I had a problem with my cell phone not long ago. Even though I obviously don't have the source code for my phone, I managed to debug the problem without talking to the phone company's technical support. The nice thing about this example is that the lack of source code forced me to debug solely by logical reasoning about the system, and once developers get in that habit of deduction, it's amazing how much more quickly the bugs get solved. Read over the description of my problem and then I bet you'll be able to figure out the bug, too.
| BUG |
My cell phone always displays an icon indicating whether I have voice mail. One day my friend asked why I hadn't returned her message, but I checked my phone and there was no voice mail icon. The next day, I left her a message on her phone, but she never got my message, either. She checked her phone and the voice mail icon showed her mailbox was empty, too. We realized neither of us was getting any of our voice mail messages—people would tell us they called, but when we looked at our phones the icon would indicate our mailboxes were empty. She and I both use the same phone service from the same company. |
What would you do now? How would you attack this problem? If you knew more about how the phone system's software worked, then you might be able to make some initial guesses about the bug's origin, but unfortunately, you don't have that information. Debugging cases without the implementation details of the system is actually very common. Lots of times, you'll get a bug dealing with an API or a third-party component for which you don't have source code, and so it helps to be able to reason about the likely implementation of such systems. Anyway, what's the first step in debugging this problem? What would you do next?
I'll tell you what I did. I believe that in debugging, you should always be either testing a theory or else gathering information to come up with a theory. Let's trace through this bug together—we'll start by gathering information.
The trouble with assumptions is that once you get them in your head, it's difficult to get them out again. Have you ever seen somebody decide a bug was probably caused by one thing, and then spend hours trying to figure out that one area when the problem was actually something completely different? Maybe there was a good reason for the original assumption, but this person failed to notice when new contradictory evidence pointed in a different direction. For instance, in the case of my cell phone problem, maybe there's not a bug at all and the problem is really that I just don't understand how to use the voice mail system. Hopefully, the odds of that are small, but if a 3-hour debugging session can't find a bug, then we ought to challenge our assumptions and consider such possibilities.
So before we dive into debugging my cell phone problem, let's make sure we're not repeating the same mistake here that my install team made with the manual installation of the agents. Let's explicitly state the assumptions we're making for this bug:
The problem is real: Assume my friend and I are telling the truth when we claim to have lost each other's messages. It's conceivable that we're both lying or forgetful.
Assume no one has stolen our voice mail passwords, and that there is a legitimate bug in the system rather than a malicious hacker.
Assume the problem is not deliberate on the part of the phone company. It's at least possible that they turned off our voice mail because (for instance) we each forgot to pay our phone bill.
Actually, any debugging problem requires a nearly infinite list of assumptions. We assume the problem isn't caused by Martians tapping into the phone system; we assume the bug isn't due to cosmic radiation; we assume we haven't been brainwashed by the CIA; and so on. We could never explicitly list all the assumptions for a given situation. That's OK. As long as we try to think of the obvious ones, and we stay open-minded when new evidence comes in about the others, then we'll be fine.
Did thinking about our initial assumptions save us any work? Well, not in this particular case since all our assumptions were correct. But it could have saved us huge amounts of time if our assumptions had been wrong. Imagine how stupid we'd feel if we spent hours debugging this system only to find there really wasn't a bug at all and the missing voice mails were merely caused by a failure to pay our phone bills on time!
It is not necessary to formally write down a list of likely assumptions on every bug, but at least think about possible assumptions. Just spend a few minutes considering if there are any obvious explanations for the bug before doing the heavy lifting of debugging. Only then is it possible to move on to the next step.
I used to be the lead developer on a product that automatically deployed a software agent to every machine on a user-defined list. One of our customers wanted to deploy agents on computers in both America and Japan from a console in New York, but our agent was too large to send over the low bandwidth connection between their American and Japanese offices. So the customer demanded we add the ability to manually install agents on their Japanese machines.
All this happened while I was on vacation. When I returned, I found the install team assuming we had to add support for manual installation of agents. That was what the customer had specifically asked for, after all. Lucky for me, I'd been out of town when that assumption was made, so I immediately asked, "If our product push-installs to computers in a user-defined list, and if the goal is to avoid push-installing over the slow America-Japan connection, then why can't we just install our console on a machine in Japan as well as in America? Let that Japanese console push-install to the Japanese machines, and then uninstall the Japanese console. The agent would then be installed on every machine in both countries, and we wouldn't have to change a single line of code."
