


Imagine you are a financial wizard and want to store information about your stock portfolio as records. Table 3.1 lists the information. How should these records be stored? The book so far has shown how to store them in
Individual storage elements with individual names
An array, so they can be referenced by position or from a pointer array
Dynamic memory, where they can be referenced by individual pointer variables or from an array of pointer variables
Having more than a few records rules out using individual names, a method that would also be inadequate because it does not allow the records to be treated as a group. The same is true for individual pointer variables.
The other three methods, two kinds of arrays and dynamic memory, allow not only grouping but also selection of records, as well as traversal through all the records. Figure 3.1 represents storage of the stock portfolio in each of these three ways. The three methods are called (a) sequential arrays, (b) sequential pointer arrays, and (c) sequential pointer variable arrays. Collectively they are known as sequential array methods for record storage.
The sequential array methods are convenient for recording the daily transactions common in the buying and selling of stocks, but only when records are kept in arbitrary order. A new record can then be inserted directly as the new last record. This means that in the method of sequential arrays (Figure 3.1(a)), a new record is inserted after Sears. In the method of sequential pointer arrays (Figure 3.1(b)), it can be placed in any unused slot, but the corresponding pointer goes in the seventh position of p. For the method of sequential pointer variable arrays (Figure 3.1(c)), the function malloc provides dynamic storage that is available to store the record, but again, its associated pointer variable value also goes in position 7 of p.
Usually order does matter. In reality the stocks are kept in alphabetical order. In this case the sequential array methods provide neither easy nor rapid insertion or deletion capability for the records. Suppose Chrysler stock is bought, and its new record must be inserted into the portfolio; Chrysler must be inserted in its proper place as the new third record. In sequential arrays this means that all five records below its new position must be moved down. In the two pointer array methods, this means that the five pointers below its new location (position 2) must be moved down. The pointer array methods afford flexibility of record storage position, but they still require shifting, although it is pointers that are moved rather than records. Shifting takes time proportional to the number of records moved. If n records are to be inserted, then the total time can be proportional, not to n, but to n2. For example, suppose the n records each require insertion at the top. Even if there are no records stored initially, insertion of n records requires 0 + 1 + 2 + . . . + (n - 1) moves. The time adds up to n(n - 1)/2, and so the time is O(n2). Even if each insertion requires only half the information to be shifted, the time is reduced merely by a factor of 2; it is still O(n2). When n is large, this can take significant time. Of course, for one trader, n will be small, but for larger brokerage houses n might be hundreds of thousands. If they were not designed to be efficient, these insertions might take hours or even days ((300,000)2 operations X 10-6 seconds per operation = 25 hours).
Selling a stock, say Digital, requires that its record be deleted in the sequential array (a) or that its pointer entries be set to - 1 or null in the pointer arrays (b) and (c). Either course would leave gaps of unused storage, which is undesirable. Leaving gaps soon uses up all the slots in an array, and unless wasting storage is tolerable and affordable, this is impractical. Instead, the gap would be filled by moving up all the records below a deleted record. But again, this could take O(n2) time for the deletion of n records.
What is needed is a way to store records so that their number can grow or shrink in response to an arbitrary number of insertions and deletions, in such a way that storage is not wasted and the time for insertion and deletion is reduced. The list data structure introduced in this chapter provides one solution to this problem. A list is a collection of records linked by pointers. Even with lists, it is still necessary, as with the sequential array methods, for the program to spend time deciding where to make an insertion or deletion in the first place. To make these operations efficient when large numbers of records are involved requires more advanced data structures (introduced later). For a moderate number of records, the time taken to locate the point of insertion or deletion is tolerable. Lists called stacks and queues, where insertion and deletion occur only at the beginning and end of the lists, are especially useful even when there are many records. These will be considered in the next chapter.
Chapter 2 showed that the key advantage of the sequential array methods is selection in constant time. As just shown in this chapter, the disadvantage is that inserting or deleting entries from the interior of an array is costly. Another drawback is that arrays have fixed lengths that must be declared to the compiler. Thus, the maximum number of items to be stored in the array must be known in advance of execution. No such a priori limit need be declared for the number of items on a list. Lists provide a way to insert new items or to delete existing ones at a known point of the list, in constant time. However, selection of an arbitrary ith list item will take time proportional to i.
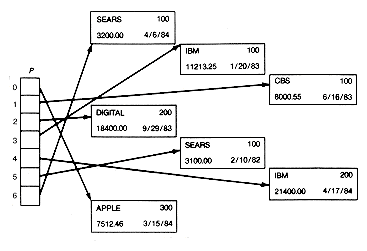
The pointers in lists are what is manipulated by programs, because lists are collections of records linked by pointers. A special element, called the head or name of the list, points to the beginning of the list, and each record in the list has a pointer to the next one. The final record, which has no successor, has an empty link, denoted by a special pointer value called the null pointer.
The stock portfolio example is represented in a list in Figure 3.2. The variable labeled head contains a pointer to the first record in the list. Each record is composed of two fields: 1) an information field, which may itself be made up of subfields such as name, shares, value, datebought (or accountnumber, balance, address); and 2) a link field, which contains the pointer to the next record. The x in the link field of the last record denotes the null pointer and indicates that this is the last record on the list. The list with no records is called the null list, and is denoted by a head containing the null pointer.
It does no good to know that a phone number (say, 642-3715) contains the digits 1, 2, 3, 4, 5, 6, and 7, unless the order 6, 4, 2, 3, 7, 1, 5 is retained as well. Notice that the list data structure, besides being a new way to store information, allows the information to be remembered in a specific order--the order in which the records appear on the list. Arrays provide this ability as well. The order in which records (or the pointers to them) are stored does this, but the operations that make lists interesting and powerful are insertion and deletion.
In effect, a list works as if the pointers from a pointer array were incorporated into the records to which they point. This is the crucial advantage of lists compared to arrays. The price of the added convenience is the loss of the capability to select an arbitrary record. Instead of access to the list records being through the pointer array, the list records must now be accessed via the pointer to the first list record (in head or name). Knowing only the head of a list means that only the first record is immediately visible. To access another list record, the chain of pointers linking list records must be followed until the desired record is encountered.
Consider the simple list l in Figure 3.3(a). Two situations are depicted in Figure 3.3(b,c): (b) is the case when the list head l is known, and (c) the case when a pointer, ptr, to a list record is known. In each case only the record to which the known pointer points is visible.
When only one pointer points to a record, if that pointer value is changed, then the record cannot be accessed. It is as if the programmer had stored something somewhere but had no hope of remembering where. If that pointer happens to be in the head of a list, then access to the list is lost. Suppose the programmer must start with the situation depicted in Figure 3.3(a) and must create two lists. One, l, is to consist of all records of the original list, from the record pointed to by ptr to the last record. Another, newl, is to consist of the original list records, from the first to the record prior to that pointed to by ptr. Simply copying the value of ptr into l creates the correct modified version of l. However, newl cannot be created since the pointer to the original first record that had been stored in l has been lost. Such a predicament must be avoided.
Keeping track of pointers in processing lists is extremely important. One reason is that more than one pointer can point to a record. The only way to see if two pointers point to the same record is to see if their pointer values are equal.
Consider the effects of inserting and deleting on a conceptual list. The effect of inserting a new record is shown in Figure 3.4. The new record is inserted between the records labeled predecessor and successor. This requires changing predecessor's link to point to the new record, and setting the new record's link to point to successor.
The deletion of a record from a list is shown in Figure 3.5. The record labeled removed is deleted from the list by arranging predecessor's link to point to successor. The rearrangement of links for insertion or deletion is independent of where in the list the operation occurs. Each operation can be performed in constant time. Lists, unlike arrays, readily accommodate change; they exhibit no growing pains (or contraction pains).
Suppose you wish to insert a new record for CHRYSLER. It is always a good idea to sketch an image like Figure 3.6(a) to show both the situation at the outset and the situation desired after the task is carried out. Since only the head of the list, stocks, is assumed known, normally each record of the list must be accessed in turn, starting from the first, in order to determine where to make the insertion. For now, assume there is a given pointer predecessor that points to the record after which the new record is to be inserted. In the example, this is the second record. The value of its link field must be copied into the link field of the new record, so the new record's link field points to the successor of the predecessor record. The link field of the predecessor record must end up pointing to the new record, so the value of newpointer must be copied into the predecessor's link field. The code to accomplish this may be written as
where setlink is a function that copies the value of its second parameter into the link field of the record pointed to by its first parameter, and next is a function whose value is a copy of the link field value of the record pointed to by its parameter. Why is it incorrect to interchange these two statements?
Notice that no assumptions have been made about the implementation of the list. The code is thus independent of how the list is implemented. Of course, setlink can be written only when the implementation is known, and it will depend on the details. However, this code will not. The list is thus a data abstraction with insertion as one of its operations; deletion is another.
It is evident that this code is correct for insertion into the interior of the list or at its end. Special cases must always be sniffed out and dealt with. By definition, a special case means a situation requiring code different from the current solution.The existing solution must be modified to handle special cases. The special case here, shown in Figure 3.6(b), represents insertion at the front of the list. Obviously there is no predecessor record, so the solution cannot properly handle this case. It is reasonable to assume that this special condition is represented by a null value for predecessor. Then it is the value of head that must be copied into the link field of the new record. Also, it is the head itself that must receive the copy of newpointer and end up pointing to the new record. The correct function to handle all situations is as follows:
Note: listpointer is a type which is explained in Sections 3.6.1 and 3.6.2.
where setnull returns the null value. What is used for the null value is determined by the list implementation (Section 3.6). When insert is invoked, its actual first parameter, corresponding to phead, must be a pointer to the head of the list. Thus to have insert work on a list l, the call would be insert (&1,predecessor,newpointer). Whenever a parameter of a function must return a value (be modified by the function) the convention in this text is to prefix the name of the parameter in the function definition with a p. Thus, since the value of the pointer to head in insert must be changed, it is referred to as phead. Notice that the code for insert refers to *phead. Think of *phead as another name for head. We say that head has been passed to insert by pointer.
This version of insert is independent of how the list is actually implemented. In practice, insert might be made to execute more efficiently by writing it so that its code does depend on the list implementation. Insert might then be the level at which the list implementation is hidden instead of in setnull, setlink, and next. However, the version above is clearer and can be readily modified if desired.
