


A tree imposes a hierarchical structure on a collection of items. Familiar examples of trees are genealogies and organization charts. Trees are used to help analyze electrical circuits and to represent the structure of mathematical formulas. Trees also arise naturally in many different areas of computer science. For example, trees are used to organize information in database systems and to represent the syntactic structure of source programs in compilers. Chapter 5 describes applications of trees in the representation of data. Throughout this book, we shall use many different variants of trees. In this chapter we introduce the basic definitions and present some of the more common tree operations. We then describe some of the more frequently used data structures for trees that can be used to support these operations efficiently.
A tree is a collection of elements called nodes, one of which is distinguished as a root, along with a relation ("parenthood") that places a hierarchical structure on the nodes. A node, like an element of a list, can be of whatever type we wish. We often depict a node as a letter, a string, or a number with a circle around it. Formally, a tree can be defined recursively in the following manner.
Sometimes, it is convenient to include among trees the null tree, a "tree" with no nodes, which we shall represent by L.
Example 3.1. Consider the table of contents of a book, as suggested by Fig. 3.1(a). This table of contents is a tree. We can redraw it in the manner shown in Fig. 3.1(b). The parent-child relationship is depicted by a line. Trees are normally drawn top-down as in Fig. 3.1(b), with the parent above the child.
The root, the node called "Book," has three subtrees with roots corresponding to the chapters C1, C2, and C3. This relationship is represented by the lines downward from Book to C1, C2, and C3. Book is the parent of C1, C2, and C3, and these three nodes are the children of Book.
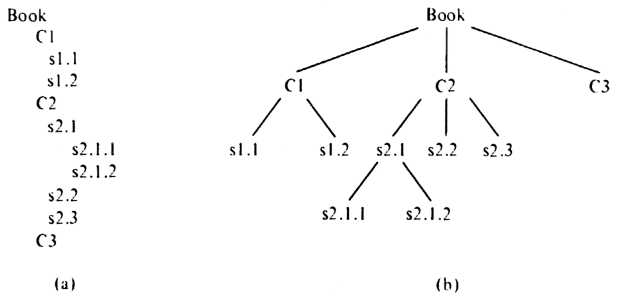
Fig. 3.1. A table of contents and its tree representation.
The third subtree, with root C3, is a tree of a single node, while the other two subtrees have a nontrivial structure. For example, the subtree with root C2 has three subtrees, corresponding to the sections s2.1, s2.2, and s2.3; the last two are one-node trees, while the first has two subtrees corresponding to the subsections s2.1.1 and s2.1.2.
Example 3.1 is typical of one kind of data that is best represented as a tree. In this example, the parenthood relationship stands for containment; a parent node is comprised of its children, as Book is comprised of C1, C2, and C3. Throughout this book we shall encounter a variety of other relationships that can be represented by parenthood in trees.
If n1, n2, . . . , nk is a sequence of nodes in a tree such that ni is the parent of ni+1 for 1 ?/FONT> i < k, then this sequence is called a path from node n1 to node nk. The length of a path is one less than the number of nodes in the path. Thus there is a path of length zero from every node to itself. For example, in Fig. 3.1 there is a path of length two, namely (C2, s2.1, s2.1.2) from C2 to s2.1.2.
If there is a path from node a to node b, then a is an ancestor of b, and b is a descendant of a. For example, in Fig. 3.1, the ancestors of s2.1, are itself, C2, and Book, while its descendants are itself, s2.1.1, and s2.1.2. Notice that any node is both an ancestor and a descendant of itself.
An ancestor or descendant of a node, other than the node itself, is called a proper ancestor or proper descendant, respectively. In a tree, the root is the only node with no proper ancestors. A node with no proper descendants is called a leaf. A subtree of a tree is a node, together with all its descendants.
The height of a node in a tree is the length of a longest path from the node to a leaf. In Fig. 3.1 node C1 has height 1, node C2 height 2, and node C3 height 0. The height of a tree is the height of the root. The depth of a node is the length of the unique path from the root to that node.
The children of a node are usually ordered from left-to-right. Thus the two trees of Fig. 3.2 are different because the two children of node a appear in a different order in the two trees. If we wish explicitly to ignore the order of children, we shall refer to a tree as an unordered tree.
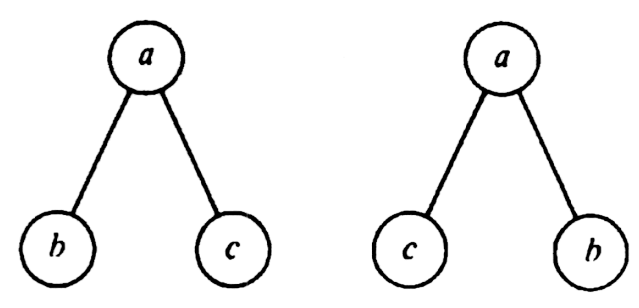
Fig. 3.2. Two distinct (ordered) trees.
The "left-to-right" ordering of siblings (children of the same node) can be extended to compare any two nodes that are not related by the ancestor-descendant relationship. The relevant rule is that if a and b are siblings, and a is to the left of b, then all the descendants of a are to the left of all the descendants of b.
Example 3.2. Consider the tree in Fig. 3.3. Node 8 is to the right of node 2, to the left of nodes 9, 6, 10, 4, and 7, and neither left nor right of its ancestors 1, 3, and 5.
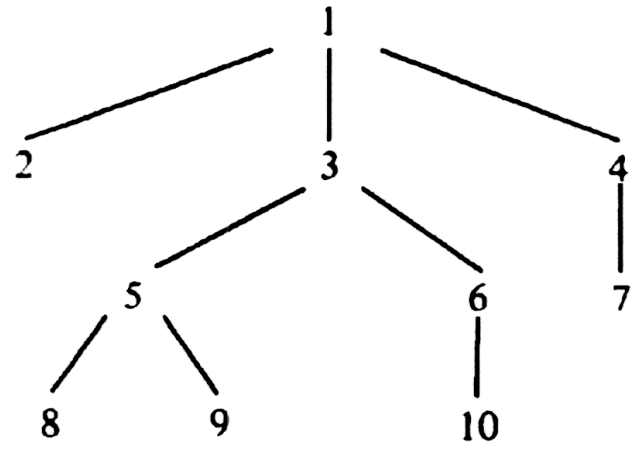
Fig. 3.3. A tree.
A simple rule, given a node n, for finding those nodes to its left and those to its right, is to draw the path from the root to n. All nodes branching off to the left of this path, and all descendants of such nodes, are to the left of n. All nodes and descendants of nodes branching off to the right are to the right of n.
There are several useful ways in which we can systematically order all nodes of a tree. The three most important orderings are called preorder, inorder and postorder; these orderings are defined recursively as follows.
