


This chapter discusses the basic strategies whereby memory space can be reused, or shared by different objects that grow and shrink in arbitrary ways. For example, we shall discuss methods that maintain linked lists of available space, and "garbage collection" techniques, where we figure out what is available only when it seems we have run out of available space.
There are numerous situations in computer system operation when a limited memory resource is managed, that is, shared among several "competitors." A programmer who does not engage in the implementation of systems programs (compilers, operating systems, and so on) may be unaware of such activities, since they frequently are carried out "behind the scenes." As a case in point, Pascal programmers are aware that the procedure new(p) will make pointer p point to a new object of the correct type. But where does space for that object come from? The procedure new has access to a large region of memory, called the "heap," that the program variables do not use. From that region, an unused block of consecutive bytes sufficient to hold an object of the type that p points to is selected, and p is made to hold the address of the first byte of that block. But how does the procedure new know which bytes of the memory are "unused'"? Section 12.4 suggests the answer.
Even more mysterious is what happens if the value of p is changed, either by an assignment or by another call to new(p). The block of memory p pointed to may now be inaccessible, in the sense that there is no way to get to it through the program's data structures, and we could reuse its space. On the other hand, before p was changed, the value of p may have been copied into some other variable. In that case, the memory block is still part of the program's data structures. How do we know whether a block in the memory region used by procedure new is no longer needed by the program?
Pascal's sort of memory management is only one of several different types. For example, in some situations, like Pascal, objects of different sizes share the same memory space. In others, all objects sharing the space are of the same size. This distinction regarding object sizes is one way we can classify the kinds of memory management problems we face. Some more examples follow.
Example 12.1. In Fig. 12.1(a) we see the heap that might be used by a Snobol program with three variables, A, B, and C. The value of any variable in Snobol is a character string, and in this case, the value of both A and B is 'OH HAPPY DAY' and the value of C is 'PASS THE SALT'.
We have chosen to represent character strings by pointers to blocks of memory in the heap. These blocks have their first 2 bytes (the number 2 is a typical value that could be changed) devoted to an integer giving the length of the string. For example, 'OH HAPPY DAY' has length 12, counting the blanks between words, so the value of A (and of B) occupies 14 bytes.
If the value of B were changed to 'OH HAPPY DAZE', we would find an empty block in the heap 15 bytes long to store the new value of B, including the 2 bytes for the length. The pointer for B is made to point to the new value, as shown in Fig. 12.1(b). The block holding integer 12 and 'OH HAPPY DAY' is still useful, since A points to it. If the value of A now changes, that block would become useless and could be reused. How one tells conveniently that there are no pointers to such a block is a major subject of this chapter.
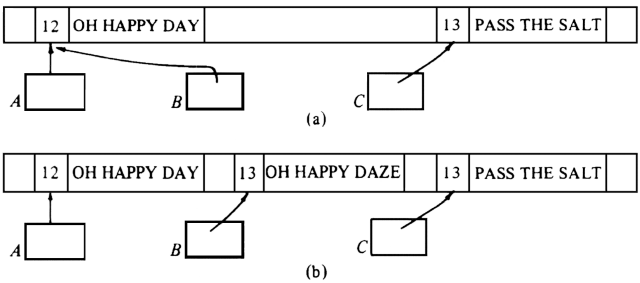
Fig. 12.1. String variables in a heap.
In the four examples above, we can see differences along at least two orthogonal "dimensions." The first issue is whether objects sharing storage are or are not of equal length. In the first two examples, Lisp programs and file storage, the objects, which are Lisp cells in one case and blocks holding parts of files in the other, are of the same size. This fact allows certain simplifications of the memory management problem. For example, in Lisp implementation, a region of memory is divided into spaces, each of which can hold exactly one cell. The management problem is to find empty spaces to hold newly-created cells, and it is never necessary to store a cell in such a position that it overlaps two spaces. Similarly, in the second example, a disk is divided into equal sized blocks, and each block is assigned to hold part of one file; we never use a block to store parts of two or more files, even if a file ends in the middle of a block.
In contrast, the third and fourth examples, covering memory allocation by a multiprogramming system and heap management for those languages that deal with variables whose values are "big" objects, speak of allocating space in blocks of different sizes. This requirement presents certain problems that do not appear in the fixed-length case. For example, we fear fragmentation, a situation in which there is much unused space, but it is in such small pieces that space for one large object cannot be found. We shall say more about heap management in Sections 12.4 and 12.5.