An alternative that avoids the special case of inserting a new first record assigns a special record, called a header record, to every list as its first record. This record is a dummy record. The dummy is so called because it is not part of the conceptual list of records being created. Used to make processing easier, the dummy record is never deleted, and no record is ever inserted in front of it. Then the special case never occurs, and the original code, requiring no check for the special case, can be used. Actually the header record can be a smart dummy, used to contain important information about the list, such as the number of records. When this alternative is used, the null list can no longer be recognized by a null value in the list head. It is recognized by a null pointer in the link field of the dummy record.
To delete the record following predecessor (Figure 3.7(a)), only the link field value of its successor must be copied into the predecessor's link field:
Thus next (next(predecessor)) is the value that must be copied into the predecessor's link field. It is clearer to write the code as
even if it is slower, requiring an additional memory access. Again, either code is independent of any implementation for the list. After checking for special cases (Figure 3.7(b)), the correct function is found to be
Sometimes, instead of having a pointer to the predecessor of a record to be deleted, only a pointer to the record itself is available. Deletion can still be accomplished; all that is required is to copy the entire successor record (the successor to the record to be deleted, that is) into the record to be deleted. It is necessary to assume, however, that the last list record is never deleted. Why? Whether or not this is better than keeping track of the predecessor depends on how much time is required to effect this copying operation. The larger the record, the greater the time. However, if the information field of a record is kept elsewhere, and a pointer to it stored in the record itself, then the operation reduces to copying just this pointer and the value of the link field.
Are you listing from all this list information?
Traversing a list's records is another operation performed on the data abstraction called the list. Traversal is useful when the records are to be processed one after another in the same order in which they appear in the list. A traversal may be accomplished by following the pointer in the list's head to the first record and processing it, then following the first record's link field pointer to the next record and processing it, and so on, until the last record has been processed.
Example 3.1
Consider the list l in Figure 3.8(a). The task is to write a function reverse, to reverse such a list. This means that when reverse is applied to l, the result should be as shown in Figure 3.8(b).
At first glance, this may seem to be a complicated task involving a great deal of record and pointer manipulation. However, there is a simple solution: the information fields of each record need not be considered at all. Instead, as in Figure 3.8(c), the link field of F can be set to null, the link field of O can be set to point to F, the link field of R can be set to point to O, and so on. Finally, l itself can be set to point to D. The result would be as sketched in Figure 3.8(c), the correct reversed list. This procedure can be stated more generally:
1. Set the link field of the first record to null.
2. Set the link field of each record to point to its original predecessor.
3. Finally, set the list head to point to the original last record.
Even without the details of implementing the list and carrying out the procedure,it is easy to be certain that this procedure, when successfully carried out, does solve the problem. This is so except for the case of a null list; the procedure does not specify what is to be done, since there is no first or last record in a null list. Since the first record of any list has no predecessor, the procedure can be specified somewhat differently.
1. Set the link field of each record to point to its original predecessor.
2. Then set the list head to point to the original last record, or to predecessor if the list is null.
Now we have a procedure that is correct for all cases, the first record's predecessor being assumed null.
The next step is to detail how this procedure is actually to be done. The basic structure involved is a loop, since the same process is to be carried out repeatedly, but on a different record each time. In general, loops need a beginning (initialization) and an end (finalization). The finalization here is specified explicitly in the procedure: namely, set the list head to point to the original last record, or to predecessor if the list is null. The initialization, as usual, cannot be specified until the loop is specified in more detail. Refining task 1 makes the algorithm read as follows:
1. Initialization
While (there is a current record)
a. set the link field of the current record to point to its original predecessor, and
b. update the current record.
2. Set the head of the list to point to the original last record, or to predecessor if the list is null.
To implement the loop requires a pointer (call it recordpointer) to keep track of the current record to be processed within the loop by its loop task. Imagine that the first three records have already been processed correctly and the fourth is about to be processed. It is pointed to by recordpointer, as depicted in Figure 3.9(a).
Processing W requires setting its link field to point to W's predecessor R. To do this requires knowing where its predecessor R is located. Thus another pointer, predecessor, is needed. It is so named because it will contain a pointer to the predecessor of the current record to be processed. (See Figure 3.9(b).)
Suppose someone attempts to process W now, copying predecessor into W's nextpointer field to set it properly. The result is shown in Figure 3.9(c).
Predecessor and recordpointer must now be updated so that they point to W and A, respectively. Then A can be processed next when the loop is repeated. However, the link field of W no longer points to A, but instead to R. Thus the location of A has been lost. Care is required when changing pointer values so that such important information is not lost. To remedy this, introduce another pointer hold in which the pointer to A can be saved before changing W's link field value. The processing of the record pointed to by recordpointer may now be done by sequentially
1. copying its link field value into hold,
2. copying predecessor into recordpointer's link field
3. copying hold into recordpointer.
This produces the result depicted in Figure 3.9(d).
The test or condition for another repetition of the loop becomes (recordpointer ! = null). The initialization involves setting recordpointer to 1, to make it point to the first record, and setting predecessor to null. Why is it unnecessary to initialize hold?
When the loop is exited, predecessor will point to the original last record, and the finalization can be completed by copying predecessor into l. Refining again:
1. Set predecessor to null.
Set recordpointer to l.
While (recordpointer is not null),
a. set hold to the link field value of the record pointed to by recordpointer, and
set recordpointer's link field to predecessor,
b. set predecessor to recordpointer, and
set recordpointer to hold.
2. Set l to predecessor.
This algorithm actually involves a complete traversal through the records of the list l. As it is carried out, recordpointer accesses each record of l in turn and processes it within the while loop. The processing is done by the loop task. In order for the loop to work correctly, some initialization had to be done, and some finalization was required after each record of the list had been processed.
Our intention now is to write a general function traverse, to carry out a traversal of a list, given its head, listname. The code for traverse should be independent of the list implementation, as was the code for insertion and deletion. To make traverse independent of the particular application as well, theprocessing to be done on each record will be functionally modularized in a function process. Its details are thus irrelevant; simply invoke process within traverse. However, to do its job, this function may need access to the list head, listname. It will surely need to know what record it is currently to process; recordprinter will be used to point to this record.
Often, the traversal must proceed through all the list records. To allow for the possibility of a partial traversal, however, a variable done can be introduced. Done may be set by process so that the traversal does not continue beyond the current record. Finally, process cannot retain any information between calls unless that information is kept nonlocal to it, is passed as one of its parameters, or is a static variable. So process is given the parameters listname, recordpointer, done, and other. Other denotes those parameters whose values must be preserved between calls to process.
The heart of a traversal is repeated access of the record pointed to by recordpointer, processing of the record, and updating of recordpointer to point to the next record. Clearly, a loop is its main construct. The function for a general traversal of a list is as follows:
Initialize may be used to set the initial value of any parameters that require initialization. Anotherrecord is a function returning true if recordpointer points to the next record to be processed, and returning false if the last record has already been processed. Finalize is used to carry out any tasks required after all list records have been processed--for instance, to print an appropriate message.
It is a good idea to check a program for correctness, in lieu of a formal proof, by seeing if it handles all special cases (and the typical case) correctly. You should check traverse in this way for the case of a null list, a one-record list, and a list with more than one record. For example, if the list is null, the while loop is never executed as long as anotherrecord is correct (which is assumed), and the program terminates properly as long as finalize is correct (which is assumed). So traverse does work correctly for the special case of a null list.
Traverse has been written in this general way so that it can be used as a tool readily adaptable to the solution of a large class of problems. How to adapt this function to the solution of seemingly disparate problems is the purpose of the next section. It is important to recognize the basic technique used to render the program independent of the list implementation: embedding those details in lower level functions. This is the reason for anotherrecord and next, initialize, process, and finalize; these functions allow traverse to be adapted to specific applications.
All the functions that must reflect implementation and application details in their definitions are lower-level functions. Changes to them do not affect the correctness of traverse, but they do affect what traverse does. The functions call attention to what is being done instead of how it is being done. Furthermore, if the programmer consistently uses a function such as next or process to carry out specific tasks, then no matter how many places the task is required in a program, the definition of that task is localized in one place, and it is clear where to look for the code that implements it. The functions may then all be written independently to suit the immediate purpose. As long as they are correct, traverse must be correct too.
Sometimes a solution to a new problem can be obtained by modifying a known program that solves a related problem. Also, maintenance or adaptation of programs frequently involves small changes to current programs. Changes are easier, quicker, and more likely to be error-free if exactly that function or task that requires change has been localized as a program function.
Traverse adheres to two important elements of programming style.
1. High-level descriptions and programs should be as independent of the details of data abstraction implementation and of the application as possible.
2. High-level descriptions and programs should be functionally modular so that special lower-level functions or tasks carried out within the high-level description or program may be easily isolated.
To illustrate the use of traverse, and the effect of these principles, this section presents four examples. Although each could be solved in isolation, from scratch, a different approach is taken here. In each case it should be easy to see that traverse may be adapted to provide an almost immediate solution. This will be done by writing specific versions of traverse's functions for each application, so that these functions turn traverse into a solution. This means that it will then do the required task when executed. Of course, the functions, when invoked by traverse, will do exactly what the programmer specifies in their definition.
Example 3.2
A sentence is stored in a list, with each record storing one character. Thus the sentence, THIS SENTENCE HAS EXACTLY 60 CHARACTERS COUNTING BLANKS AND., is stored in a list with 60 records. For simplicity, assume the period character "." does not occur within a sentence (as it does in this one). The task is to write a function to print the length of the sentence.
The solution can be achieved by traversing the list and counting the number of records. Initialize can set a counter, length, to zero, and process can increment it by 1 each time it is invoked. Finalize can do the printing. The functions are readily defined.
Either anotherrecord and next must be supplied to the programmer, or the details of the list implementation must be specified such that the programmer can write them. The task of the example is then carried out by the invocation traverse (sentence). In this example traverse must be modified to the following function.
There are two ways to view traverse. One is as a program that can be used but not modified in any way. This would require that the functions be written as they appear and the type moreparameters be declared prior to traverse. The second is as a program that may be used or changed in any desirable way. In this case, for clarity, the function names can be changed: traverse to countcharacters, initialize to zerocounter, process to incrementcounter, finalize to printcounter, and anotherrecord to anothercharacter, for example. It may be desirable to remove parameters that are not needed. Since listname is not needed by initialize, process, or finalize, and recordpointer is not needed by process they may be omitted from the definitions and invocations of these functions. Other may be changed to length. Finally, done may be eliminated, since it is not needed. Having made this distinction, the programmer is free to take either view, or a view that falls between the two. The one chosen should be clear from the context.