And that's exactly what we did. If only the install team had spent a few minutes to think through their assumption that manual installation was necessary, they would have saved themselves a lot of frustration. These guys weren't stupid. They were just stuck on an assumption; in fact, they weren't even aware they had made an assumption at all. That's the power of assumptions. Once you get them in your head, it's hard to get them out. Don't be like that. Recognize when you're making assumptions.
We need more information so we can think of a reasonable theory to test. Once we get to the stage where we have a plausible explanation for the bug ("Maybe the problem is the phone has a weak battery…"), then it's easy to test and, if necessary, fix. If we come up with enough reasonable explanations quickly enough, one of them is bound to hit the target. This is the part most people get stuck on, but it's easier than you might expect. Here's the secret—are you ready for this?
| Tip |
In debugging, we're looking for the point of failure, so we just answer the question, "Everything appears to work fine until WHEN?" |
That'll do it 98 percent of the time. Once we find a point in the system where things are demonstrably wrong, then everything that comes after that point is off the hook and we've narrowed down our search. This is roughly analogous to another debugging trick of commenting out the second half of a function when running your test. If you still see the same problem even when half the function doesn't run, it indicates the problem was at least partially caused by the remaining code. Sometimes, you can use this trick to search your code base for the bug and narrow down the problem to just a few lines.
So what about the cell phone problem? In that scenario, things are working fine until WHEN? Is the problem that the phones aren't actually leaving the message? Are the phones leaving messages correctly but the voice mail system fails to store the messages? Are the messages stored correctly but the phones just aren't retrieving them? Could it be the rest of the voice mail system is working fine and the voice mail indicator icon is broken? We know the steps involved in the process of leaving a message. If we can find the first link in the chain that's clearly broken, we can just ask why that particular link is broken. And it's far easier to think of reasonable theories about the problem in a particular link than it is to find the problem in an entire system.
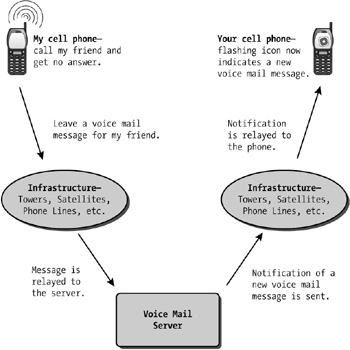
All right! Now we have a goal to shoot for: Find the point of failure. We can just look at each step along the way and try to think of a way to test if that part is working. See Figure 3-2 for a conceptual breakdown of how the phone system works.
One possibility is that my friend's phone is broken. Maybe her phone is failing to transmit the message to the phone company's voice mail server. That explains why I never get her messages. How reasonable does that theory sound? And if it is true, how would we test it? Take a second to think about it. Testing whether the problem is the outgoing message from her phone is pretty easy. We know my phone can't leave her messages either, and our other friends can't leave either of us messages. It seems unlikely that all our phones could break in exactly the same way and at exactly the same time. We can't completely rule out the possibility, but it looks like a safe assumption that the problem isn't in her phone. And by the same logic, assume the problem isn't in my phone, either.
Could the problem be in the satellites and cell phone tower infrastructure? What would be the consequences if that were the case? Presumably, the infrastructure just transmits data. Presumably, it doesn't know or care whether that data is a phone call or a pager message or a voice mail recording. Since I can make regular phone calls with my phone, and even leave recorded messages on my friend's old-fashioned answering machine, we can probably assume the towers, satellites, wires, etc., are all transmitting data correctly.
Besides, if a satellite had gone dark, or a cell phone tower had failed, you have to think the phone company would have noticed. It's too expensive to monitor every individual phone for failure, but you can bet the phone company has an army of engineers constantly monitoring the performance of the multimillion dollar satellites and towers. If there were a problem in this area, every cell phone in the city would be having trouble, and someone would have noticed and fixed the problem already.