Otherwise, let T be a tree with root n and subtrees T1, T2, . . . , Tk, as suggested in Fig. 3.4.
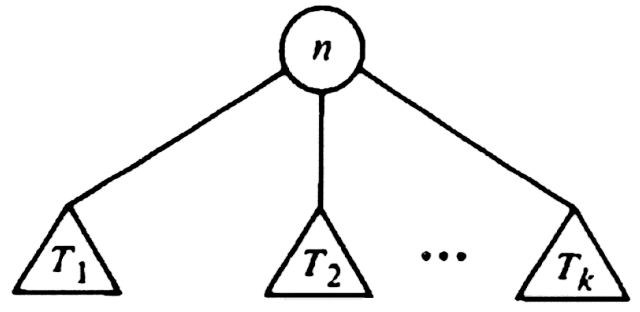
Fig. 3.4. Tree T.
Figure 3.5(a) shows a sketch of a procedure to list the nodes of a tree in preorder. To make it a postorder procedure, we simply reverse the order of steps (1) and (2). Figure 3.5(b) is a sketch of an inorder procedure. In each case, we produce the desired ordering of the tree by calling the appropriate procedure on the root of the tree.
Example 3.3. Let us list the tree of Fig. 3.3 in preorder. We first list 1 and then call PREORDER on the first subtree of 1, the subtree with root 2. This subtree is a single node, so we simply list it. Then we proceed to the second subtree of 1, the tree rooted at 3. We list 3, and then call PREORDER on the first subtree of 3. That call results in listing 5, 8, and 9, in that order.
procedure PREORDER ( n: node );
begin
(1) list n;
(2) for each child c of n, if any, in order from the left do
PREORDER(c)
end; { PREORDER }
(a) PREORDER procedure.
procedure INORDER ( n: node );
begin
if n is a leaf then
list n;
else begin
INORDER(leftmost child of n);
list n;
for each child c of n, except for the leftmost,
in order from the left do
INORDER(c)
end
end; { INORDER }
(b) INORDER procedure.
Fig. 3.5. Recursive ordering procedures.
Continuing in this manner, we obtain the complete preorder traversal of Fig. 3.3: 1, 2, 3, 5, 8, 9, 6, 10, 4, 7.
Similarly, by simulating Fig. 3.5(a) with the steps reversed, we can discover that the postorder of Fig. 3.3 is 2, 8, 9, 5, 10, 6, 3, 7, 4, 1. By simulating Fig. 3.5(b), we find that the inorder listing of Fig. 3.3 is 2, 1, 8, 5, 9, 3, 10, 6, 7, 4.
A useful trick for producing the three node orderings is the following. Imagine we walk around the outside of the tree, starting at the root, moving counterclockwise, and staying as close to the tree as possible; the path we have in mind for Fig. 3.3 is shown in Fig. 3.6.
For preorder, we list a node the first time we pass it. For postorder, we list a node the last time we pass it, as we move up to its parent. For inorder, we list a leaf the first time we pass it, but list an interior node the second time we pass it. For example, node 1 in Fig. 3.6 is passed the first time at the beginning, and the second time while passing through the "bay" between nodes 2 and 3. Note that the order of the leaves in the three orderings is
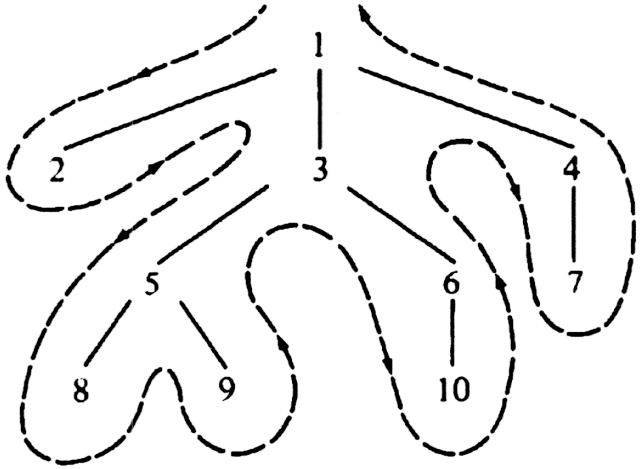
Fig. 3.6. Traversal of a tree.
always the same left-to-right ordering of the leaves. It is only the ordering of the interior nodes and their relationship to the leaves that vary among the three.
Often it is useful to associate a label, or value, with each node of a tree, in the same spirit with which we associated a value with a list element in the previous chapter. That is, the label of a node is not the name of the node, but a value that is "stored" at the node. In some applications we shall even change the label of a node, while the name of a node remains the same. A useful analogy is tree:list = label:element = node:position.
Example 3.4. Figure 3.7 shows a labeled tree representing the arithmetic expression (a+b) * (a+c), where n1, . . . , n7 are the names of the nodes, and the labels, by convention, are shown next to the nodes. The rules whereby a labeled tree represents an expression are as follows:
For example, node n2 has operator +, and its left and right children represent the expressions a and b, respectively. Therefore, n2 represents (a)+(b), or just a+b. Node n1 represents (a+b)*(a+c), since * is the label at n1, and a+b and a+c are the expressions represented by n2 and n3, respectively.
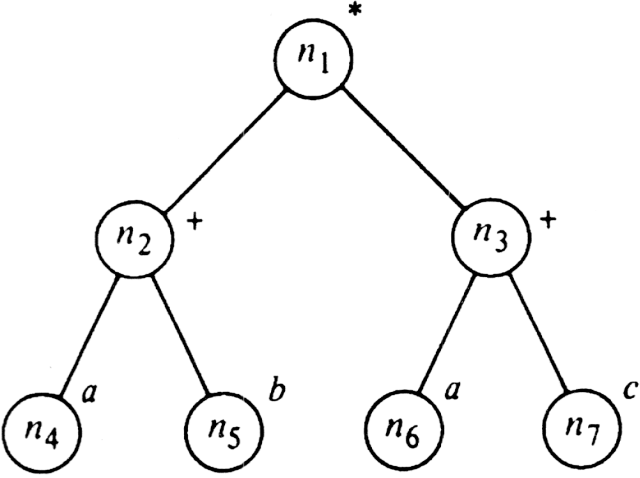
Fig. 3.7. Expression tree with labels.
Often, when we produce the preorder, inorder, or postorder listing of a tree, we prefer to list not the node names, but rather the labels. In the case of an expression tree, the preorder listing of the labels gives us what is known as the prefix form of an expression, where the operator precedes its left operand and its right operand. To be precise, the prefix expression for a single operand a is a itself. The prefix expression for (E1) q (E2), with q a binary operator, is qP1P2, where P1 and P2 are the prefix expressions for E1 and E2. Note that no parentheses are necessary in the prefix expression, since we can scan the prefix expression qP1P2 and uniquely identify P1 as the shortest (and only) prefix of P1P2 that is a legal prefix expression.