Suppose the sentence were stored in the list with three characters per record instead of just one per record. The solution would require a new version of process to reflect this change, but initialize and finalize remain as is. Next might have to reflect the new record format. The new process is
where char1 returns a copy of the first character in the record pointed to by its parameters, and char2 returns a copy of the second character in the record pointed to by its parameters. Like next and anotherrecord, they must be supplied, or the programmer must write them given list implementation details.
Finally, suppose the list is implemented as a circular list (Figure 3.10). In circular lists, the null pointer of the last record is replaced by a pointer that points to the first record. To illustrate the difference in the implementations between a standard list and a circular list, the two distinct versions required for anotherrecord are presented.
Standard List
Circular List
Actually, the solution is not as general as possible. Suppose the list were implemented using a dummy header record. Then process must recognize when it is processing this record (the first) and not change length, since no characters are stored in the header record. You should modify process to account for this possibility. It is necessary to assume that the header may be distinguished from the other records in some way.
Example 3.3
Earlier in the chapter a way to reverse a list was developed from scratch. We now build a program to reverse a list utilizing traverse. Traverse may be turned into a solution for the list reversal by defining initialize, process, and finalize, as follows:
Notice that the parameter of traverse is now a pointer to the listname. This is necessary since listname may need to be changed by traverse. Here process works on the record preceding the record pointed to by recordpointer, while the original solution worked on the record pointed to by recordpointer. This was necessary because that solution changed recordpointer's link field before updating recordpointer.
Example 3.4
Insert a new record into a list stocks, which is kept in alphabetical order by name. Assume the data for the new record may be accessed by a function getnextrecord, which returns a pointer to the new record.
To turn traverse into a solution requires simply that process compare the new record's name field value with that of the current record. If it precedes the current record's name field value, it must be inserted before the current record and done set to true. To make the insertion conveniently, a pointer, predecessor, to the predecessor of the current record will be kept by process and updated each time process is invoked. Initialize must allocate storage for the new record, set its data field values, and set predecessor to null. Assume that a function avail is given, returning a pointer to a storage element that may be used to store the new record. Finalize must insert the new record in the event that the list is null. The solution for these functions follows:
where setinfo copies the contents of the record pointed to by its second parameter into the information field of the record pointed to by its first parameter, so it depends on the list implementation details.
where precedes returns true if its first parameter points to a record whose name precedes, in alphabetical order, the name in the record pointed to by its second parameter. To insert a new record, invoke traverse (&stocks). However, traverse must be modified in a way similar to Example 3.2 as follows. A better name for this modified traverse would be orderedinsert, so we use it.
Suppose you wanted to insert the new record into a list of stocks kept in order by date bought, instead of by name. Rather than keep another list distinct from stocks, you could add another link field to its records. Call it the datelink field, and assume each record's datelink field points to the correct successor as in Figure 3.11. Stockdate is a new head, pointing to the first record of that list when date bought is used as the criterion for ordering.
To solve this problem: 1) define precedes so that it compares dates instead of names; 2) replace each reference in insert to the setlink function by a reference to the setdatebought function and define it to work on the datelink field instead of the link field; and 3) redefine next to return a copy of the datelink field of the record pointed to by its parameter. A call to orderedinsert(&stocksdate) then carries out the task.
Example 3.5
Create a list stocks, to store a portfolio of stock records.
To solve this problem, assume the data are already stored on some input medium and getnextrecord gives access to each record in turn, as it is invoked. The desired list may be created by traversing the records stored on the input medium. The job of process is to fill in the information field of the storage allocated for the new record, and fill in the link field of the new record with a pointer to storage allocated for the next new record. However, it is assumed that the last input data is a sentinel value that indicates there are no more records. When the sentinel is input, getnextrecord returns a null pointer value. Consequently, process must first check for this case and, when it occurs, simply return after setting done to true and the link field of the predecessor of the new record to null, unless the list is null. If it is null, process must set done to true and listname to null. Initialize must allocate storage for the first record and set listname to it. Finalize is not needed. We have
Invoking a correctly modified traverse(&stocks) creates the list. Notice that this traverse will copy a list whenever getnextrecord obtains its information from the next record of the list to be copied. A better name for this function would be readlist or copylist. At this point you may want to see a complete program that creates the stocks list and also prints it. The program is in Section 3.6.1.
Suppose the records are given in arbitrary order, but the stocks list must be created with the records appearing in alphabetical order. To turn traverse into a solution to this problem, initialize, finalize, and anotherrecord are not needed; neither are the variables recordpointer and other. This problem is solved by the following version of traverse, which we call expand. The name expand was chosen because, when called to work on an existing ordered list, it simply expands the list by adding the new inputs to the list in the proper places. When the call expand(&listname) is made with listname set to null, it creates the ordered list.
Notice that expand has no need for the functions initialize, finalize, and anotherrecord, nor for the variables recordpointer and other.
Processrecord must obtain the next input record and insert it in the list at the correct place. It invokes insertinorder, which has the task of creating and inserting the new record into its proper place in listname; pointer points to the record whose content is to be placed in the new record's information field. Insertinorder itself requires a traversal of listname. The version below is a modification of orderedinsert, obtained by adding a second parameter, pointer. Orderedinsert uses getnextrecord to obtain the next input record and then inserts it, while insertinorder is given a pointer to the new record and needs only insert it. The additional task of obtaining the new input record is handled outside of insertinorder. Consequently its process and finalize functions can be used directly in insertinorder. Only its initialize function needs changing, but all are given below for easy reference.
It is very important to recognize that traverse of Section 3.4.2 is a tool that could be used in solving the example problems. The tool was applicable because
It was written using data abstractions that allowed writing or using required implementation functions without changing traverse.
It was written using functional modularization, which allowed isolation of functions for relevant tasks so that they could be written to satisfy specific needs.
Recognizing and applying tools is a major aspect of programming methodology. For a tool to be convenient to use, it must be written according to the two elements of programming style just stated. Of course, in the simple examples using the tool may not save much time, effort, or cost, but for complex tasks the savings can be great.
Note that the use of getnextrecord makes the solutions to Examples 3.4 and 3.5 independent of the input medium or the format of the input. Thus any changes in the input are not reflected in traverse; only getnextrecord and SENTINEL can require modification. In fact, the same should be done for any output. It is better to use a function rather than specify input and output in the basic functions, in case the input or output medium is changed.
So far this chapter has covered lists in the abstract. Lists are implemented in two basic ways, differentiated by where the records of the lists are stored: 1) in an array of records or 2) in dynamic memory. These are similar, but dynamic memory allows for more efficient use of storage and is easier to use.
The simplest implementation is to store all list records in the dynamic memory. The declarations required are illustrated below for the example of the stock portfolio. For storage in dynamic memory, the records of a list are defined as usual, and an additional field is added to contain the link field pointer. Since it will point to a successor record stored in dynamic memory, it must be defined as a pointer. In this case, the null value for a pointer is always given by the value , with having the value 0. Variables of type listpointer will contain pointers to records of type stockrecord.
The following complete program reads in and creates a list of stockrecords as in Example 3.5 and, in addition, prints out the information fields of the list records. Both the creation and printing portion of the code are appropriately modified versions of traverse. The initialize and process functions of Example 3.5 are used in the creation portion, but process has been given the name addrecord. The program treats the list as a data abstraction. The data abstraction list, with its allowed operations--next, setlink, setinfo, avail, anotherrecord, getnextrecord, and printrecord, appear together in the program.
Typical input to the program is shown in Table 3.2.
The program that follows reads in the records of a list, creates the list, and prints the records in the list.
Instead of being stored in dynamic memory, list records may be stored in an array of records. The declarations required are illustrated for the example of stocks.
For this implementation the null pointer value is -1. Here, variables of type listpointer contain integer array indices. The implementation for some of the functions operating on the list are
This implementation assumes that records is declared nonlocally to these functions, so that they may reference it. With this implementation, the records array plays the role of the dynamic memory. It is necessary to write an avail function that must keep track of those slots in records that are not in use, and hence can be allocated when storage for a list record is requested.
In some languages, such as FORTRAN, there is no dynamic memory, nor are there pointer variables or records. In such a language, the records themselves must be implemented by the programmer. They may be stored in single or multiple arrays, as discussed in Chapter 2. Since the list records now have an additional link field indicating their successor, they need not be stored sequentially and may be located anywhere in the array or multiarrays, as long as they do not overlap. An additional variable is needed for the head of the list. Once these arrays are set up, the programmer may write functions to access each field of a record and functions to copy one record's value into another record, or to copy a record's field value into another record's field. These might include
next(pointer)
Returns a copy of the link field value of the record pointed to by pointer.
setlink(pointer1,pointer2)
Sets the value of the link field of the record pointed to by pointer1 to pointer2.
setlinfo(pointer1,pointer2)
Sets the value of the information field of the record pointed to by pointer1 to the value of the information field of the record pointed to by pointer2.
In FORTRAN, the array or multiarray in which the records are kept could be declared to be stored in the FORTRAN common area or else must be passed as parameters to these functions. Once they are written, for all intents and purposes the language has records. These records can be accessed, copied, or modified by using these functions. Although the programmer must do all this work initially, from this point on the situation is conceptually the same as in Section 3.6.2. That is, the actual implementation of the records may be forgotten; they are treated as if stored in an array of records, just as in C. The problem of writing an avail function still remains, and it is addressed in the next section.
In FORTRAN, although storage for records kept in lists must be managed, the programmer does not need to manage storage for individual elements or for arrays of elements. To refer in a program to an element n, or an array data, simply declare n to be an element, and data to be an array. Then use the operations available in FORTRAN to enter specific values into n or data. This works because individual elements and arrays are data structures directly available in FORTRAN. Lists, on the other hand, are not directly available and must be built up explicitly by storing their records in arrays. Consequently, the programmer must determine where storage is available to create a record when the need arises.