The second major issue is whether garbage collection, a charming term for the recovery of unused space, is done explicitly or implicitly, that is, by program command or only in response to a request for space that cannot be satisfied otherwise. In the case of file management, when a file is deleted, the blocks used to hold it are known to the file system. For example, the file system could record the address of one or more "master blocks" for each file in existence; the master blocks list the addresses of all the blocks used for the file. Thus, when a file is deleted, the file system can explicitly make available for reuse all the blocks used for that file.
In contrast, Lisp cells, when they become detached from the data structures of the program, continue to occupy their memory space. Because of the possibility of multiple pointers to a cell, we cannot tell when a cell is completely detached; therefore we cannot explicitly collect cells as we do blocks of a deleted file. Eventually, all memory spaces will become allocated to useful or useless cells, and the next request for space for another cell implicitly will trigger a "garbage collection." At that time, the Lisp interpreter marks all the useful cells, by an algorithm such as the one we shall discuss in Section 12.3, and then links all the blocks holding useless cells into an available space list, so they can be reused.
Figure 12.2 illustrates the four kinds of memory management and gives an example of each. We have already discussed the fixed block size examples in Fig. 12.2. The management of main memory by a multiprogramming system is an example of explicit reclamation of variable length blocks. That is, when a program terminates, the operating system, knowing what area of memory was given to the program, and knowing no other program could be using that space, makes the space available immediately to another program.
The management of a heap in Snobol or many other languages is an example of variable length blocks with garbage collection. As for Lisp, a typical Snobol interpreter does not try to reclaim blocks of memory until it runs out of space. At that time the interpreter performs a garbage collection as the Lisp interpreter does, but with the additional possibility that strings will be moved around the heap to reduce fragmentation, and that adjacent free blocks will be combined to make larger blocks. Notice that the latter two steps are pointless in the Lisp environment.
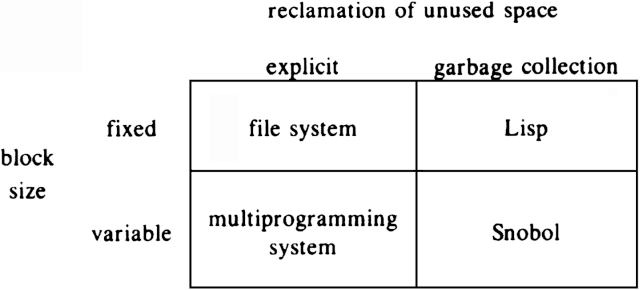
Fig. 12.2. Examples of the four memory management strategies.
Let us imagine we have a program that manipulates cells each consisting of a pair of fields; each field can be a pointer to a cell or can hold an "atom." The situation, of course, is like that of a program written in Lisp, but the program may be written in almost any programming language, even Pascal, if we define cells to be of a variant record type. Empty cells available for incorporation into a data structure are kept on an available space list, and each program variable is represented by a pointer to a cell. The cell pointed to may be one cell of a large data structure.
Example 12.2. In Fig. 12.3 we see a possible structure. A, B, and C are variables; lower case letters represent atoms. Notice some interesting phenomena. The cell holding atom a is pointed to by the variable A and by another cell. The cell holding atom c is pointed to by two different cells. The cells holding g and h are unusual in that although each points to the other, they cannot be reached from any of the variables A, B, or C, nor are they on the available space list.
Let us assume that as the program runs, new cells may on occasion be seized from the available space list. For example, we might wish to have the null pointer in the cell with atom c in Fig. 12.3 replaced by a pointer to a new cell that holds atom i and a null pointer. This cell will be removed from the top of the available space list. It is also possible that from time to time, pointers will change in such a way that cells become detached from the program variables, as the cells holding g and h in Fig. 12.3 have been. For example, the cell holding c may, at one time, have pointed to the cell holding g. As another example, the value of variable B may at some time change, which would, if nothing else has changed, detach the cell now pointed to by B in Fig. 12.3 and also detach the cell holding d and e (but not the cell holding c, since it would still be reached from A). We call cells not reachable from any variable and not on the available space list inaccessible.