For example, the preorder listing of the labels of Fig. 3.7 is *+ab+ac. The prefix expression for n2, which is +ab, is the shortest legal prefix of +ab+ac.
Similarly, a postorder listing of the labels of an expression tree gives us what is known as the postfix (or Polish) representation of an expression. The expression (E1) q (E2) is represented by the postfix expression P1P2q, where P1 and P2 are the postfix representations of E1 and E2, respectively. Again, no parentheses are necessary in the postfix representation, as we can deduce what P2 is by looking for the shortest suffix of P1P2 that is a legal postfix expression. For example, the postfix expression for Fig. 3.7 is ab+ac+*. If we write this expression as P1P2*, then P2 is ac+, the shortest suffix of ab+ac+ that is a legal postfix expression.
The inorder traversal of an expression tree gives the infix expression itself, but with no parentheses. For example, the inorder listing of the labels of Fig. 3.7 is a+b * a+c. The reader is invited to provide an algorithm for traversing an expression tree and producing an infix expression with all needed pairs of parentheses.
The preorder and postorder traversals of a tree are useful in obtaining ancestral information. Suppose postorder(n) is the position of node n in a post-order listing of the nodes of a tree. Suppose desc(n) is the number of proper descendants of node n. For example, in the tree of Fig. 3.7 the postorder numbers of nodes n2, n4, and n5 are 3, 1, and 2, respectively.
The postorder numbers assigned to the nodes have the useful property that the nodes in the subtree with root n are numbered consecutively from postorder(n) - desc(n) to postorder(n). To test if a vertex x is a descendant of vertex y, all we need do is determine whether
postorder(y) - desc(y) ?/FONT> postorder(x) ?/FONT> postorder(y).
A similar property holds for preorder.
In Chapter 2, lists, stacks, queues, and mappings were treated as abstract data types (ADT's). In this chapter trees will be treated both as ADT's and as data structures. One of our most important uses of trees occurs in the design of implementations for the various ADT's we study. For example, in Section 5.1, we shall see how a "binary search tree" can be used to implement abstract data types based on the mathematical model of a set, together with operations such as INSERT, DELETE, and MEMBER (to test whether an element is in a set). The next two chapters present a number of other tree implementations of various ADT's.
In this section, we shall present several useful operations on trees and show how tree algorithms can be designed in terms of these operations. As with lists, there are a great variety of operations that can be performed on trees. Here, we shall consider the following operations:
Example 3.5. Let us write both recursive and nonrecursive procedures to take a tree and list the labels of its nodes in preorder. We assume that there are data types node and TREE already defined for us, and that the data type TREE is for trees with labels of the type labeltype. Figure 3.8 shows a recursive procedure that, given node n, lists the labels of the subtree rooted at n in preorder. We call PREORDER(ROOT(T)) to get a preorder listing of tree T.
procedure PREORDER ( n: node );
{ list the labels of the descendants of n in preorder }
var
c: node;
begin
print(LABEL(n, T));
c := LEFTMOST_CHILD(n, T);
while c <> L do
begin
PREORDER(c);
c := RIGHT_SIBLING(c, T)
end
end; { PREORDER }
Fig. 3.8. A recursive preorder listing procedure.
We shall also develop a nonrecursive procedure to print a tree in preorder. To find our way around the tree, we shall use a stack S, whose type STACK is really "stack of nodes." The basic idea underlying our algorithm is that when we are at a node n, the stack will hold the path from the root to n, with the root at the bottom of the stack and node n at the top.†
One way to perform a nonrecursive preorder traversal of a tree is given by the program NPREORDER shown in Fig. 3.9. This program has two modes of operation. In the first mode it descends down the leftmost unexplored path in the tree, printing and stacking the nodes along the path, until it reaches a leaf.
The program then enters the second mode of operation in which it retreats back up the stacked path, popping the nodes of the path off the stack, until it encounters a node on the path with a right sibling. The program then reverts back to the first mode of operation, starting the descent from that unexplored right sibling.
The program begins in mode one at the root and terminates when the stack becomes empty. The complete program is shown in Fig. 3.9.
In this section we shall present several basic implementations for trees and discuss their capabilities for supporting the various tree operations introduced in Section 3.2.
Let T be a tree in which the nodes are named 1, 2, . . . , n. Perhaps the simplest representation of T that supports the PARENT operation is a linear array A in which entry A[i] is a pointer or a cursor to the parent of node i. The root of T can be distinguished by giving it a null pointer or a pointer to itself as parent. In Pascal, pointers to array elements are not feasible, so we shall have to use a cursor scheme where A[i] = j if node j is the parent of node i, and A[i] = 0 if node i is the root.
This representation uses the property of trees that each node has a unique parent. With this representation the parent of a node can be found in constant time. A path going up the tree, that is, from node to parent to parent, and so on, can be traversed in time proportional to the number of nodes on the path. We can also support the LABEL operator by adding another array L, such that L[i] is the label of node i, or by making the elements of array A be records consisting of an integer (cursor) and a label.
Example 3.6. The tree of Fig. 3.10(a) has the parent representation given by the array A shown in Fig. 3.10(b).
The parent pointer representation does not facilitate operations that require child-of information. Given a node n, it is expensive to determine the children of n, or the height of n. In addition, the parent pointer representation does not specify the order of the children of a node. Thus, operations like LEFTMOST_CHILD and RIGHT_SIBLING are not well defined. We could impose an artificial order, for example, by numbering the children of each node after numbering the parent, and numbering the children in
procedure NPREORDER ( T: TREE );
{ nonrecursive preorder traversal of tree T }
var
m: node; { a temporary }
S: STACK; { stack of nodes holding path from the root
to the parent TOP(S) of the "current" node m }
begin
{ initialize }
MAKENULL(S);
m := ROOT(T);
while true do
if m < > L then begin
print(LABEL(m, T));
PUSH(m, S);
{ explore leftmost child of m }
m := LEFTMOST_CHILD(m, T)
end
else begin
{ exploration of path on stack
is now complete }
if EMPTY(S) then
return;
{ explore right sibling of node
on top of stack }
m := RIGHT_SIBLING(TOP(S), T);
POP(S)
end
end; { NPREORDER }
Fig. 3.9. A nonrecursive preorder procedure.
increasing order from left to right. On that assumption, we have written the function RIGHT_SIBLING in Fig. 3.11, for types node and TREE that are defined as follows:
type node = integer; TREE = array [1..maxnodes] of node;
For this implementation we assume the null node L is represented by 0.