In C it is not necessary to implement records of lists explicitly in arrays. Instead, dynamic data structures may be used. A data structure is dynamic if it is built during execution of a program and storage is allocated for its components at that time. Dynamic data structures are built simply by asking for storage to be allocated for a record in dynamic memory. A pointer will then be assigned to point to that storage. Using the pointer, appropriate values may be assigned to the fields of the new record. These fields may be referred to directly, using naming conventions in the language. Special functions to store or access information from the fields of the record need not be written.
Records still need to be inserted properly in a dynamic data structure. Commands directly available in the language may be used to create or reclaim records, or reclamation may be left to the implicit storage reclamation provided by the language. Thus the definition, creation, reclamation, and manipulation of dynamic data structures become easier.
Keeping track of and allocating storage that is needed during the execution of a program is called dynamic storage management. In some languages, notably FORTRAN, storage for arrays is allocated before the program's execution, and no dynamic storage management is present. In languages like C, storage is allocated to the local variables of a function at the start of its execution and remains assigned until the function (or block) completes its execution. The space can then be reassigned to the next executing function (or block). In effect, it disappears. This is why values of local variables are not preserved between invocations of a function, unless they are declared as static, in which case they are preserved between calls. Management of this storage during the execution of a program is not what is meant by dynamic storage management. Contrast this situation to dynamic memory, which is assigned or taken away from records in dynamic memory during the execution of a function itself. This captures the true flavor of dynamic storage allocation.
If the array in which records are to be kept (as in Sections 3.6.2 and 3.6.3) is to function as dynamic memory, then allocating storage in the array for a record requires dynamic storage management. In fact, this amounts to an implementation of a C-like dynamic memory. Although storage can thus be managed explicitly for a specific program, dynamic memory can manage storage for many programs and is hence more efficient use of storage. The difference is that one large array may function as storage to be used by all the programs, instead of dedicating separate smaller arrays to each program.
Why is storage efficiency important? Why not find storage for a new record in the array simply by placing it sequentially below the last new record's storage? After all, this would be very easy to do and would certainly use the storage as efficiently as possible. The answer is that this simple solution is a great idea--provided that all the storage needed for the array to be of sufficient length is available. The catch is that this proviso is rarely the case. Often, the amount required isn't known in advance; even when it is known, not enough storage may be available.
Reconsider the prime number example of Chapter 1. It is probably evident by now that the list is a good data structure to use for collection. The program to generate all the primes between 2 and n uses very little storage besides that needed for the list, but how large should you make the array in which to store the list? It is possible to modify the program so that it need not actually store all integers between 2 and n in the list, but only those that are prime. Still, how many primes are there no greater than n? It is even possible to write such a program so that it efficiently generates and prints all primes
Suppose you are a programmer asked to store the contents of ten manuscripts in ten lists. If each can have a maximum length of 50,000 words, then storage for 500,000 words is needed. How long is the longest word? You see the problem. Even if the amount of storage could be estimated, sufficient storage may not be available. You might conclude that the task cannot be done, or you might use secondary storage (magnetic tape, disks). However, in secondary storage access is relatively slow, and it requires techniques different from those described so far. One possibility remains. Maybe the manuscripts to be stored, perhaps even more than 10, are compatible (in the sense that they are not all of great length simultaneously). Perhaps the lengths will vary as the manuscripts are processed by a program, so that at any one time the manuscripts being stored can fit. This means that they may be growing and shrinking in length at different points in the program. If the storage no longer needed for one manuscript is relinquished and reused for another, then the total array length may not ever be exceeded. In other words, if storage can be allocated, then reused for new allocations when no longer needed for its original purpose, problems may be solved that are otherwise out of range. This is the reason to manage storage.
This also explains why dynamic memory makes better use of storage than individual program management using arrays of records. Each program may, to ensure its execution, ask for a large amount of storage to be used for its array. The total amount needed by all the programs may not be at hand. It is better to take all available storage and dole it out to each program as needed, the hope being that whenever some programs need a great deal of storage, the others need little. Instead of dedicating amounts to each user for each one's worst case, the programmer manages the storage and gives out only what is needed at any moment.
Having taken this relevant digression, let's return to the job of managing dynamic memory. This will show how dynamic memory itself might function, and give us the means to create our own when desirable. In fact, you will see when this might be advantageous.
Pointers are used in C to eliminate the problem of dynamic storage management for the programmer. Pointers allow the declaration of a variable of a complex data type and allocate storage for it by merely assigning to its pointer a value that points to that storage. The C function malloc is used for this purpose. This section develops a function avail that will have the same effect as malloc but will manage storage in the records array for Section 3.6.2.
In the general case of list processing, records need to be inserted in and deleted from lists. It is deletion, you may recall, that makes the solution of larger problems feasible. When records are deleted, their storage in the records array may be reused. Reclaiming storage in this way allows larger problems to be solved than would otherwise be possible, by allowing the program to execute to completion.
Records of one or more lists may be stored in the records array at any moment during the execution of a program. Assume that all these records have the same length, and that no sharing of storage occurs. No sharing means that no list record has more than one pointer to it at any time. The more typical case of variable-length records and sharing of storage is more complex and will be dealt with in a later chapter. The issue is now how to implement avail.
Suppose that, by looking at a record, you can tell whether or not it is in use. This would be the case if, whenever a record were deleted from a list, it were marked unused. An available record could be found by traversing the records array until a record marked unused were found. Avail could then return a pointer to that record, after marking it as now in use. In Figure 3.12, this would require the first three records to be accessed before avail could return to point to position 2. The time to carry out this procedure is proportional to the length of the records array in the worst case.
A very significant improvement would be to keep track of the available records so that the search may be avoided and the time for avail to do its task reduced to a constant. This is achieved by using the link fields of each unused record to create a list of available records. Initially all entries of records are unused, so the list should contain every record of the array. Figure 3.13 shows how this list might appear for the configuration of Figure 3.12, with availist taken as its head. Avail now carries out its task by simply deleting the first record from availist and returning a pointer to the deleted record. This yields the desired constant time for avail.
When records are deleted from a list in programs, it is convenient to keep track of their storage for future use. This requires inserting the deleted records' storage on availist. Again, this operation can be done in constant time if the newly available record is inserted at the front of availist--as its new first record. The function that carries out this task will be called reclaim. What time is required for insertion if the record is inserted in the list other than at the front?
The programmer invokes p = avail() to request storage for a record to be stored in records, and p points to that storage when avail returns. The programmer invokes reclaim(p) to request that the storage in records pointed to by p be inserted on availist. By employing avail and reclaim appropriately, the programmer can dynamically allocate and reclaim storage for lists. This means that records can be viewed as the repository of all list records, thus acting as a miniature dynamic memory. Such routines are the heart of storage management algorithms. When the records of a list are not all of the same length, more complex management techniques must be used. When records can be shared, still more complexity is added to the storage management problem, as will be illustrated subsequently.
Malloc is the general C allocation function provided for the programmer's use, so that dynamic memory appears as an abstract facility for storing records. When no memory is available to be allocated, malloc returns a NULL value. Consequently, on each call to malloc the value returned should be checked to be certain it is not the NULL value. Avail may be written to abort or take whatever action is necessary for your application in the event memory is not available.
The C function free is provided to carry out the general task of reclaim. Free deallocates memory that was previously allocated by malloc. The argument to free has to be a pointer previously returned by malloc that has not already been freed. Once memory is freed, it can be used to satisfy new requests through malloc.
In languages such as FORTRAN, which do not provide dynamic memory, you can implement it through avail and reclaim. Once avail and reclaim are written, for all intents and purposes the language has dynamic memory for record storage. You have tailored it to your needs.
Arrays allow records to be stored contiguously and to be accessed randomly. With pointer arrays, random access is possible even for variable-length records. Lists are also data structures containing records. Lists provide the flexibility, when needed, to separate records--enhancing the ability to insert or delete, but reducing the capability of accessing records at random. Stored records can be traversed using either the sequential array or list implementation. The time to carry out the traversal need not be significantly different for the two methods.
Suppose that instead of processing the records in sequential order, as in a traversal, your program must access the records in arbitrary order. (In an airplane reservation system, for example, seat reservations must be processed immediately, in random order.) Having to access the records in arbitrary order means that the program must access and process the records even though the programmer cannot predict the order in which this must be done. The sequential representation, because it allows selection for fixed-length records, allows this random accessing to be accomplished in constant time. The list representation requires that random accessing be done by traversing to the needed record, starting from the first and accessing each succeeding record until the desired one is reached. If the required record is the ith, traversal will take time proportional to i. Thus randomly accessing records takes constant time for each record accessed with the sequential implementation, but time proportional to the desired record number for the list representation. This can result in significantly greater processing time for the list implementation when you are randomly processing records.
To insert one record in the collection (say, after the ith record) when using the sequential implementation, all succeeding records (the (i + 1)th, (i + 2)th, . . . , nth) must be moved down in the data array. This operation will take time proportional to the number of succeeding records (n - 1). Adding a record as the new first record gives the worst-case time, which is proportional to n. Inserting a new record using the list implementation, again assuming you have determined where it is to be inserted, takes a constant time--the time needed to change two pointers.
To delete one record, say the ith, using the sequential representation, requires that the succeeding i - 1 records be moved up. Thus the time required is proportional to i - 1. Using the list implementation requires a constant time for this deletion--the time needed to change one pointer. The time for deletion with a sequential implementation in the worst case is also proportional to n. It is obvious that insertion and deletion of one record can result in much greater execution time for the sequential implementation as compared to the list implementation.
The contrast is especially striking when record accesses, insertions, or deletions are performed on m records. The worst-case time to randomly access an entire collection of m records becomes proportional to m and m2, for the sequential and list implementations, respectively. For random insertions and deletions, these are reversed in favor of lists. This means that if m is doubled or tripled, the respective times increase fourfold or ninefold instead of merely doubling or tripling.
When selecting an implementation, the basic considerations are comparative execution times and relative frequencies for random access, insertion, or deletion.
The list implementation will require at least as much memory as the sequential implementation. For instance, if each record requires one element for the information field, and the list implementation requires another element for the link field, then lists would require twice as much storage. It is possible that part of the storage used to implement a record would be left unused in any case, so that using it for the link field requires no extra storage.