Now hold on a second. Did you notice the number of assumptions we just made? We're assuming the phone company is able to quickly fix problems in its infrastructure. Maybe that's not true. And we assumed that if every cell phone in the city were broken, then the phone company would be flooded with service requests alerting them to the problem. That might not be true, either—maybe nobody noticed the phones were broken because people in my city treat cell phones as mere status symbols. And we even made assumptions about the implementation details of the infrastructure. Surely, that's risky. We can't rule out the possibility that the satellite transmits recorded messages on a different wavelength than voice messages, which could potentially explain the bug. Hey, it's possible!
| Tip |
Never hesitate to assume. But always hesitate to completely trust that assumption. |
All our assumptions sound reasonable, but we could be wrong. Is that a problem? Not if we're careful. Assumptions are perfectly fine—we can't get anywhere without them. But just remember that all our logical deductions from this point in the debugging process on are based on premises that aren't 100 percent proven, and if we get stuck, be willing to come back to this point and reexamine our assumptions to see which one no longer fits with the evidence.
Yet for now, let's assume the preceding assumptions are correct. We've ruled out all the major components except the voice mail server. By the "everything is working until WHEN?" approach, we should focus there until we uncover evidence pointing elsewhere. Of course, we should at least consider that the problem might not be in any component. Lots of times, each individual component works correctly but the problem is the interaction between them. This is extremely common in software—two components each work exactly as designed, but the communications interface between them fails to convey some important nuance.
But let's make another assumption and hypothesize that's probably not the case with this bug. The protocols used by cell phones have been fully standardized for two decades, and even if the phone company had changed protocols for some reason, then all kinds of other problematic behaviors would have been reported. Try to think of ways to confirm this theory via testing—I'm sure you can come up with dozens.
So by process of elimination, it appears the bug may be in the voice mail server. We obviously don't know the implementation details—maybe there's a single server or maybe there are several. Maybe the server functions are automated by software, or maybe the "server" is just an army of technicians transcribing all incoming voice mail messages to Post-It notes and sticking them on a giant refrigerator. We don't know any of this. The voice mail server is a pure black box to us, much like an API on a closed-source operating system. We know what it's supposed to do, but not how it does it. But we do know there's a bug somewhere, and to fix that bug, we'll have to reason about the implementation of this black box.
Before we do that, though, let's first recap the state of the bug as a reminder of what we're looking for and to make sure that we're still on the right track. (Remember rule 2 from the previous chapter?) Both my friend and I use the same phone service, and we've both realized we're not receiving new voice mail. Our phones have an icon that should light up whenever we have new messages, but we're both seeing the "You don't have any messages" icon. However, we can make and receive calls, and when we leave voice mail for our friends who use a different phone service, they get our messages.
Momentary pause to think that over…. This reasoning doesn't appear to stray from the primary goal, and nothing in this description indicates an easier alternative solution, so let's proceed with the theory that the problem is in the voice mail server.
Another bug I once saw involved strange behavior with strings. A coworker reported his mixed COM/.NET program crashed with a MarshalDirectiveException when he ran it. When I ran it, there was no crash, but the output string had a dozen characters of unexplained garbage at the end. I didn't have access to the source code, so I couldn't debug properly. But thanks to my experience with COM programming and my ability to reason about the implementation of the system, I had a hunch about what the problem was.
In.NET, there is only one type of string class, and it's easy to forget legacy C++ has dozens of incompatible string types ( char*, wchar*, TCHAR*, CString, std::string, BSTR, CComBSTR, _bstr_t, and so on). But the BSTR is especially important for COM programming. BSTRs are Unicode strings that are prefixed with the length. This length prefix is very important—otherwise languages like VB6 would be unable to read the string. Unfortunately, however, Microsoft's compiler never provided a warning if a non-length-prefixed wchar* was used where a length-prefixed BSTR was expected or vice versa.
My coworker's legacy COM component returned a BSTR to his.NET component. However, he was returning a non-length-prefixed string rather than a properly prefixed BSTR. (He was hardly the first person to make this mistake— millions of COM programmers have done it.) When.NET marshaled the string from the COM component, it expected a length-prefixed string, so unpredictable behavior occurred depending on what the value of the 2 bytes before the string pointer just happened to be. I showed this to my coworker, and a single line change fixed the problem.
Moral #1: When interacting with (or writing) legacy COM components that deal with BSTRs, make sure you are using the SysAllocString API to create real BSTRs rather than simply allocating a standard string.
Moral #2: Once a day, every day, thank your lucky stars that.NET components have only a single string class.