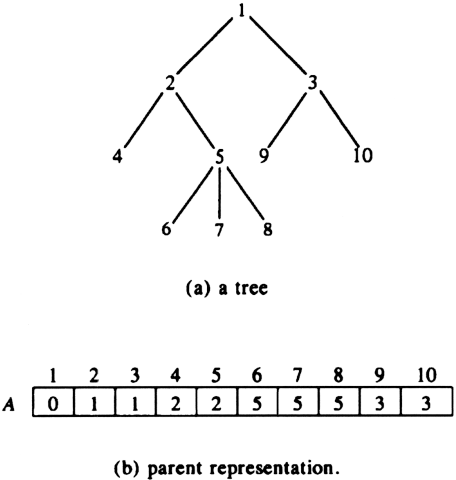
Fig. 3.10. A tree and its parent pointer representation.
function RIGHT_SIBLING ( n: node; T: TREE ): node;
{ return the right sibling of node n in tree T }
var
i, parent: node;
begin
parent: = T[n];
for i := n + 1 to maxnodes do
{ search for node after n with same parent }
if T[i] = parent then
return (i);
return (0) { null node will be returned
if no right sibling is ever found }
end; { RIGHT_SIBLING }
Fig. 3.11. Right sibling operation using array representation.
An important and useful way of representing trees is to form for each node a list of its children. The lists can be represented by any of the methods suggested in Chapter 2, but because the number of children each node may have can be variable, the linked-list representations are often more appropriate.
Figure 3.12 suggests how the tree of Fig. 3.10(a) might be represented. There is an array of header cells, indexed by nodes, which we assume to be numbered 1, 2, . . . , 10. Each header points to a linked list of "elements," which are nodes. The elements on the list headed by header[i] are the children of node i; for example, 9 and 10 are the children of 3.
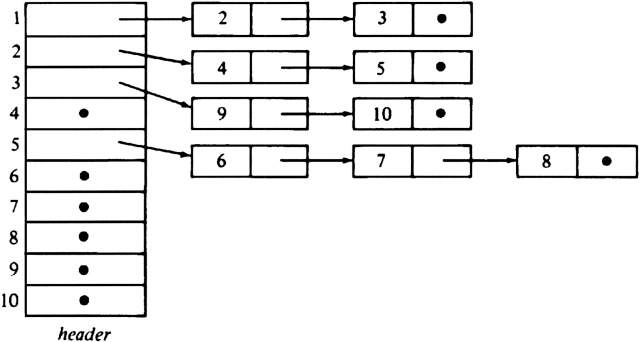
Fig. 3.12. A linked-list representation of a tree.
Let us first develop the data structures we need in terms of an abstract data type LIST (of nodes), and then give a particular implementation of lists and see how the abstractions fit together. Later, we shall see some of the simplifications we can make. We begin with the following type declarations:
type
node = integer;
LIST = { appropriate definition for list of nodes };
position = { appropriate definition for positions in lists };
TREE = record
header: array [1..maxnodes] of LIST;
labels: array [1..maxnodes] of labeltype;
root: node
end;
We assume that the root of each tree is stored explicitly in the root field. Also, 0 is used to represent the null node.
Figure 3.13 shows the code for the LEFTMOST_CHILD operation. The reader should write the code for the other operations as exercises.
function LEFTMOST_CHILD ( n: node; T: TREE ): node;
{ returns the leftmost child of node n of tree T }
var
L: LIST; { shorthand for the list of n's children }
begin
L := T.header[n];
if EMPTY(L) then { n is a leaf }
return (0)
else
return (RETRIEVE(FIRST(L), L))
end; { LEFTMOST_CHILD }
Fig. 3.13. Function to find leftmost child.
Now let us choose a particular implementation of lists, in which both LIST and position are integers, used as cursors into an array cellspace of records:
var cellspace : array [1..maxnodes] of record node: integer; next: integer end;
To simplify, we shall not insist that lists of children have header cells. Rather, we shall let T.header [n] point directly to the first cell of the list, as is suggested by Fig. 3.12. Figure 3.14(a) shows the function LEFTMOST_CHILD of Fig. 3.13 rewritten for this specific implementation. Figure 3.14(b) shows the operator PARENT, which is more difficult to write using this representation of lists, since a search of all lists is required to determine on which list a given node appears.
The data structure described above has, among other shortcomings, the inability to create large trees from smaller ones, using the CREATEi operators. The reason is that, while all trees share cellspace for linked lists of children, each has its own array of headers for its nodes. For example, to implement CREATE2(v, T1, T2) we would have to copy T1 and T2 into a third tree and add a new node with label v and two children -- the roots of T1 and T2.
If we wish to build trees from smaller ones, it is best that the representation of nodes from all trees share one area. The logical extension of Fig. 3.12 is to replace the header array by an array nodespace consisting of records with
function LEFTMOST_CHILD ( n: node; T: TREE ): node;
{ returns the leftmost child of node n on tree T }
var
L: integer; { a cursor to the beginning of the list of n's children }
begin
L := T.header[n];
if L = 0 then { n is a leaf }
return (0)
else
return (cellspace[L].node)
end; { LEFTMOST_CHILD }
(a) The function LEFTMOST_CHILD.
function PARENT ( n: node; T: TREE ): node;
{ returns the parent of node n in tree T }
var
p: node; { runs through possible parents of n }
i: position; { runs down list of p's children }
begin
for p := 1 to maxnodes do begin
i := T.header[p];
while i <> 0 do { see if n is among children of
p }
if cellspace[i].node = n then
return (p)
else
i := cellspace[i].next
end;
return (0) { return null node if parent not found }
end; { PARENT }
(b) The function PARENT.
Fig. 3.14. Two functions using linked-list representation of trees.
two fields label and header. This array will hold headers for all nodes of all trees. Thus, we declare
var
nodespace : array [1..maxnodes] of record
label: labeltype;
header: integer; { cursor to cellspace }
end;
Then, since nodes are no longer named 1, 2, . . . , n, but are represented by arbitrary indices in nodespace, it is no longer feasible for the field node of cellspace to represent the "number" of a node; rather, node is now a cursor into nodespace, indicating the position of that node. The type TREE is simply a cursor into nodespace, indicating the position of the root.
Example 3.7. Figure 3.15(a) shows a tree, and Fig. 3.15(b) shows the data structure where we have placed the nodes labeled A, B, C, and D arbitrarily in positions 10, 5, 11, and 2 of nodespace. We have also made arbitrary choices for the cells of cellspace used for lists of children.