Consider two sequences of numbers that are ordered, largest to smallest:
100 80 65 30 90 85 50 10
They may be merged to produce a new sequence containing all the numbers in order. For example, compare the two largest and place the larger one first in the final sequence. Continue comparing the two current largest and placing the larger in the next spot in the final sequence until all numbers have been placed. The result, of course, is
100 90 85 80 65 50 30 10
This merging algorithm takes 2n basic operations when there are n numbers in each original sequence. It is possible to merge the sequences using a different algorithm, which, when parallel processing is possible, can reduce the time to O(lg 2n) rather than O(2n) when n is a power of 2. It is not obvious how to do this. The solution involves
1. A "perfect shuffle" operation, for which we next develop a program
2. A compare-and-exchange operation, which we will discuss after the perfect shuffle
Using gambling terminology, a perfect shuffle of 2n cards occurs when the deck of cards is split into two halves and the shuffle interleafs the two halves perfectly. An original configuration of eight cards, with the configurations after two consecutive perfect shuffles, is shown in Figure 3.14 The cards are numbered one through eight. A third perfect shuffle would produce the original configuration.
Suppose a sequence of perfect shuffles is made for 2n cards. Eventually the original configuration must reappear. How many shuffles will it take before this happens? One way to find out is to execute code that performs such a sequence of shuffles, keeping track of how many are made, and printing this total when the original configuration occurs again. A program segment to do this can be written as follows:
Initial initializes configuration. Original returns true if configuration is the original, and false otherwise. Perfectshuffle changes configuration so that it reflects the new configuration resulting from a perfect shuffle. As written, this code is independent of how the configuration is actually implemented.
Suppose we decide to implement configuration as an array and use n as a pointer to the card in position n. Then initial and original may be defined, respectively by
and
Perfectshuffle is somewhat more complex. The first and last cards, 1 and 2n, never change position in configuration. After the shuffle, cards 1 and n + 1, 2 and n + 2, 3 and n + 3, . . . , i and n + i . . . , and n and 2n will appear in consecutive positions in the resultant configuration. An array, result, is used to hold the new configuration. In traversing the relevant n positions of configuration (the 0th is ignored), its ith entry is processed by copying configuration[i] and configuration[i+n] into their proper new consecutive positions in result. I serves as a pointer to the current entry of configuration being processed, and newi will point to the new position of that entry in result. The situation, when n is 6, is depicted in Figure 3.15(a) just before the fourth entry is to be processed.
If the following statements are executed
then the program will have properly processed the ith and (i+n)th cards. It will also have updated i and newi so that they are pointing to the proper new positions, in configuration and result, respectively. The situation after the fourth element has been processed is as shown in Figure 3.15(b).
To complete the shuffle, result can be copied into configuration. A program segment for perfectshuffle might be as follows.
Notice that the solution involves a number of array traversals, each traversal processing accessed elements in a different way.
Suppose you decided to implement configuration as a list of records stored in dynamic memory, and to use n as a pointer to the nth record of the configuration list. Figure 3.16 depicts these assumptions graphically for ten cards.
Perfectshuffle must, consecutively, move 6 before 2, 7 before 3, 8 before 4, and finally 9 before 5. Two pointers, l1 and n, are shown in Figure 3.16. Traversing configuration and processing the records pointed to by l1 and n will accomplish the movements, if the processing deletes the successor of the record pointed to by n, inserts this deleted record after the record pointed to by l1, and updates l1 to point to it. Move carries out this processing task.
Perfectshuffle may now be implemented by
Perfectshuffle in this form is a refinement of traverse. Move plays the role of process. It uses local variables hold1 and hold2 to keep track of the successors needed:
Two complete programs that output the number of shuffles are presented at the end of this paragraph. The first is based on an array, and the second on a list implementation. In this case there is nothing to recommend the list implementation over the array implementation, since the configuration does not grow or shrink (except for the artificial limit on the array size that would be required by the array implementation). The two versions of perfectshuffle are both useful for the application to which we return in the section that follows the programs.
Array Implementation
List Implementation
Now that the perfect shuffle has been developed, let's return to the merging of two sequences. Set the first n entries of configuration to one of the sequences to be merged, and the second n entries of configuration to the other, but enter the second in reverse order.
Consider the following algorithm for merging two sequences of ordered (largest to smallest) entries, each of length n:
Apply perfectshuffle and compareexchange to configuration a total of 2n times.
Compareexchange is a function that compares each of the n pairs of adjacent configuration entries and exchanges their values whenever the second is larger than the first. Table 3.3 shows the results obtained as this algorithm is applied to our sample sequences of length 4. Since lg 2n = lg 8 = 3, the algorithm terminates after the third perfect shuffle and compare-and-exchange operation. Notice that this results in configuration containing the correct merged sequence.
When 2n is a power of 2, say 2k, then the k iterations always produce the correct merge. This is certainly not obvious, and it is not proven here, but one point is important. If this merge is implemented as a for loop and carried out conventionally (that is, sequentially), it will take time O(n lg n). The straightforward sequential merge discussed earlier takes only O(n) time. However, if the n moves of perfectshuffle and the n pair comparisons and interchanges of compareexchange are all done in parallel (at the same time), then the total time will be just O(lg n).
Parallel processing is beyond the scope of this text, but this application illustrates its power and some of the difficulties involved. Doing parallel processing correctly is tricky, since care must be taken to do the right thing at the right time. For instance, one could dress in parallel fashion, but certain constraints must be observed. Socks and shirt can be put on at the same time (a valet is needed of course, since a person has only two hands) followed by pants, with shoes and jacket next and in parallel. But shoes cannot go on before socks.
The perfect shuffle (and the topic of parallel processing) is pursued further in Stone [1971, 1980] and Ben-Ari [1982]. An application of these ideas to the stable marriage problem appears in Hull [1984].
1. What record of a list has no pointer pointing to it from another list record? What record of a list has a null pointer in its link field?
2. If each record of a list has, in addition to its information and link fields, a "pred" field, then the list is called a two-way list. The pred field contains a pointer to the preceding record. The first record's pred field contains a null pointer. Write insertion and deletion functions corresponding to those of Section 3.3 for a two-way list.
3. A circular list is a list whose last record's link field contains a pointer to the first list record rather than a null pointer. Write insertion and deletion routines corresponding to those of Section 3.3 for a circular list.
4. Modify the solution to Example 3.1 so it is correct for
a. two-way list
b. A circular list
5. Write a function to interchange the records of a list that are pointed to by p1 and p2.
6. The solution developed for Example 3.1 essentially cycles pointers from one list record to the next. Instead, a solution could cycle information field values from one record to the next. Modify the solution so that it does this and compare the two execution times. What if the information field contains only a pointer to the actual information field value?
7. Consider the three arrays below--data, p, and s.
An ordering of the integers in data is specified by p and by s . Arrays p[i] and s[i] point to the predecessor and successor of the integer stored in data[i]. A minus one indicates no predecessor or successor. Assume the first i elements of data, p, and s are properly set, as above, to reflect the usual ordering of integers. Suppose a new integer is placed into data[i+1].
a. If i is 10 and the new integer is 15, what will the new p and s arrays be after they are properly updated to reflect the correct ordering among the eleven integers? The data array, except for 15 being placed in position 10, is to be unchanged.
b. Write a program segment to update p and s after a new integer is placed in data. You might want to assume that first and last point, respectively, to the element of data containing the first and last integers in the ordering.
8. a. What does traverse (Section 3.4) do when process interchanges the record that recordpointer points to with its successor record?
b. Same as Exercise 8(a) except that, in addition, process then sets recordpointer to the link field value of the record to which it points.
9. Write a function to delete all the records from list l1 that also appear on the list 12.
In Exercises 10-13 you must turn traverse of Section 3.4 into a solution to the exercise by defining its functions properly.
10. Write a function to delete all duplicate records from an alphabetical list such as that of Example 3.4.
11. Write a function to insert a new record in front of the record pointed to by ptr. You should not keep track of a predecessor nor traverse the list to find a predecessor. A "trick" is involved here (see Section 3.3.4).
12. This is the same as Example 3.4, but assume the list is implemented as a two-way list.
13. Create a new list that is the same as l except that each record has been duplicated, with the duplicate inserted as the new successor of the record it duplicates.
14. Create a list l that consists of all the records of the list l1 followed by all the records of the list 12.
15. Write a function to print out the number of words for a list such as that of Example 3.2.
16. Write the required functions for traverse of Section 3.4 when list records are stored in dynamic memory and the list is implemented as
a. A two-way list
b. A circular list
17. A hospital has 100 beds. The array records contains records that represent, by floor and bed number, those beds that are not occupied. The first, second, and third elements of a record contain the floor number, bed number, and link value, respectively. How many beds are not occupied and what is the lowest floor with an available bed?
18. Change the appropriate pointers for Exercise 17 so that the records are kept in order by floor and bed number.
19. Show what the arrays floor, bed, and next might have in their entries if the beds list of Exercise 17 were implemented using three corresponding words of these arrays.
20. How would the records array of Exercise 17 change if bed 2 on the fifth floor became occupied?
21. Suppose bed 10 on the sixth floor became empty. Assuming that the records array is used only for the beds list, what changes might be made to it to reflect this new information?
22. This is the same as Exercise 16 except that the list records are stored in an array records .
23. A palindrome is a sequence of characters that reads the same from front to back as from back to front. ABCDDCBA, ABCBA, and NOON are palindromes. Write a function palindrome to return the value true if the list it is called to check represents a palindrome, and the value false otherwise. The list records are stored in dynamic memory.
24. Suppose four records, 13, 7, 1, and 2, were deleted from lists whose records are stored in records of Figure 3.13. Then three records were inserted. If reclaim returns records at the front of availist, depict the availist and records after this processing.
25. Do the same as in Exercise 24, but assume that reclaim returns records at the rear of availist.
26. a. Why isn't it reasonable for avail to delete a record from anywhere on availist except the front or rear?
b. Why isn't it reasonable for reclaim to insert a record anywhere on availist except the front or rear?
27. Suppose a record is deleted from a list stored in records, but reclaim is not invoked to return it to availist. Is it ever possible to reuse the storage relinquished by that record?
28. Suppose records with different lengths are stored in records using the techniques of Chapter 2. The availist contains the available records in arbitrary order. Describe how avail and reclaim might be implemented.
29. This is the same as Exercise 28, except that the availist contains the available records ordered by length.
30. Write a function to create a list whose records are defined by
The input should consist of a sequence of information field values given in the order they should appear in the list. Linkptr points to the next record on the list, and prevptr points to the preceding record on the list.
31. Explain why pointer variables and the functions malloc and free remove the need for the programmer to manage storage for list records.