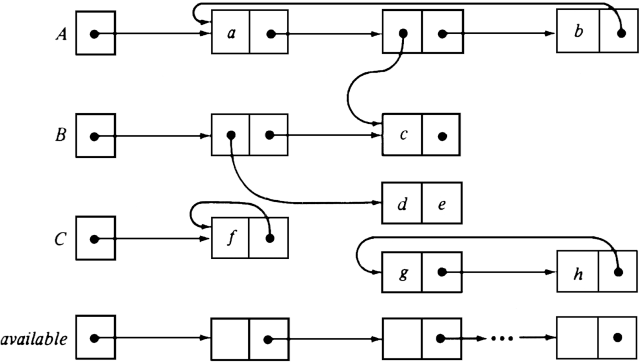
Fig. 12.3. A network of cells.
When cells are detached, and therefore are no longer needed by the program, it would be nice if they found their way back onto the available space list, so they could be reused. If we don't reclaim such cells, we shall eventually reach the unacceptable situation where the program is not using all the cells, yet it wants a cell from available space, and the available space list is empty. It is then that a time-consuming garbage collection must be performed. This garbage collection step is "implicit," in the sense that it was not explicitly called for by the request for space.
One seemingly attractive approach to detecting inaccessible cells is to include in each cell a reference count, that is, an integer-valued field whose value equals the number of pointers to the cell. It is easy to maintain reference counts. When making some pointer point to a cell, add one to the reference count for that cell. When a non-null pointer is reassigned, first decrease by one the reference count for the cell pointed to. If a reference count reaches zero, the cell is inaccessible, and it can be returned to the available list.
Unfortunately, reference counts don't always work. The cells with g and h in Fig. 12.3 are inaccessible cells linked in a cycle. Their reference counts are each 1, so we would not return them to the available list. One can attempt to detect cycles of inaccessible cells in a variety of ways, but it is probably not worth doing so. Reference counts are useful for structures that do not have pointer cycles. One example of a structure with no possibility of cycles is a collection of variables pointing to blocks holding data, as in Fig. 12. I. There, we can do explicit garbage collection simply by collecting a block when its reference count reaches zero. However, when data structures allow pointer cycles, the reference count strategy is usually inferior, both in terms of the space needed in cells and the time taken dealing with the issue of inaccessible cells, to another approach which we shall discuss in the next section.
Let us now give an algorithm for finding which of a collection of cells of the types suggested in Fig. 12.3 are accessible from the program variables. We shall define the setting for the problem precisely by defining a cell type in Pascal that is a variant record type; the four variants, which we call PP, PA, AP, and AA, are determined by which of the two data fields are pointers and which are atoms. For example, PA means the left field is a pointer and the right field an atom. An additional boolean field in cells, called mark, indicates whether the cell has been found accessible. That is, by setting mark to true when garbage collecting, we "mark" the cell, indicating it is accessible. The important type definitions are shown in Fig. 12.4.
type
atomtype = { some appropriate type;
preferably of the same size as pointers }
patterns = (PP, PA, AP, AA);
celltype = record
mark: boolean;
case pattern: patterns of
PP: (left: ?/FONT> celltype; right:
?/FONT> celltype);
PA: (left: ?/FONT> celltype; right:
atomtype);
AP: (left: atomtype; right: ?/FONT> celltype);
AA: (left: atomtype; right: atomtype);
end;
Fig. 12.4. Definition of the type for cells.
We assume there is an array of cells, taking up most of the memory, and some collection of variables, that are pointers to cells. For simplicity, we assume there is only one variable, called source, pointing to a cell, but the extension to many variables is not hard. † That is, we declare
var source: ?/FONT> celltype; memory: array [1..memorysize ] of celltype;
To mark the cells accessible from source, we first "unmark" all cells, accessible or not, by running down the array memory and setting the mark field to false. Then we perform a depth-first search of the graph emanating from source, marking all cells visited. The cells visited are exactly those that are accessible. We then traverse the array memory and add to the available space list all unmarked cells. Figure 12.5 shows a procedure dfs to perform the depth-first search; dfs is called by the procedure collect that unmarks all cells, and then marks accessible cells by calling dfs. We do not show the code linking the available space list because of the peculiarities of Pascal. For example, while we could link available cells using either all left or all right cells, since pointers and atoms are assumed the same size, we are not permitted to replace atoms by pointers in cells of variant type AA.