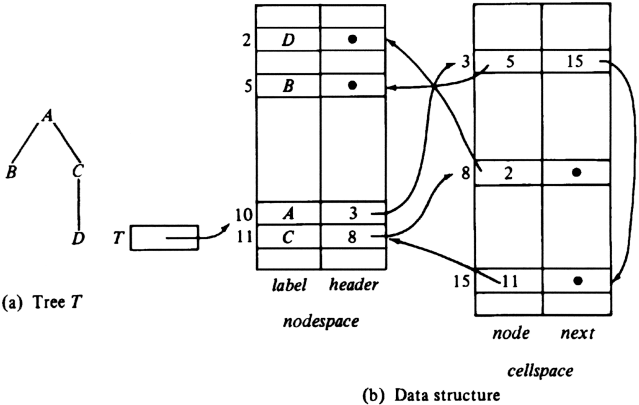
Fig. 3.15. Another linked-list structure for trees.
The structure of Fig. 3.15(b) is adequate to merge trees by the CREATEi operations. This data structure can be significantly simplified, however, First, observe that the chains of next pointers in cellspace are really right-sibling pointers.
Using these pointers, we can obtain leftmost children as follows. Suppose cellspace[i].node = n. (Recall that the "name" of a node, as opposed to its label, is in effect its index in nodespace, which is what cellspace[i].node gives us.) Then nodespace[n].header indicates the cell for the leftmost child of n in cellspace, in the sense that the node field of that cell is the name of that node in nodespace.
We can simplify matters if we identify a node not with its index in nodespace, but with the index of the cell in cellspace that represents it as a child. Then, the next pointers of cellspace truly point to right siblings, and the information contained in the nodespace array can be held by introducing a field leftmost_child in cellspace. The datatype TREE becomes an integer used as a cursor to cellspace indicating the root of the tree. We declare cellspace to have the following structure.
var cellspace : array [1..maxnodes] of record label: labeltype; leftmost_child: integer; right_sibling: integer; end;
Example 3.8. The tree of Fig. 3.15(a) is represented in our new data structure in Fig. 3.16. The same arbitrary indices as in Fig. 3.15(b) have been used for the nodes.
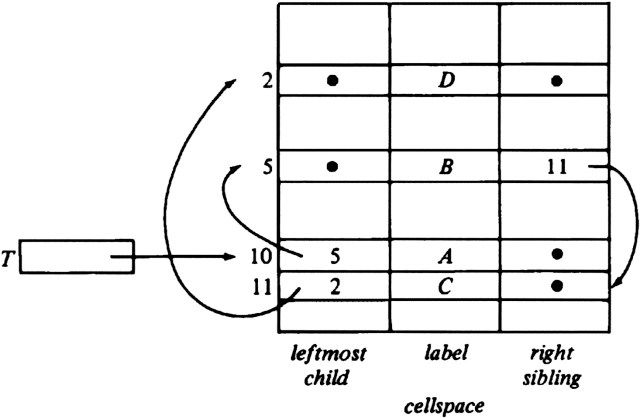
Fig. 3.16. Leftmost-child, right-sibling representation of a tree.
All operations but PARENT are straightforward to implement in the leftmost-child, right-sibling representation. PARENT requires searching the entire cellspace. If we need to perform the PARENT operation efficiently, we can add a fourth field to cellspace to indicate the parent of a node directly.
As an example of a tree operation written to use the leftmost- child, right-sibling structure as in Fig. 3.16, we give the function CREATE2 in Fig. 3.17. We assume that unused cells are linked in an available space list, headed by avail, and that available cells are linked by their right-sibling fields. Figure 3.18 shows the old (solid) and the new (dashed) pointers.
function CREATE2 ( v: labeltype; T1, T2: integer ): integer;
{ returns new tree with root v, having T1 and T2 as subtrees }
var
temp: integer; { holds index of first available cell
for root of new tree }
begin
temp := avail;
avail := cellspace [avail].right_sibling;
cellspace[temp].leftmost_child := T1;
cellspace[temp].label := v;
cellspace[temp].right_sibling := 0;
cellspace[T1].right_sibling := T2;
cellspace[T2].right_sibling := 0; { not necessary;
that field should be 0 as the cell was formerly a root }
return (temp)
end; { CREATE2 }
Fig. 3.17. The function CREATE2.

Fig. 3.18. Pointer changes produced by CREATE2.
Alternatively, we can use less space but more time if we put in the right-sibling field of the rightmost child a pointer to the parent, in place of the null pointer that would otherwise be there. To avoid confusion, we need a bit in every cell indicating whether the right-sibling field holds a pointer to the right sibling or to the parent.
Given a node, we find its parent by following right-sibling pointers until we find one that is a parent pointer. Since all siblings have the same parent, we thereby find our way to the parent of the node we started from. The time required to find a node's parent in this representation depends on the number of siblings a node has.
The tree we defined in Section 3.1 is sometimes called an ordered, oriented tree because the children of each node are ordered from left-to-right, and because there is an oriented path (path in a particular direction) from every node to its descendants. Another useful, and quite different, notion of "tree" is the binary tree, which is either an empty tree, or a tree in which every node has either no children, a left child, a right child, or both a left and a right child. The fact that each child in a binary tree is designated as a left child or as a right child makes a binary tree different from the ordered, oriented tree of Section 3.1.
Example 3.9. If we adopt the convention that left children are drawn extending to the left, and right children to the right, then Fig. 3.19 (a) and (b) represent two different binary trees, even though both "look like" the ordinary (ordered, oriented) tree of Fig. 3.20. However, let us emphasize that Fig. 3.19(a) and (b) are not the same binary tree, nor are either in any sense equal to Fig. 3.20, for the simple reason that binary trees are not directly comparable with ordinary trees. For example, in Fig. 3.19(a), 2 is the left child of 1, and 1 has no right child, while in Fig. 3.19(b), 1 has no left child but has 2 as a right child. In either binary tree, 3 is the left child of 2, and 4 is 2's right child.
The preorder and postorder listings of a binary tree are similar to those of an ordinary tree given on p. 78. The inorder listing of the nodes of a binary tree with root n, left subtree T1 and right subtree T2 is the inorder listing of T1 followed by n followed by the inorder listing of T2. For example, 35241 is the inorder listing of the nodes of Fig. 3.19(a).
A convenient data structure for representing a binary tree is to name the nodes 1, 2, . . . , n, and to use an array of records declared
var cellspace : array [1..maxnodes] of record leftchild: integer; rightchild: integer; end;
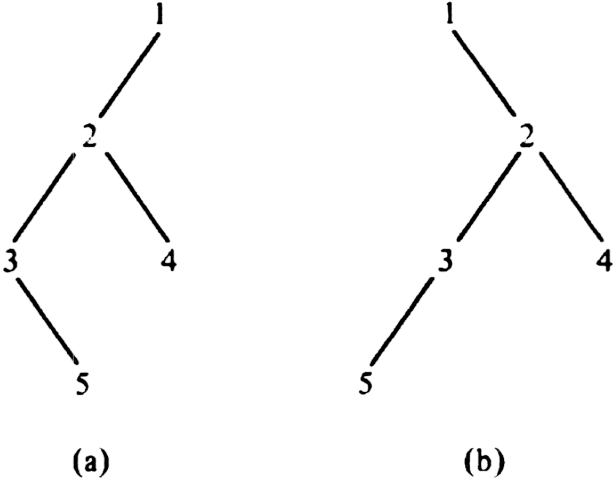
Fig. 3.19. Two binary trees.