32. Both the sequential array and list representations for ordered records use arrays. Why are they different?
33. Suppose you are asked to store records that represent an inventory of books that are currently signed out from the library. Assume that frequent requests are made for output that includes the book title and the current borrower in alphabetical order by the borrower's name. Of course, books are frequently taken out and returned. Should a sequential array be used for the records or a list representation? Why?
34. Suppose records are stored using the sequential array implementation. Initially 1,000 records are stored. You are asked to delete every other record, starting with the first. After this deletion you must insert records before every third record, starting with the first record. Find an expression for the total number of shifts of records that must take place to accomplish these insertions and deletions.
35. Do Exercise 34, but instead of assuming a sequential implementation assume a list implementation.
36. Suppose you must access records in the order tenth, first, twelfth, thirtieth, and fiftieth. How much time will the five accesses take with a sequential representation, and how much time will they take with a list representation?
37. Describe a real-life situation in which the sequential array representation of ordered records is clearly more desirable, another in which the list representation is clearly favored, and a third situation that involves trade-offs between the two representations.
38. a. Write the initial and original routines for the array implementation of the perfect shuffle and for the list implementation of the perfect shuffle in Section 3.9.
b. Can original be reduced to checking only the nth card to see if it has returned to the initial configuration?
1. Write and execute a program to input a series of lists, each of which contains a number of sentences. After inputting all the lists, the program should invoke functions shorten and printlist to work on each list. Shorten is to print each sentence of the list it is to deal with whose length exceeds 25, and delete such sentences from the list; printlist is to print the resultant list. You should write shorten by defining the functions of traverse so as to turn traverse into shorten. Use dynamic memory for record storage. Don't forget to echo print all input and annotate all output. Make up some fun sentences. Store one character in each list record, and, for simplicity, assume all sentences end with a period.
2. Modify your program (and run the new version) when three characters (instead of one) are stored per record. Hint: within a list, assume the first character of each sentence is stored in a new record rather than in the record containing the period of the previous sentence, even when it has the room.
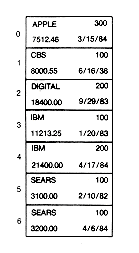
Table 3.1 A Stock Portfolio
Name # Shares Value Date Bought
Apple 300 $ 7,512.46 3/15/84
CBS 100 8,000.55 6/16/83
Digital 200 18,400.00 9/20/83
IBM 100 11,213.25 1/20/83
IBM 200 21,400.00 4/17/84
Sears 100 3,100.00 2/10/82
Sears 100 3,200.00 4/6/84
(a) Sequential Array
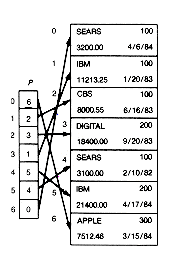
(b) Sequential Pointer Array
(c) Sequential Pointer Variable Array
Figure 3.1 Sequential Methods of Storing Records in Arrays
3.2: Keeping Track of List Pointers
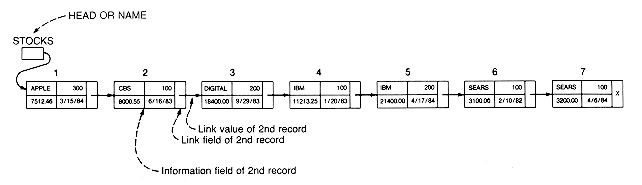
Figure 3.2 Graphic Representation of the List STOCKS
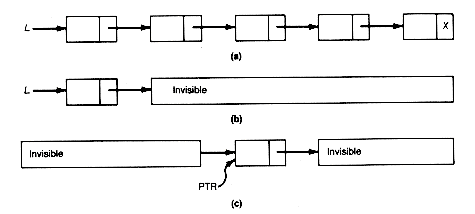
Figure 3.3 Simple Lists
3.2.1 Insertion and Deletion of Records in Lists
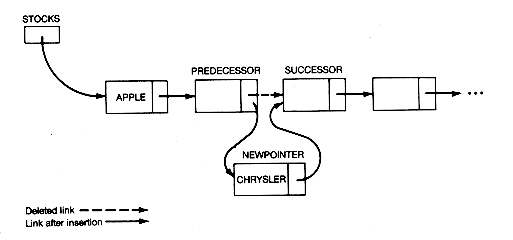
Figure 3.4 Insertion of a New Record in a Conceptual List
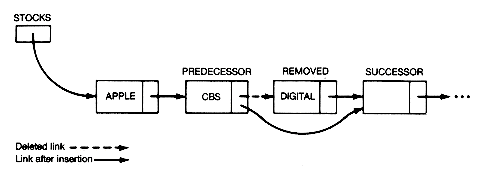
Figure 3.5 Deletion of a Record from a Conceptual List
3.3: Expanding and Contracting Lists
3.3.1 Insertion
setlink(newpointer,next(predecessor));
setlink(predecessor,newpointer);
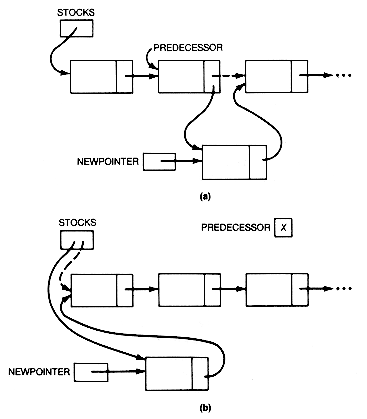
Figure 3.6 Insertion of a New Record (a) in the Interior of a List and (b) at the Front of a List
3.3.2 Special Cases
insert(phead,predecessor,newpointer)
/* Inserts, in list head, the record pointed to
by newpointer as the successor of the
record pointed to by predecessor.
*/
listpointer *phead,predecessor,newpointer;
{listpointer setnull(),next();
if(predecessor == setnull())
{setlink(newpointer,*phead);
*phead = newpointer;
}
else
{setlink(newpointer,next(predecessor));
setlink(predecessor,newpointer);
}
}
3.3.3 Header Records
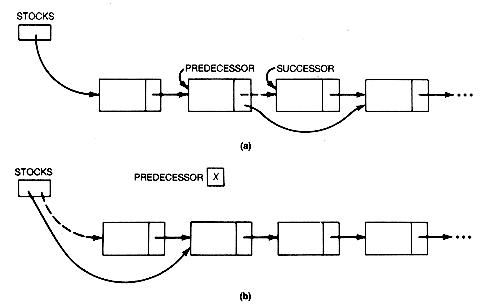
Figure 3.7 Deletion of a Record (a) from the Interior of a List and (b) from the Front of a List
3.3.4 Deletion
setlink(predecessor,next(next(predecessor)));
successor = next(predecessor);
setlink(predecessor,next(successor));
delete(phead,predecessor)
/* Deletes, in list head, the successor of
the record pointed to by predecessor.
*/
listpointer *phead,predecessor;
{listpointer successor,null,setnull(),next();
null = setnull();
if(*phead != null)
if(predecessor == null)
*phead = next(*phead);
else
{successor = next(predecessor);
if(successor != null)
setlink(predecessor,next(successor));
}
{3.4: Traversal of Lists
3.4.1 List Reversal Using a Loop

(a) The Original List
(b) The Reversed List

(c) The Procedure for Reversing the List
Figure 3.8 A List before, after, and during Reversal
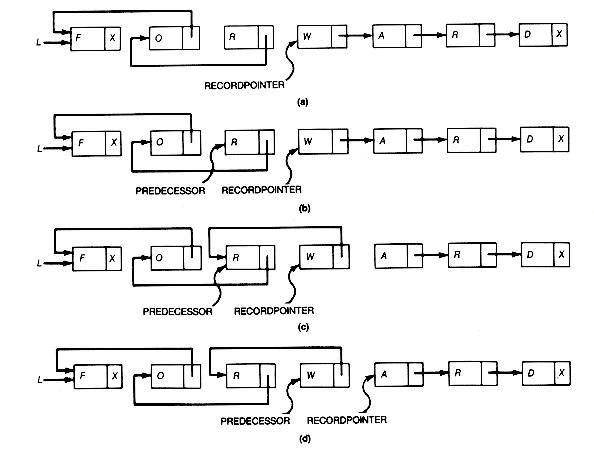
Figure 3.9 Achieving Proper Loop Implementation
3.4.2 A General List Traversal Using a Loop
traverse(listname)
listpointer listname;
{listpointer recordpointer,next();
moreparameters other;
int done;
initialize(listname,&other);
recordpointer = listname;
done = FALSE;
while(!done&&anotherrecord(listname,
recordpointer))
{process(listname,recordpointer,
&other,&done);
recordpointer =
next(recordpointer);
}
finalize(listname,other);
}
3.4.3 The Merits of Functional Modularization
3.5: Using the Traverse Function for Lists
initialize(listname,plength)
listpointer listname;
moreparameters *plength;
{*plength = 0;
}
process(listname,recordpointer,plength)
listpointer listname,recordpointer;
moreparameters *plength;
{(*plength)++;
}
finalize(listname,length)
listpointer lastname;
moreparameters length;
{if(length != 0)
printf ("\n The sentence has length %d \n",length);else
printf("\n There is no sentence \n");}
#define TRUE 1
#define FALSE 0
typedef int moreparameters;
traverse(listname)
/* Prints the length of the sentence
stored in the list, listname.
*/
listpointer listname;
{listpointer recordpointer,next();
moreparameters other;
int done;
initialize(listname,&other)
recordpointer = listname;
done = FALSE;
while(!done&&anotherrecord(listname,recordpointer))
{process(listname,recordpointer,&other);
recordpointer = next(recordpointer);
}
finalize(listname,other);
}
process(listname,recordpointer,plength)
listpointer listname,recordpointer;
moreparameters *plength;
{listpointer next();
int lastrecord;
char char1(),char2();
lastrecord = !anotherrecord(listname,next(recordpointer));
if(!lastrecord)
*plength = *plength + 3;
else if(char1(recordpointer) == '.')
(*plength)++;
else if(char2(recordpointer) == '.')