(1) procedure dfs ( currentcell: ?/FONT>
celltype );
{ If current cell was marked, do nothing. Otherwise, mark
it and call dfs on any cells pointed to by the current cell }
begin
(2) with currentcell?/FONT> do
(3) if mark = false then begin
(4) mark := true;
(5) if (pattern = PP ) or (pattern = PA ) then
(6) if left <> nil then
(7) dfs (left);
(8) if (pattern = PP ) or (pattern = AP ) then
(9) if right <> nil then
(10) dfs (right)
end
end; { dfs }
(11) procedure collect;
var
i: integer;
begin
(12) for i := 1 to memorysize do { "unmark"
all cells }
(13) memory[i].mark := false;
(14) dfs(source); { mark accessible cells }
(15) { the code for the collection goes here }
end; { collect }
Fig. 12.5. Algorithm for marking accessible cells.
The algorithm of Fig. 12.5 has a subtle flaw. In a computing environment where memory is limited, we may not have the space available to store the stack required for recursive calls to dfs. As discussed in Section 2.6, each time dfs calls itself, Pascal (or any other language permitting recursion) creates on "activation record" for that particular call to dfs. In general, an activation record contains space for parameters and variables local to the procedure, of which each call needs its own copy. Also necessary in each activation record is a "return address," the place to which control must go when this recursive call to the procedure terminates.
In the particular case of dfs, we only need space for the parameter and the return address (i.e., was it called by line (14) in collect or by line (7) or line (10) of another invocation of dfs). However, this space requirement is enough that, should all of memory be linked in a single chain extending from source (and therefore the number of active calls to dfs would at some time equal the length of this chain), considerably more space would be required for the stack of activation records than was allotted for memory. Should such space not be available, it would be impossible to carry out the marking.
Fortunately, there is a clever algorithm, known as the Deutsch-Schorr-Waite Algorithm, for doing the marking "in place." The reader should convince himself that the sequence of cells upon which a call to dfs has been made but not yet terminated indeed forms a path from source to the cell upon which the current call to dfs was made. Thus we can use a nonrecursive version of dfs, and instead of a stack of activation records to record the path of cells from source to the cell currently being examined, we can use the pointer fields along that path to hold the path itself. That is, each cell on the path, except the last, holds in either the left or right field, a pointer to its predecessor, the cell immediately closer to source. We shall describe the Deutsch-Schorr-Waite algorithm with an extra, one-bit field, called back. Field back is of an enumerated type (L, R), and tells whether field left or field right points to the predecessor. Later, we shall discuss how the information in back can be held in the pattern field, so no extra space in cells is required.
The new procedure for nonrecursive depth-first search, which we call nrdfs, uses a pointer current to point to the current cell, and a pointer previous to the predecessor of the current cell. The variable source points to a cell source1, which has a pointer in its right field only.† Before marking, source1 is initialized to have back = R, and its right field pointing to itself. The cell ordinarily pointed to by source1, is pointed to by current, and source1 is pointed to by previous. We halt the marking operation when current = previous, which can only occur when they both point to source1, the entire structure having been searched.
Example 12.3. Figure 12.6(a) shows a possible structure emanating from source. If we depth-first search this structure, we visit (1), (2), (3) and (4), in that order. Figure 12.6(b) shows the pointer modifications made when cell (4) is current. The value of the back field is shown, although fields mark and pattern are not. The current path is from (4) to (3) to (2) to (1) back to sourcel; it is represented by dashed pointers. For example, cell (1) has back = L, since the left field of (1), which in Fig. 12.6(a) held a pointer to (2), is being used in Fig. 12.6(b) to hold part of the path. Now the left field in (1) points backwards, rather than forwards along the path; however, we shall restore that pointer when the depth-first search finally retreats from cell (2) back to (1). Similarly, in cell (2), back = R, and the right field of (2) points backwards along the path to (1), rather than ahead to (3), as it did in Fig. 12.6(a).
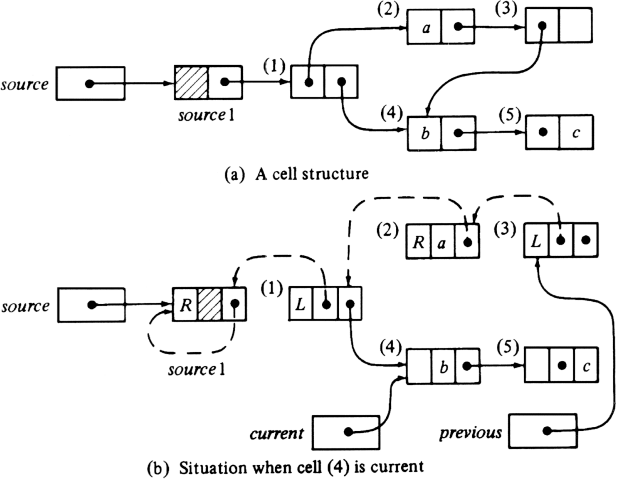
Fig. 12.6. Using pointers to represent the path back to source.