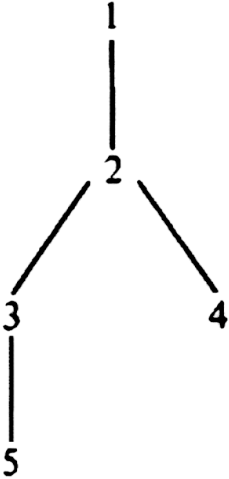
Fig. 3.20. An "ordinary" tree.
The intention is that cellspace[i].leftchild is the left child of node i, and rightchild is analogous. A value of 0 in either field indicates the absence of a child.
Example 3.10. The binary tree of Fig. 3.19(a) can be represented as shown in Fig. 3.21.
Let us give an example of how binary trees can be used as a data structure. The particular problem we shall consider is the construction of "Huffman codes." Suppose we have messages consisting of sequences of characters. In each message, the characters are independent and appear with a known
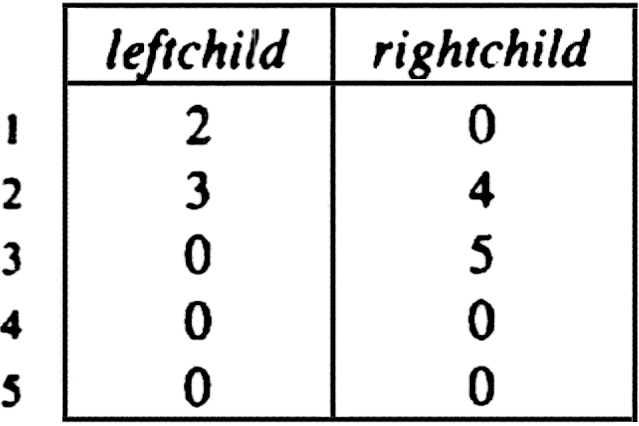
Fig. 3.21. Representation of a binary tree.
probability in any given position; the probabilities are the same for all positions. As an example, suppose we have a message made from the five characters a, b, c, d, e, which appear with probabilities .12, .4, .15, .08, .25, respectively.
We wish to encode each character into a sequence of 0's and 1's so that no code for a character is the prefix of the code for any other character. This prefix property allows us to decode a string of 0's and 1's by repeatedly deleting prefixes of the string that are codes for characters.
Example 3.11. Figure 3.22 shows two possible codes for our five symbol alphabet. Clearly Code 1 has the prefix property, since no sequence of three bits can be the prefix of another sequence of three bits. The decoding algorithm for Code 1 is simple. Just "grab" three bits at a time and translate each group of three into a character. Of course, sequences 101, 110, and 111 are impossible, if the string of bits really codes characters according to Code 1. For example, if we receive 001010011 we know the original message was bcd.
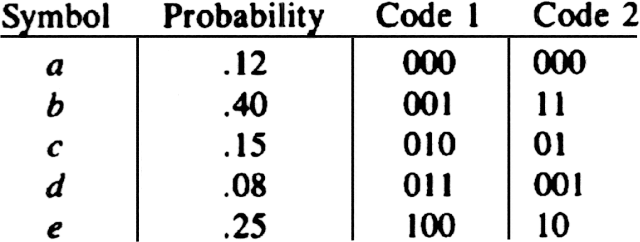
Fig. 3.22. Two binary codes.
It is easy to check that Code 2 also has the prefix property. We can decode a string of bits by repeatedly "grabbing" prefixes that are codes for characters and removing them, just as we did for Code 1. The only difference is that here, we cannot slice up the entire sequence of bits at once, because whether we take two or three bits for a character depends on the bits. For example, if a string begins 1101001, we can again be sure that the characters coded were bcd. The first two bits, 11, must have come from b, so we can remove them and worry about 01001. We then deduce that the bits 01 came from c, and so on.
The problem we face is: given a set of characters and their probabilities, find a code with the prefix property such that the average length of a code for a character is a minimum. The reason we want to minimize the average code length is to compress the length of an average message. The shorter the average code for a character is, the shorter the length of the encoded message. For example, Code 1 has an average code length of 3. This is obtained by multiplying the length of the code for each symbol by the probability of occurrence of that symbol. Code 2 has an average length of 2.2, since symbols a and d, which together appear 20% of the time, have codes of length three, and the other symbols have codes of length two.
Can we do better than Code 2? A complete answer to this question is to exhibit a code with the prefix property having an average length of 2.15. This is the best possible code for these probabilities of symbol occurrences. One technique for finding optimal prefix codes is called Huffman's algorithm. It works by selecting two characters a and b having the lowest probabilities and replacing them with a single (imaginary) character, say x, whose probability of occurrence is the sum of the probabilities for a and b. We then find an optimal prefix code for this smaller set of characters, using this procedure recursively. The code for the original character set is obtained by using the code for x with a 0 appended as the code for a and with a 1 appended as a code for b.
We can think of prefix codes as paths in binary trees. Think of following a path from a node to its left child as appending a 0 to a code, and proceeding from a node to its right child as appending a 1. If we label the leaves of a binary tree by the characters represented, we can represent any prefix code as a binary tree. The prefix property guarantees no character can have a code that is an interior node, and conversely, labeling the leaves of any binary tree with characters gives us a code with the prefix property for these characters.
Example 3.12. The binary trees for Code 1 and Code 2 of Fig. 3.22 are shown in Fig. 3.23(a) and (b), respectively.
We shall implement Huffman's algorithm using a forest (collection of trees), each of which has its leaves labeled by characters whose codes we desire to select and whose roots are labeled by the sum of the probabilities of all the leaf labels. We call this sum the weight of the tree. Initially, each character is in a one-node tree by itself, and when the algorithm ends, there will be only one tree, with all the characters at its leaves. In this tree, the path from the root to any leaf represents the code for the label of that leaf, according to the left = 0, right = 1 scheme of Fig. 3.23.