*plength = *plength + 2;
else
*plength = *plength + 3;
}

Figure 3.10 A Circular List
anotherrecord(listname,recordpointer)
listpointer listname,recordpointer;
{listpointer setnull();
return(recordpointer != setnull());
}
anotherrecord(listname,recordpointer)
listpointer listname,recordpointer;
{return(listname != recordpointer);
}
initialize(listname,psave,ppredecessor)
listpointer listname,*psave,*ppredecessor;
{listpointer setnull();
*psave = setnull();
*ppredecessor = setnull();
}
process(plistname,recordpointer,psave,
ppredecessor)
listpointer *plistname,recordpointer,*psave,
*ppredecessor;
{listpointer setnull();
if(*ppredecessor != setnull())
setlink(*ppredecessor,*psave);
*psave = *ppredecessor;
*ppredecessor = recordpointer:
}
finalize(plistname,save,predecessor)
listpointer *plistname,save,predecessor;
{listpointer setnull();
if(predecessor != setnull())
{setlink(predecessor,save);
*plistname = predecessor;
}
}
traverse(plistname)
/*Reverses the list listname.*/
listpointer *plistname;
{listpointer recordpointer,*psave,*ppredecessor,next();
initialize(listname,&psave,&ppredecessor);
recordpointer = *plistname;
while(anotherrecord(*plistname,recordpointer))
{process(*plistname,recordpointer,&psave,&ppredecessor);
recordpointer = next(recordpointer);
}
finalize(&plistname,*psave,*ppredecessor);
}
initialize(pnewpointer,ppredecessor)
listpointer *pnewpointer,*ppredecessor;
{listpointer avail(),setnull(),getnextrecord();
*pnewpointer = avail();
setinfo(*pnewpointer,getnextrecord());
*ppredecessor = setnull();
}
finalize(plistname,predecessor,newpointer)
listpointer *plistname,predecessor,newpointer;
{listpointer setnull();
if(*plistname == setnull())
insert(plistname,predecessor,newpointer);
}
process(plistname,recordpointer,newpointer,ppredecessor,
pdone)
listpointer *plistname,recordpointer,newpointer,
*ppredecessor;
int *pdone;
{listpointer setnull(),next();
if(precedes(newpointer,recordpointer))
{insert(plistname,*ppredecessor,newpointer);
*pdone = TRUE;
}
else if(next(recordpointer) == setnull())
{insert(plistname,recordpointer,newpointer);
*pdone = TRUE;
}
else
*ppredecessor = recordpointer;
}
orderedinsert(plistname)
/*Inputs and inserts a new record
in the list listname in alphabetical
order.
*/
listpointer *plistname;
{listpointer recordpointer,newpointer,predecessor,next();
int done;
initialize(&newpointer,&predecessor);
recordpointer = *plistname;
done = FALSE;
while(!done&&anotherrecord(*plistname,recordpointer))
{process(plistname,recordpointer,newpointer,
&predecessor,&done);
recordpointer = next(recordpointer);
}
finalize(plistname,predecessor,newpointer);
}
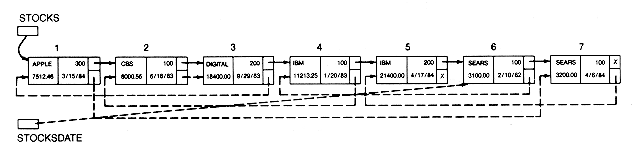
Figure 3.11 Two Orders for a List Using Two Heads and Two Link Fields
initialize(plistname)
listpointer *plistname;
{listpointer avail();
*plistname = avail();
}
process(plistname,recordpointer,pdone)
listpointer *plistname,recordpointer;
int *pdone;
{static listpointer predecessor;
listpointer setnull(),avail(),getnextrecord(),
pointer;
pointer = getnextrecord();
if(pointer != SENTINEL)
{setinfo(recordpointer,pointer);
setlink(recordpointer,avail());
predecessor = recordpointer;
}
else if (*plistname != recordpointer)
{setlink(predecessor,setnull());
*pdone = TRUE;
}
else
{*plistname = setnull();
*pdone = TRUE;
}
}
expand (plistname)
/*Inputs a series of records and
inserts them in alphabetical
order in the ordered list listname.
*/
listpointer *plistname;
{int done;
done = FALSE;
while(!done)
processrecord(plistname,&done);
}
processrecord(plistname,pdone)
listpointer *plistname;
int *pdone;
{listpointer pointer,getnextrecord();
pointer = getnextrecord();
if(pointer != SENTINEL)
insertinorder(plistname,pointer);
else
*pdone = TRUE;
}
insertinorder(plistname,pointer)
/*Inserts the record pointed to by pointer
in the ordered list listname.
*/
listpointer *plistname,pointer;
{listpointer recordpointer,predecessor,newpointer,
next();
int done;
initialize(&newpointer,&predecessor,pointer);
recordpointer = *plistname;
done = FALSE;
while(!done&&anotherrecord(*plistname,
recordpointer))
{process(plistname,recordpointer,newpointer,
&predecessor,&done);
recordpointer = next(recordpointer);
}
finalize(plistname,predecessor,pointer);
}
initialize(pnewpointer,ppredecessor,pointer)
listpointer *pnewpointer,*ppredecessor,pointer;
{listpointer setnull(),avail();
*pnewpointer = avail();
setinfo(*pnewpointer,pointer);
*ppredecessor = setnull();
}
process(plistname,recordpointer,newpointer,
ppredecessor,pdone)
listpointer *plistname,recordpointer,
newpointer,*ppredecessor;
int *pdone;
{listpointer setnull(),next();
if(precedes(newpointer,recordpointer))
{insert(plistname,*ppredecessor,newpointer);
*pdone = TRUE;
}
else if(next(recordpointer) == setnull())
{insert(plistname,recordpointer,newpointer);
*pdone = TRUE;
}
else
*ppredecessor = recordpointer;
}
finalize(plistname,predecessor,newpointer)
listpointer *plistname,predecessor,newpointer;
{listpointer setnull();
if(*plistname == setnull())
insert(plistname,predecessor,newpointer);
}
3.5.1 Why Traverse Was Useful
3.6: Implementing Lists
3.6.1 Lists Stored in Dynamic Memory
#define MAXSIZE 5
#define NULL 0
#define SENTINEL -1
typedef struct
{int month;
int day;
int year;
}date;
typedef struct
{char name[MAXSIZE];
int shares;
float value;
date datebought;
}infofield;
typedef struct listrecord
{infofield info;
struct listrecord *link;
}stockrecord,*listpointer;
Table 3.2 Sample Input
Explanation Actual Input
--------------------------------------------------------------------------
Record 1 Number of shares 100
Stock name abc
Price of a share 56.25
Month day year of purchase 1 23 1978
Record 2 Number of shares 50
Stock name wxyz
Price of a share 5.50
Month day year of purchase 11 4 1986
.
.
.
Terminal record Sentinel (where next number of shares would -1
otherwise appear)
#define MAXSIZE 5
#define NULL 0
#define SENTINEL -1
typedef struct
{int month;
int day;
int year;
}date;
typedef struct
{char name[MAXSIZE];
int share;
float value;
date datebought;
}infofield;
typedef struct listrecord
{infofield info;
struct listrecord *link;
}stockrecord,*listpointer;
listpointer next(pointer)
/* Returns a copy of the
link field in the record
pointed to by pointer
*/
listpointer pointer;
{return(pointer->link);
}
listpointer setnull()
/* Returns a null pointer */
{return(NULL);
}
setlink(pointer1,pointer2)
/* Sets the link field of the
record pointed to by pointer1
to the contents of pointer2
*/
listpointer pointer1,pointer2;
{pointer1->link = pointer2;
}
setinfo(pointer1,pointer2)
/* Sets the infofield of the record
pointed to by pointer1 to the
infofield of the record
pointed to by pointer2
*/
listpointer pointer1,pointer2;
{int i;
for(i=0;i<MAXSIZE;i++)
pointer1->info.name[i] = pointer2->
info.name[i];
pointer1->info.shares = pointer2->
info.shares;
pointer1->info.value = pointer2->info.value;
pointer1->info.datebought.month = pointer2->
info.datebought.month;
pointer1->info.datebought.day = pointer2->
info.datebought.day;
pointer1->info.datebought.year = pointer2->
info.datebought.year;
}
listpointer avail()
/* Returns a pointer to storage
allocated for a record of type
stockrecord
*/
{listpointer malloc();
return(malloc(sizeof(stockrecord)));
}
anotherrecord(recordpointer)
/* Returns true if there is
another record
*/
listpointer recordpointer;
{listpointer setnull();
return(recordpointer != setnull());
}
listpointer getnextrecord()
/* Inputs the data for the new
record and returns a pointer
to a record containing the data
in its infofield, or, if there
are no new records,returns
a null pointer
*/
{listpoiner setnull();
static stockrecord nextrecord;
printf("Enter number of shares\n");scanf("%d",&(nextrecord.info.shares));if(nextrecord.info.shares != SENTINEL)
{printf(" Enter the stock name - less than%d characters\n",MAXSIZE);
scanf("%s",nextrecord.info.name);printf(" Enter the price of one share ofthe stock\n");
scanf("%f",&(nextrecord.info.value));printf(" Enter the month day year of thestock purchase\n");
scanf("%d %d %d",&(nextrecord.info.datebought.month),
&(nextrecord.info.datebought.day),
&(nextrecord.info.datebought.year));
return(&nextrecord);
}
else
return(setnull());
}
printrecord(recordpointer)
/* Prints the contents of the infofield
of the record pointed to by recordpointer
*/
listpointer recordpointer;
{printf(" The stock is %s\n",recordpointer->info.name);
printf(" The number of shares is %d\n",recordpointer->info.shares);
printf(" The value of a share is %f\n",recordpointer->info.value);
printf(" The date of purchase is %d %d %d\n\n",recordpointer->info.datebought.month,
recordpointer->info.datebought.day,
recordpointer->info.datebought.year);
}
#include <stdio.h>
#define TRUE 1
#define FALSE 0
main()
/* Inputs a series of stockrecords,
creates a list of the records, and
prints the contents of each list
record's infofield
*/
{listpointer stocks,recordpointer,next();
int done;
initialize(&stocks);
recordpointer = stocks;
done = FALSE;
while(!done&&anotherrecord(recordpointer))
{addrecord(&stocks,recordpointer,&done);
recordpointer = next(recordpointer);
}
recordpointer=stocks;
while(anotherrecord(recordpointer))
{printrecord(recordpointer);
recordpointer = next(recordpointer);
}
}
initialize(plistname)
/* Allocates storage for the first record
and sets listname to point to it
*/
listpointer *plistname;
{listpointer avail();
*plistname = avail();
}
addrecord(plistname,recordpointer,pdone)
/* Fills in the current record's data, and allocates
storage for the next record and adds it to the
list. If there is no data for the current record
it sets the link field of the last list record
to null, or the list head to null, and done to
true.