There are three basic steps to performing the depth-first search. They are:
One fortuitous coincidence is that each of the steps of Fig. 12.7 can be viewed as the simultaneous rotation of three pointers. For example, in Fig. 12.7(a), we simultaneously replace (previous, current, current?/FONT>.left) by (current, current?/FONT>.left, previous), respectively. The simultaneity must be emphasized; the location of current?/FONT>.left does not change when we assign a new value to current. To perform these pointer modifications, a procedure rotate, shown in Fig. 12.8, is naturally useful. Note especially that the passing of parameters by reference assures that the locations of the pointers are established before any values change.
Now we turn to the design of the nonrecursive marking procedure nrdfs. This procedure is one of these odd processes that is most easily understood when written with labels and gotos. Particularly, there are two "states" of the procedure, "advancing," represented by label 1, and "retreating," represented by label 2. We enter the first state initially, and also whenever we have moved to a new cell, either by an advance step or a switch step. In this state, we attempt another advance step, and only retreat or switch if we are blocked. We can be blocked for two reasons: (l) The cell just reached is already marked, or (2) there are no nonnull pointers in the cell. When blocked, we change to the second, or "retreating" state.
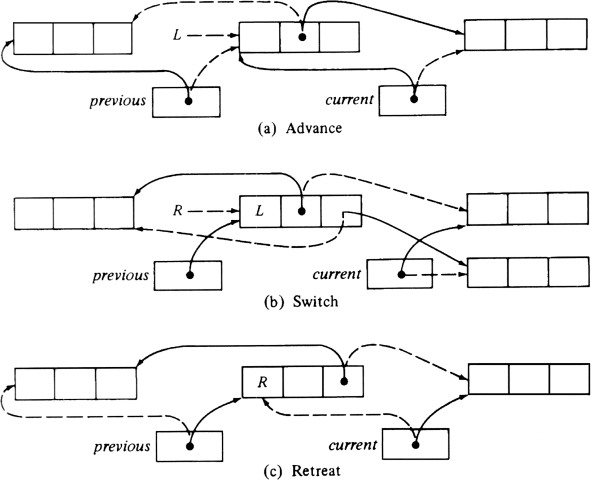
Fig. 12.7. Three basic steps.
procedure rotate ( var p1, p2, p3: ?/FONT> celltype );
var
temp: ?/FONT> celltype;
begin
temp := p1;
p1 := p2;
p2 := p3;
p3 := temp
end; { rotate }
Fig. 12.8. Pointer modification procedure.
The second state is entered whenever we retreat, or when we cannot stay in the advancing state because we are blocked. In the retreating state we check whether we have retreated back to the dummy cell source1. As discusssed before, we shall recognize this situation because previous = current, in which case we go to state 3. Otherwise, we decide whether to retreat and stay in the retreating state or switch and enter the advancing state. The code for nrdfs is shown in Fig. 12.9. It makes use of functions blockleft, blockright, and block, which test if the left or right fields of a cell, or both, have an atom or null pointer. block also checks for a marked cell.
