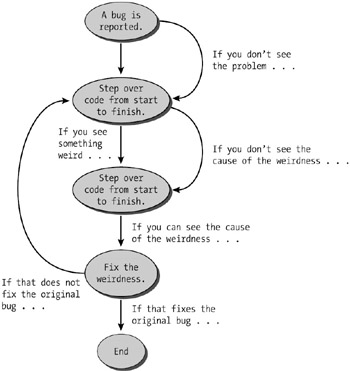
Many developers rely on brute-force tactics when debugging. That involves using the debugger to step across the code from start to finish until you notice something odd. "Wait, that variable looks wrong—how did that happen?" Then you start over and step through the code again, looking for the source of that oddity. When you reach the end and don't see the source of the problem, you start over and step through the code once more. Repeat over and over and over again until finally, "Oh, I see now—the problem is such-and-such. Now how do I fix that?" See Figure 3-1.
Does that brute-force approach sound familiar? Brute force will almost always eventually solve the problem. It's simple enough that you can even do it when you're half asleep on the night before an important deadline. And truthfully, there are times when even the best developers have to resort to brute force because absolutely everything else has failed. But brute force takes a long, long time—too long, for most bugs. Of course, time is no problem if you happen to be a contractor who gets paid by the hour. Salaried employees, however, will want a faster approach.
Something I've learned over the years: When debugging, you should always be in one of two states. You're either testing a theory, or else you're gathering data so you can come up with a new theory. Either way, you should have a clear, specific goal in mind. There shouldn't be any fumbling around randomly. If you have reason to believe a certain function is computing the wrong value, then step across that function, looking at variables to make sure they're OK. If you don't have any good theories, try some experiments to gather more information. "What happens if I run the program with this other input? Does the bug still happen if I comment out this section of code? Without stepping into any of the helper functions, do the return values of each function look reasonable?"
We don't want to try random experiments for no reason. Instead, every test we run should tell us something we can act on. For instance, if our test indicates that the bug consistently occurs with one set of input but not with another, then that gives us some powerful hints about the nature of the problem. We can compare the two sets of input to see if there are any unusual cases we may have forgotten to handle (such as improperly formatted data, data that exceeds a certain range, a set of instructions issued in a different order, etc.).
Obviously, testing a theory is the easy part. If I tell you, "I think the bug is caused by not incrementing the loop counter in this section," then you could easily test to see whether I'm right or not. The hard part is coming up with a good theory in the first place. That's really the key to all of debugging, in fact. Based on the symptoms of a bug, think up a hypothesis that explains the problem, test it, and then fix it. If you're good at coming up with lots of probable hypotheses, then you'll hit on the actual answer sooner and you'll solve your bugs faster. Let's look at some methods for finding good hypotheses.