*/
listpointer *plistname,recordpointer;
int *pdone;
{static listpointer predecessor;
listpointer setnull(),avail(),getnextrecord(),
pointer;
pointer =getnextrecord();
if(pointer != setnull())
{setinfo(recordpointer,pointer);
setlink(recordpointer,avail());
predecessor = recordpointer;
}
else if(*plistname != recordpointer)
{setlink(predecessor,setnull());
*pdone = TRUE;
}
else
{*plistname = setnull();
*pdone = TRUE;
}
}
3.6.2 Lists Stored in an Array of Records
#define MAXSIZE 5
#define MAX 100
#define NULL -1
typedef struct
{int month;
int day;
int year;
}date;
typedef struct
{char name[MAXSIZE];
int shares;
float value;
date datebought;
}infofield;
typedef struct listrecord
{infofield info;
int link;
}stockrecord;
stockrecord records[MAX];
typedef in listpointer;
next(pointer)
/* Returns a copy of the
link field in the record
pointed to by pointer
*/
listpointer pointer;
{return(records[pointer].link);
}
setnull()
/* Returns a null pointer */
{return(-1);
}
setlink(pointerl,pointer2)
/* Sets the link field of the
record pointed to by pointer1
to the contents of pointer2
*/
listpointer pointer1,pointer2;
{records[pointer1].link = pointer2;
}
3.6.3 Lists Stored in Languages without Records
3.7: Keeping Track of Available Records
3.7.1 Why Dynamic Memory?
 n yet stores only those
n yet stores only those 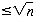 n in the list, but again, how many of these are there?
n in the list, but again, how many of these are there?3.7.2 Using Dynamic Memory
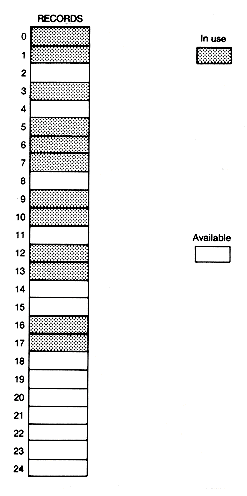
Figure 3.12 Typical Configuration of Used and Unused List Records in the RECORDS Array
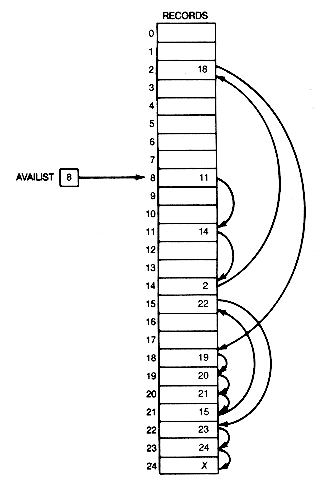
Figure 3.13 The List of Available Records Corresponding to Figure 3.12
3.8: Sequential Arrays versus Lists for Record Storage
3.9: Case Study: Merging and the Perfect Shuffle
3.9.1 The Perfect Shuffle
Figure 3.14 The Result of Two Perfect Shuffles
initial(configuration,n);
numbershuffles = 1;
perfectshuffle (configuration,n);
while(!original(configuration,n))
{perfectshuffle(configuration,n);
numbershuffles++;
}
3.9.2 Array Implementation of the Perfect Shuffle
for(i=1;i<=(2*n);i++)
configuration[i] = i;
temporiginal = TRUE;
i = 1;
while((i<n+1)&&temporiginal)
if(configuration[i] != i)
temporiginal = FALSE;
else
i++;
original = temporiginal;
result[newi] = configuration[i];
result[newi+1] = configuration[i+n];
i++;
newi = newi + 2;
i = 1;
while(i < n)
{result[newi] = configuration[i];
result[newi+1] = configuration[i+n];
i++;
newi = newi + 2;
}
for(i=1;i<=(2*n);i++)
configuration[i] = result[i];
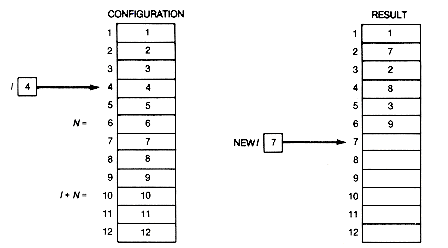
(a) Situation Just before the Fourth Entry Is Processed
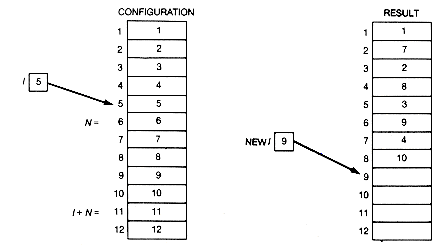
(b) Situation Just after the Fourth Entry Is Processed
Figure 3.15 Two Arrays Used for a Perfect Shuffle of Six Elements
3.9.3 List Implementation of the Perfect Shuffle

Figure 3.16 The List Implementation for CONFIGURATION
configurationpointer l1,newn;
l1 = configuration;
newn = l1;
while(l1 != n)
{move(l1,n);
l1 =l1->link;
newn = newn->link;
}
n = newn;
move(pl1,n)
configurationpointer *pl1,n;
{configurationpointer hold1,hold2;
hold1 = l1->link;
hold2 = n->link;
11->link = hold2;
n->link = hold2->link;
hold2->link = hold1;
l1 = l1->link;
}
#define TRUE 1
#define FALSE 0
typedef int arraytype[53];
main() /* Perfect shuffle using arrays */
/* Drives the perfectshuffle */
{arraytype configuration;
int numbershuffles,n;
printf("\n Enter an integer between 1 and 26 \n");scanf("%d",&n);initial(configuration,n);
numbershuffles = 1;
perfectshuffle(configuration,n);
while(!original(configuration,n))
{perfectshuffle(configuration,n);
numbershuffles++;
}
printf("\n Number of shuffles = %d \n",numbershuffles);}
initial(configuration,n)
/* Creates the initial configuration */
arraytype configuration;
int n;
{int i;
for(i=1;i<=(2*n);i++)
configuration[i] = i;
}
perfectshuffle(configuration,n)
/* Carries out a perfect shuffle */
arraytype configuration;
int n;
{arraytype result;
int i,newi;
i = 1;
newi = 1;
while(i < (n+1))
{result[newi] = configuration[i];
result[newi+1] = configuration[i+n];
i++;
newi = newi + 2;
}
for(i=1;i<=(2*n);i++)
configuration[i] = result[i];
}
original(configuration,n)
/* Returns true if the original
configuration has recurred
*/
arraytype configuration;
int n;
}
int i,temporiginal;
i = 1;
temporiginal = TRUE;
while((i < (n+1))&&temporiginal)
if(configuration[i] != i)
temporiginal = FALSE;
else
i++;
return(temporiginal);
}
#define TRUE 1
#define FALSE 0
#define NULL 0
typedef struct configrec
{int info;
struct configrec *link;
}configrecord,*configptr;
int num;
main() /* perfect shuffle using lists */
/* Drives the perfectshuffle */
{configptr configuration,n;
int numbershuffles;
printf("\n Enter an integer between 1 and 26\n");scanf("%d",&num);initial(&configuration,&n);
numbershuffles = 1;
perfectshuffle(configuration,&n);
while(!original(configuration,n))
{perfectshuffle(configuration,&n);
numbershuffles++;
}
printf("\n The number of shuffles = %d\n",numbershuffles);}
initial(pconfiguration,pn)
/* Creates the initial configuration */
configptr *pconfiguration,*pn;
{configptr p,q;
int i;
*pconfiguration = malloc(sizeof(configrecord));
p = *pconfiguration;
i = 1;
while(i != (2*num+1))
{p->info = i;
if(i == num)
*pn = p;
i++;
p->link = malloc(sizeof(configrecord));
q = p;
p = p->link;
}
q->link = NULL;
}
perfectshuffle(configuration,pn)
/* Carries out a perfect shuffle */
configptr configuration,*pn;x
{configptr l1,newn;
l1 = configuration;
newn = l1;
while(l1 != *pn)
{move(&l1,*pn);
l1 = l1->link;
newn = newn->link;
}
*pn = newn;
}
original(configuration,n)
/* Returns true if the original
configuration has recurred
*/
configptr configuration,n;
{int temporiginal,i;
configptr p;
temporiginal = TRUE;
i = 1;
p = configuration;
while((p != n->link)&&temporiginal)
if(p->info != i)
temporiginal = FALSE;
else
{i++;
p = p->link;
}
return(temporiginal);
}
move(pl1,n)
/* Processes a record of configuration */
configptr *pl1,n;
{configptr hold1,hold2;
hold1 = (*pl1)->link;
hold2 = n->link;
(*pl1)->link = hold2;
n->link = hold2->link;
hold2->link = hold1;
(*pl1) = (*pl1)->link;
}
3.9.4 Merging Sequences of Entries
Table 3.3 The Result of Merging Two Sequences of Ordered Entries of Length 4
Initial After First After First After Second
Configuration Perfect Shuffle Compare Exchange Perfect Shulle
-----------------------------------------------------------------
100 100 100 100
80 10 10 85
65 80 80 10
30 50 50 65
10 65 85 80
50 85 65 90
85 30 90 50
90 90 30 30
After Second After Third After Third
Compare Exchange Perfect Shuffle Compare Exchange
---------------------------------------------------
100 100 100
85 90 90
65 85 85
10 80 80
90 65 65
80 50 50
50 10 30
30 30 10
Exercises
DATA P S
---------------
0 1 -1 5
1 12 4 6
2 18 6 8
3 4 5 9
4 7 9 1
5 3 0 3
6 12 1 2
7 100 8 -1
8 20 2 7
9 5 3 4
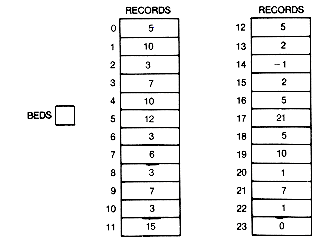
typedef struct node
{whatevertype info;
struct node *linkptr;
struct node *prevptr;
}listnode;
Suggested Assignments