function blockleft ( cell: celltype ): boolean;
{ test if left field is atom or null pointer }
begin
with cell do
if (pattern = PP) or (pattern = PA)
then
if left <> nil then return (false);
return (true)
end; { blockleft }
function blockright ( cell : celltype ): boolean;
{ test if right field is atom or null pointer }
begin
with cell do
if (pattern = PP) or (pattern = AP)
then
if right <> nil then
return (false);
return (true)
end; { blockright }
function block ( cell: celltype ): boolean;
{ test if cell is marked or contains no nonnull pointers }
begin
if (cell.mark = true) or blockleft (cell) and
blockright (cell) then
return (true)
else
return (false)
end; { block }
procedure nrdfs; { marks cells accessible from source }
var
current, previous: ?/FONT> celltype;
begin { initialize }
current := source 1?/FONT>.right; { cell
pointed to by source1 }
previous := source 1; { previous points to source1 }
source 1?/FONT>.back := R;
source 1?/FONT>.right := source 1; {
source1 points to itself }
source 1?/FONT>.mark := true;
state 1: { try to advance }
if block (current?/FONT>) then begin
{ prepare to retreat }
current?/FONT>.mark := true;
goto state2
end
else begin { mark and advance }
current?/FONT>.mark := true;
if blockleft (current?/FONT>) then
begin { follow right pointer }
current?/FONT>.back := R;
rotate(previous, current, current?/FONT>.right); { implements
changes of Fig. 12.7(a), but following right pointer }
goto state1
end
else begin { follow left pointer }
current?/FONT>.back := L;
rotate (previous, current, current?/FONT>.left);
{ implements changes of Fig. 12.7(a) }
goto state1
end
end;
state2: { finish, retreat or switch }
if previous = current then { finish }
goto state3
else if (previous?/FONT>.back = L )
and
not blockright (previous?/FONT>) then
begin { switch }
previous?/FONT>.back := R;
rotate (previous?/FONT>.left,
current, previous?/FONT>.right);
{ implements changes of Fig. 12.7(b) }
goto state1
end
else if previous?/FONT>.back = R
then { retreat }
rotate (previous, previous?/FONT>.right, current)
{ implements changes of Fig. 12.7(c) }
else { previous?/FONT>.back = L }
rotate (previous, previous?/FONT>.left,
current);
{ implements changes of Fig. 12.7(c), but with
left field of previous cell involved in the path }
goto state2
end;
state3: { put code to link unmarked cells on available list here }
end; { nrdfs }
Fig. 12.9. Nonrecursive marking algorithm.
It is possible, although unlikely, that the extra bit used in cells for the field back might cause cells to require an extra byte, or even an extra word. In such a case, it is comforting to know that we do not really need the extra bit, at least not if we are programming in a language that, unlike Pascal, allows the bits of the field pattern to be used for purposes other than those for which they were declared: designators of the variant record format. The "trick" is to observe that if we are using the field back at all, because its cell is on the path back to source1, then the possible values of field pattern are restricted. For example, if back = L, then we know the pattern must be PP or PA, since evidently the field left holds a pointer. A similar observation can be made when back = R. Thus, if we have two bits available to represent both pattern and (when needed) back, we can encode the necessary information as in Fig. 12.10, for example.
The reader should observe that in the program of Fig. 12.9, we always know whether back is in use, and thus can tell which of the interpretations in Fig. 12.10 is applicable. Simply, when current points to a record, the field back in that record is not in use; when previous points to it, it is. Of course, as these pointers move, we must adjust the codes. For example, if current points to a cell with bits 10, which we interpret according to Fig. 12.10 as pattern = AP, and we decide to advance, so previous will now point to this cell, we make back=R, as only the right field holds a pointer, and the appropriate bits are 11. Note that if the pattern were AA, which has no representation in the middle column of Fig. 12.10, we could not possibly want previous to point to the cell, as there are no pointers to follow in an advancing move.

Fig. 12.10. Interpreting two bits as pattern and back.
Let us now consider the management of a heap, as typified by Fig. 12.1, where there is a collection of pointers to allocated blocks. The blocks hold data of some type. In Fig. 12.1, for example, the data are character strings. While the type of data stored in the heap need not be character strings, we assume the data contain no pointers to locations within the heap.
The problem of heap management has aspects that make it both easier and harder than the maintenance of list structures of equal-sized cells as discussed in the previous section. The principal factor making the problem easier is that marking used blocks is not a recursive process; one has only to follow the external pointers to the heap and mark the blocks pointed to. There is no need for a depth-first search of a linked structure or for anything like the Deutsch-Schorr-Waite algorithm.
On the other hand, managing the available space list is not as simple as in Section 12.3. We might imagine that the empty regions (there are three empty regions in Fig. 12.1(a), for example) are linked together as suggested in Fig. 12.11. There we see a heap of 3000 words divided into five blocks. Two blocks of 200 and 600 words, hold the values of X and Y. The remaining three blocks are empty, and are linked in a chain emanating from avail, the header for available space.
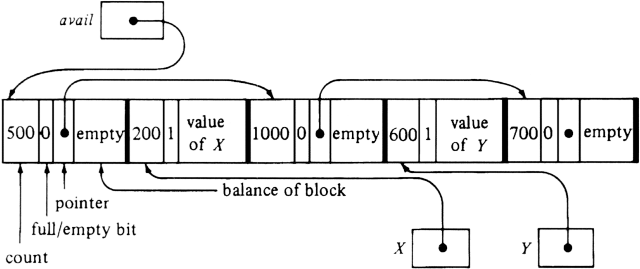
Fig. 12.11. A heap with available space list.