We believe there's a bug in the black box component that we call the voice mail server. We don't know the implementation details, but we do know there are at least three different major functions that the server carries out, so let's conceptually treat those three different functions as different components. The server might not actually be implemented this way; but this is a good way to visualize and reason about it. Once we understand what's probably going on in this component, we'll be in a much better position to think about ways to find and fix the bug. As for me, I thought about the likely implementation of the server and came up with the diagram in Figure 3-3.
Why do I think the voice mail server looks something like that?
First, the messages obviously have to be stored somewhere. Somewhere in the system, there has to be some kind of database or a tape recorder or a secretary with a notepad or a flock of parrots or something to memorize the messages and store them in a place for later retrieval. We don't know the form of this component, but we know something like it has to exist—otherwise, how could the messages be preserved? This component is still a black box, but at least it's a smaller black box than the entire voice mail server, so we should be able to reason about it. Whatever the form of this component, let's call it the data storage object.
What else must logically exist somewhere in the system? Well, my phone has an icon that changes colors depending on whether I have messages in my voice mail inbox. Some part of the server must be responsible for notifying my phone to change the icon. Who knows what the implementation details are? Maybe my phone pings the server every few minutes to ask if there are any new messages. Or maybe the server sends a message to my phone telling it to switch the color of the icon whenever a new message comes in. Either way, this notification functionality has to be handled somewhere. Let's call the component that does this the notification object.
And finally, there is some kind of interface around the data store component to provide routing, security, database querying, etc. When I leave a message for Sally, the message goes in her mailbox, not Harry's. There's security there, too: Some component of the server ensures that only the person calling from Sally's phone can hear her messages. When Harry calls the server, he automatically gets only the messages in his mailbox. And there's a nice little spoken interface on top of each mailbox—"Press 1 to delete this message, 2 to repeat the message," etc. So we're not dealing with raw SQL queries against a database; there's a layer of abstraction to hide the details. All of that functionality has to be handled somewhere, and let's call it the interface component.
Breaking black box components into smaller conceptual components is a powerful trick. But of course there are limits. We could drill down into deeper details for each subcomponent, but at some point, hypothesizing about the details of the black boxes becomes mere guesswork. Already, we've assumed three separate components when maybe two of those components were actually built together in one monolithic database trigger. And even though we've identified three major areas of functionality, that doesn't mean there are just three components—probably the system is far more complex than our diagram shows. So we can't use our logical view of the system to make assumptions about the physical layout.
Still, this not-necessarily-accurate-but-close-enough logical view has already given us something to go on. Now we can come up with theories to test. For instance, is the data store component losing messages? Is the notification component failing to send notifications about new voice mail? Is the interface component sending messages to the wrong mailbox? Supposing that all our assumptions were correct up to this point (always being willing to reconsider this crucial step), then the bug is likely to be found in one of those three areas.
Knowing which area contains the bug may not solve the problem by itself. But it would bring us much closer than we are now. We're dealing with an onion here— keep peeling the layers. When the answers to our questions point to one area, then a whole new set of questions will appear to help narrow the problem even further. Sooner or later, we will find the answer. Right now, we've gathered enough information to ask some very pointed questions, so we're in an excellent position to think of tests to answer those questions.
Could the problem be in the data store component? What kind of problems could there be? How could we test this? If the problem were here, does that imply any other failures we could look for? Let's suppose the data store component is the broken link and proceed from there. Maybe the interface component correctly leaves messages in the mailbox, but the data store has a faulty hard disk or poor programming or something else that results in the message being lost. Or maybe the message is saved correctly, but it's the retrieval that fails. How plausible is a failure here? Could we confirm it with a quick and easy test?
Databases are one of the most mission-critical applications in the world, so for that reason alone, assuming a failure in the data store object is a bold claim. I should hope that whoever designed the phone company's system checked, double-checked, and triple-checked the data store to make sure data would never be lost. In fact, considering how crucial this component is, it's likely the phone company probably used an existing, well-tested database system rather than creating their own. For this reason alone, I'd examine the other components first before spending too much time looking for a bug in this area.
That's not airtight logic, of course. Just because this component is crucial doesn't mean there's no bug here. I'm merely saying that since we have an argument for why the bug is slightly less likely to be in this component than the other components, we might consider investigating those other areas first and only coming back to this if necessary. We haven't ruled this area out. We're just going to follow the most promising leads first before falling back to less promising leads.
