
int HTable::hash (char const * str) const
{
// no empty strings, please
assert (str != 0 && str [0] != 0);
unsigned h = str [0];
for (int i = 1; str [i] != 0; ++i)
h = (h << 4) + str [i];
return h % sizeHTable; // remainder
}
|
In the last step in the hashing algorithm we calculate the remainder of the division of h by the size of the hash table. This value can be used directly as an index into the array of sizeHTable entries. The size of the table is also important. Powers of 2 are worst--they create a lot of conficts; prime numbers are best. Usually a power of 2 plus or minus one will do. In our case 127 = 27 - 1, which happens to be a prime number.
The hash function of the string "One" is 114. It is calculated as follows
| char | ASCII | h |
|---|---|---|
| 'O' | 0x4F | 0x4F |
| 'n' | 0x6E | 0x55E |
| 'e' | 0x65 | 0x5645 |
The remainder of division of h by 127 is 114, so the id of string "One" will be stored at offset 114 in the hash table array.
Test
This is how we may test the string table:
int main ()
{
StringTable strTable;
strTable.ForceAdd ("One");
strTable.ForceAdd ("Two");
strTable.ForceAdd ("Three");
int id = strTable.Find ("One");
cout << "One at " << id << endl;
id = strTable.Find ("Two");
cout << "Two at " << id << endl;
id = strTable.Find ("Three");
cout << "Three at " << id << endl;
id = strTable.Find ("Minus one");
cout << "Minus one at " << id << endl;
cout << "String 0 is " << strTable.GetString (0) << endl;
cout << "String 1 is " << strTable.GetString (1) << endl;
cout << "String 2 is " << strTable.GetString (2) << endl;
}
|