The essential step of the algorithm is to select the two trees in the forest that have the smallest weights (break ties arbitrarily). Combine these two trees into one, whose weight is the sum of the weights of the two trees. To combine the trees we create a new node, which becomes the root and has the
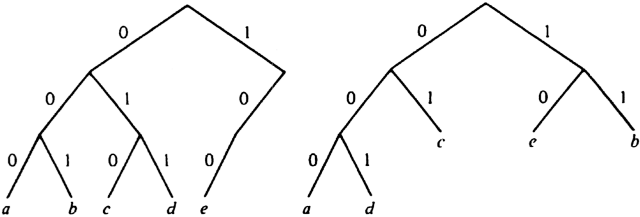
Fig. 3.23. Binary trees representing codes with the prefix property.
roots of the two given trees as left and right children (which is which doesn't matter). This process continues until only one tree remains. That tree represents a code that, for the probabilities given, has the minimum possible average code length.
Example 3.13. The sequence of steps taken for the characters and probabilities in our running example is shown in Fig. 3.24. From Fig. 3.24(e) we see the code words for a, b, c, d, and e are 1111, 0, 110, 1110, and 10. In this example, there is only one nontrivial tree, but in general, there can be many. For example, if the probabilities of b and e were .33 and .32, then after Fig. 3.24(c) we would combine b and e, rather than attaching e to the large tree as we did in Fig. 3.24(d).
Let us now describe the needed data structures. First, we shall use an array TREE of records of the type
record leftchild: integer; rightchild: integer; parent: integer; end
to represent binary trees. Parent pointers facilitate finding paths from leaves to roots, so we can discover the code for a character. Second, we use an array ALPHABET of records of type
record
symbol: char;
probability: real;
leaf: integer { cursor into tree }
end
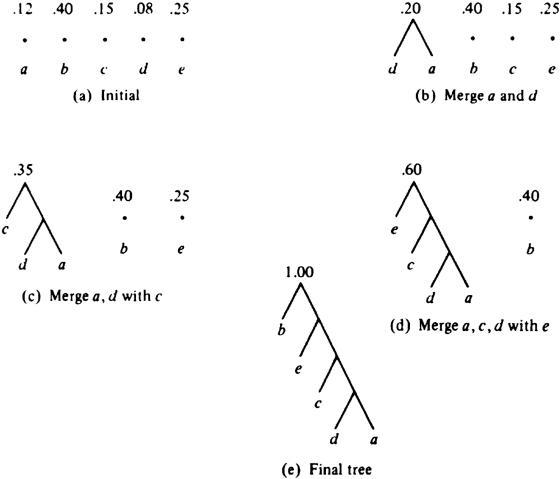
(e) Final tree
Fig. 3.24. Steps in the construction of a Huffman tree.
to associate, with each symbol of the alphabet being encoded, its corresponding leaf. This array also records the probability of each character. Third, we need an array FOREST of records that represent the trees themselves. The type of these records is
record
weight: real;
root: integer { cursor into tree }
end
The initial values of all these arrays, assuming the data of Fig. 3.24(a), are shown in Fig. 3.25. A sketch of the program to build the Huffman tree is shown in Fig. 3.26.
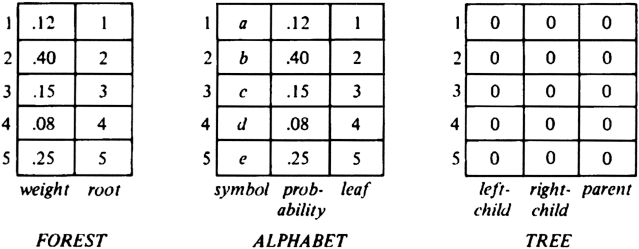
Fig. 3.25. Initial contents of arrays.
(1) while there is more then one tree in the forest do
begin
(2) i := index of the tree in FOREST with smallest weight;
(3) j := index of the tree in FOREST with second smallest weight;
(4) create a new node with left child FOREST[i].root and
right child FOREST[j].root;
(5) replace tree i in FOREST by a tree whose root
is the new node and whose weight is
FOREST[i].weight +
FOREST[j].weight;
(6) delete tree j from FOREST
end;
Fig. 3.26. Sketch of Huffman tree construction.
To implement line (4) of Fig. 3.26, which increases the number of cells of the TREE array used, and lines (5) and (6), which decrease the number of utilized cells of FOREST, we shall introduce cursors lasttree and lastnode, pointing to FOREST and TREE, respectively. We assume that cells 1 to lasttree of FOREST and 1 to lastnode of TREE are occupied.† We assume that arrays of Fig. 3.25 have some declared lengths, but in what follows we omit comparisons between these limits and cursor values.
procedure lightones ( var least, second: integer );
{ sets least and second to the indices in FOREST of
the trees of smallest weight. We assume lasttree ?/FONT>2. }
var
i: integer;
begin { initialize least and second, considering first two trees }
if FOREST[1].weight < = FOREST[2].weight
then
begin least := 1; second := 2 end
else
begin least := 2; second := 1 end;
{ Now let i run from 3 to lasttree. At each iteration
least is the tree of smallest weight among the first i trees
in FOREST, and second is the next smallest of these }
for i := 3 to lasttree do
if FOREST[i].weight <
FOREST[least].weight then
begin second := least; least := i
end
else if FOREST[i].weight <
FOREST[second].weight then
second: = i
end; { lightones }
function create ( lefttree, righttree: integer ): integer;
{ returns new node whose left and right children are
FOREST[lefttree].root and
FOREST[righttree].root }
begin
lastnode := lastnode + 1;
{ cell for new node is TREE[lastnode] }
TREE[lastnode].leftchild : =
FOREST[lefttree].root;
TREE[lastnode].rightchild : =
FOREST[righttree].root;
{ now enter parent pointers for new node and its children }
TREE[lastnode].parent := 0;
TREE[FOREST[lefttree].root].parent :=
lastnode;
TREE[FOREST[righttree].root].parent :=
lastnode;
return(lastnode)
end; { create }
Fig. 3.27. Two procedures.
Figure 3.27 shows two useful procedures. The first implements lines (2) and (3) of Fig. 3.26 to select indices of the two trees of smallest weight. The second is the command create(n1, n2) that creates a new node and makes n1 and n2 its left and right children.
Now the steps of Fig. 3.26 can be described in greater detail. A procedure Huffman, which has no input or output, but works on the global structures of Fig. 3.25, is shown in Fig. 3.28.
procedure Huffman;
var
i, j: integer; { the two trees of least weight in FOREST }
newroot: integer;
begin
while lasttree > 1 do begin
lightones(i, j);
newroot := create(i, j);
{ Now replace tree i by the tree whose root is newroot }
FOREST[i].weight := FOREST[i].weight +
FOREST[j].weight;
FOREST[i].root := newroot;
{ next, replace tree j, which is no longer needed, by lasttree,
and shrink FOREST by one }
FOREST[j] := FOREST[lasttree];
lasttree := lasttree - 1
end
end; { Huffman }
Fig. 3.28. Huffman's algorithm.