Suppose we did that, though. Suppose we ruled out the other components or else found evidence pointing back here. What would be the game plan for finding whether there's a bug in the data store object?
First, ask what could possibly be wrong with the data store. Without going into low-level details, the data store could either be failing to save the voice mails, or else it could be failing to retrieve them. Those are the only two possible symptoms. We just need to figure out if either of those symptoms is occurring.
If this were a traditional debugging situation, then we'd have access to the data store object and could run tests against it directly. Most databases are equipped with tools for viewing (or in this case, hearing) the data, so we could check to see if messages were getting correctly stored. There would probably be a query analyzer, too, for seeing the results of data retrievals. Unfortunately, you and I don't have access to the phone company's data store, so we have to be more indirect in our debugging. What could we do instead? Pretend this was your bug. What would you do here?
A few possible tests:
Even though the voice mail indicator icon says you have no new mail, call in to check anyway. If your mailbox really does have mail in it and if you can successfully retrieve it, then the problem clearly isn't in the data store system.
If there are no new messages in your mailbox, do you have any old, undeleted messages from before this bug appeared? Call the server to listen to those old messages. If this works, then message retrieval is fine and the problem is that new messages aren't getting stored correctly.
Presumably there is some size limit to your mailbox. What happens when you exceed that limit? I don't know, but you might consider leaving yourself hundreds of blank messages—if at some point you're unable to leave that 100th message because the voice mail system says something like "This mailbox is full and can accept no more new messages," then that probably indicates that the messages really are getting stored somewhere.
And what if the problem were in the interface component instead? What would you do to test that one? And what about the notification component? Try to reason about those objects and see if you can think of any good, easy tests. The best tests confirm or deny theories as quickly as possible.
When I was thinking through this problem, I noticed one truth—my test cases for all three components included the simple test of ignoring the voice mail notification icon and calling the server to check my voice mail anyway. That one step would provide information about all three components, so that's the first thing I decided to try.
The preceding cell phone story makes it sound like this was a long drawn-out problem that occupied hours of devoted debugging. Actually, this type of reasoning really isn't that hard. I went through the entire thought process while stopped in a traffic jam for 20 minutes. Debugging is merely logical reasoning, and with practice, most developers may not even consciously verbalize it.
Want to know what the problem with my cell phone was? I decided I should call to check my voice mail even though the indicator icon said I didn't have any messages. That's quick—it'll only take a few seconds, and it would rule out lots of possible theories. As soon as I dialed the number, I heard a prerecorded message from the operator and then I groaned as I instantly realized what the problem was, how it was caused, and who did it.
"Please listen to the following important announcement: Starting November 1st,… [blah blah blah, some boring change in policy]… Please press 1 to acknowledge having heard this announcement."
And then the system declared that I had a dozen new messages and began reading them off. After it was over, I called myself to leave a message, and the voice mail indicator lit up bright red, proving it was once again working. My messages had been saved correctly all along. The problem was just that the notification object was failing to tell my phone I had new messages. All that work for such a simple problem!
Based on your own software experience, do you know how this bug got in the system? I think I can guess. The phone company wanted to make sure every client heard this announcement. So it probably told a system admin to turn on every customer's voice mail indicator icon to make everyone call in to hear the message. But the system admin somehow got it backwards and turned off everybody's voice mail icon until they called in. Then everybody thought they didn't have voice mail, so no one ever called in to hear the new announcement, and that's how my friend and I got this bug.
I can understand how bugs like that could have happened. Programming
SetVoiceMailIndicatorIcon(false);
when you really meant
SetVoiceMailIndicatorIcon(true);
would be an easy mistake—especially if the person who wrote that function didn't clearly document whether "true" meant "on" or "off." Maybe the design was less obvious and the function actually took an integer (0 vs. 1) or perhaps even a bit vector to control several different properties in addition to the state of the indicator icon. Then the likelihood of a bug here would be even higher. I'm surprised the phone company's testing department didn't notice this obvious problem, but I can definitely see how the developer could have been introduced this bug.
Luckily, this bug fixed itself once I heard the announcement. Most bugs take more work to repair, so I got lucky here. But the important thing to understand is that even though no source code was available for this system, deductive reasoning was still possible. If you can do that with a phone system when you don't know the implementation, just imagine how powerful a tool deductive reasoning will be for debugging your own systems.
When debugging, always have a plan.