Figure 3.29 shows the data structure of Fig. 3.25 after lasttree has been reduced to 3, that is, when the forest looks like Fig. 3.24(c).
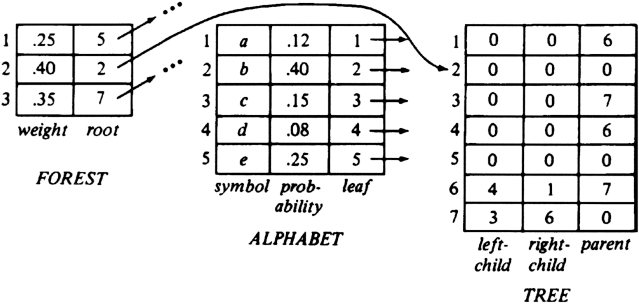
Fig. 3.29. Tree data structure after two iterations.
After completing execution of the algorithm, the code for each symbol can be determined as follows. Find the symbol in the symbol field of the ALPHABET array. Follow the leaf field of the same record to get to a record of the TREE array; this record corresponds to the leaf for that symbol. Repeatedly follow the parent pointer from the "current" record, say for node n, to the record of the TREE array for its parent p. Remember node n, so it is possible to examine the leftchild and rightchild pointers for node p and see which is n. In the former case, print 0, in the latter print 1. The sequence of bits printed is the code for the symbol, in reverse. If we wish the bits printed in the correct order, we could push each onto a stack as we go up the tree, and then repeatedly pop the stack, printing symbols as we pop them.
Instead of using cursors to point to left and right children (and parents if we wish), we can use true Pascal pointers. For example, we might declare
type node = record leftchild: ?/FONT> node; rightchild: ?/FONT> node; parent: ?/FONT> node; end
For example, if we used this type for nodes of a binary tree, the function create of Fig. 3.27 could be written as in Fig. 3.30.
function create ( lefttree, righttree: ?/FONT> node ): ?/FONT> node;
var
root: ?/FONT> node;
begin
new(root);
root ?/FONT>.leftchild := lefttree;
root ?/FONT>.rightchild :=
righttree;
root ?/FONT>.parent := 0;
lefttree ?/FONT>.parent := root;
righttree ?/FONT>.parent := root;
return (root)
end; { create }
Fig. 3.30. Pointer-based implementation of binary trees.
| 3.1 | Answer the following questions about the tree of Fig. 3.31.
Fig. 3.31. A tree. |
|---|---|
| 3.2 | In the tree of Fig. 3.31 how many different paths of length three are there? |
| 3.3 | Write programs to compute the height of a tree using each of the three tree representations of Section 3.3. |
| 3.4 | List the nodes of Fig. 3.31 in
|
| 3.5 | If m and n are two different nodes in the same tree, show that exactly
one of the following statements is true:
|
| 3.6 | Place a check in row i and column j if the two conditions represented
by row i and column j can occur simultaneously.
For example, put a check in row 3 and column 2 if you believe that n can be a proper ancestor of m and at the same time n can precede m in inorder. |
| 3.7 | Suppose we have arrays PREORDER[n], INORDER[n], and POSTORDER[n] that give the preorder, inorder, and postorder positions, respectively, of each node n of a tree. Describe an algorithm that tells whether node i is an ancestor of node j, for any pair of nodes i and j. Explain why your algorithm works. |
| *3.8 | We can test whether a node m is a proper ancestor of a node n by testing whether m precedes n in X-order but follows n in Y-order, where X and Y are chosen from {pre, post, in}. Determine all those pairs X and Y for which this statement holds. |
| 3.9 | Write programs to traverse a binary tree in
|
| 3.10 | The level-order listing of the nodes of a tree first lists the root, then all nodes of depth 1, then all nodes of depth 2, and so on. Nodes at the same depth are listed in left-to-right order. Write a program to list the nodes of a tree in level-order. |
| 3.11 | Convert the expression ((a + b) + c * (d + e) + f) *
(g + h) to a
|
| 3.12 | Draw tree representations for the prefix expressions
|
| 3.13 | Let T be a tree in which every nonleaf node has two children. Write
a program to convert
|
| 3.14 | Write a program to evaluate
|
| 3.15 | We can define a binary tree as an ADT with the binary tree structure as a mathematical model and with operations such as LEFTCHILD(n), RIGHTCHILD(n), PARENT(n), and NULL(n). The first three operations return the left child, the right child, and the parent of node n (L if there is none) and the last returns true if and only if n is L. Implement these procedures using the binary tree representation of Fig. 3.21. |
| 3.16 | Implement the seven tree operations of Section 3.2 using the following
tree implementations:
|
| 3.17 | The degree of a node is the number of children it has. Show that in any binary tree the number of leaves is one more than the number of nodes of degree two. |
| 3.18 | Show that the maximum number of nodes in a binary tree of height h is 2h+1 - 1. A binary tree of height h with the maximum number of nodes is called a full binary tree. |
| *3.19 | Suppose trees are implemented by leftmost-child, right-sibling and parent pointers. Give nonrecursive preorder, postorder, and inorder traversal algorithms that do not use "states" or a stack, as Fig. 3.9 does. |
| 3.20 | Suppose characters a, b, c, d, e, f have probabilities .07, .09, .12, .22, .23, .27, respectively. Find an optimal Huffman code and draw the Huffman tree. What is the average code length? |
| *3.21 | Suppose T is a Huffman tree, and that the leaf for symbol a has greater depth than the leaf for symbol b. Prove that the probability of symbol b is no less than that of a. |
| *3.22 | Prove that Huffman's algorithm works, i.e., it produces an optimal code for the given probabilities. Hint: Use Exercise 3.21. |
Berge [1958] and Harary [1969] discuss the mathematical properties of trees. Knuth [1973] and Nievergelt [1974] contain additional information on binary search trees. Many of the works on graphs and applications referenced in Chapter 6 also cover material on trees.
The algorithm given in Section 3.4 for finding a tree with a minimal weighted path length is from Huffman [1952]. Parker [1980] gives some more recent explorations into that algorithm.
† Recall our discussion of recursion in Section 2.6 in which we illustrated how the implementation of a recursive procedure involves a stack of activation records. If we examine Fig. 3.8, we can observe that when PREORDER(n) is called, the active procedure calls, and therefore the stack of activation records, correspond to the calls of PREORDER for all the ancestors of n. Thus our nonrecursive preorder procedure, like the example in Section 2.6, models closely the way the recursive procedure is implemented.
† For the data reading phase, which we omit, we also need a cursor for the array ALPHABET as it fills with symbols and their probabilities.