In order that empty blocks may be found when they are needed to hold new data, and blocks holding useless data may be made available, we shall throughout this section make the following assumptions about blocks.
One interesting consequence of the above assumptions is that blocks must be capable of storing data sometimes (when in use) and pointers at other times (when unused) in precisely the same place. It is thus impossible or very inconvenient to write programs that manipulate blocks of the kind we propose in Pascal or any other strongly typed language. Thus, this section must of necessity be discursive; only pseudo-Pascal programs can be written, never real Pascal programs. However, there is no problem writing programs to do the things we describe in assembly languages or in most systems programming languages such as C.
To see one of the special problems that heap management presents, let us suppose that the variable Y of Fig. 12.11 changes, so the block representing Y must be returned to available space. We can most easily insert the new block at the beginning of the available list, as suggested by Fig. 12.12. In that figure, we see an instance of fragmentation, the tendency for large empty areas to be represented on the available space list by "fragments," that is, several small blocks making up the whole. In the case in point, the last 2300 bytes of the heap in Fig. 12.12 are empty, yet the space is divided into three blocks of 1000, 600, and 700 bytes, and these blocks are not even in consecutive order on the available list. Without some form of garbage collection, it would be impossible to satisfy a request for, say, a block of 2000 bytes.
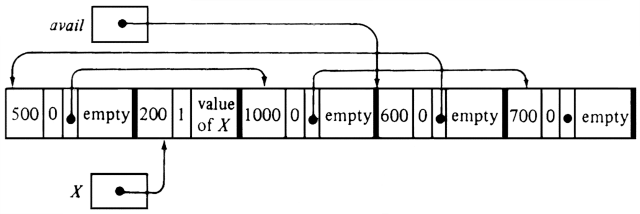
Fig. 12.12. After returning the block of Y.
Evidently, when returning a block to available space it would be desirable to look at the blocks to the immediate left and right of the block being made available. Finding the block to the right is easy. If the block being returned begins at position p and has count c, the block to the right begins at position p+c. If we know p (for example, the pointer Y in Fig. 12.11 holds the value p for the block made available in Fig. 12.12), we have only to read the bytes starting at position p, as many as are used for holding c, to obtain the value c. From byte p+c, we skip over the count field to find the bit that tells whether or not the block is empty. If empty, the blocks beginning at p and p + c can be combined.
Example 12.4. Let us assume the heap of Fig. 12.11 begins at position 0. Then the block for Y being returned begins in byte 1700, so p=1700 and c=600. The block beginning at p+c=2300 is also empty so we could combine them into one block beginning at 1700 with a count of 1300, the sum of the counts in the two blocks.
It is, however, not so easy to fix the available list after combining blocks. We can create the combined block by simply adding the count of the second block to c. However, the second block will still be linked in the available list and must be removed. To do so requires finding the pointer to that block from its predecessor on the available list. Several strategies present themselves; none is strongly recommended over the others.
Of the three methods, all but the second require time proportional to the length of the available list to return a block to available space and combine it with its right neighbor if that neighbor is empty. This time may or may not be prohibitive, depending on how long the list gets and what fraction of the total program time is spent manipulating the heap. The second method - doubly linking the available list - has only the penalty of an increased minimum size for blocks. Unfortunately, when we consider how to combine a returned block with its neighbor to the left, we see that double linking, like the other methods, is no help in finding left neighbors in less than the time it takes to scan the available list.
To find the block immediately to the left of the block in question is not so easy. The position p of a block and its count c, while they determine the position of the block to the right, give no clue as to where the block to the left begins. We need to find an empty block that begins in some position p1, and has a count c1, such that p1+c1=p. It ap>
As with the merger of a newly empty block with the block to its right, the first and third approaches to finding and merging with the block on the left require time proportional to the length of the available list. Method (2) again requires constant time, but it has a disadvantage beyond the problems involved with doubly linking the available list (which we suggested in connection with finding right neighbor blocks). While doubly linking the empty blocks raises the minimum block size, the approach cannot be said to waste space, since it is only blocks not used for storing data that get linked. However, pointing to left neighbors requires a pointer in used blocks as well as unused ones, and can justifiably be accused of wasting space. If the average block size is hundreds of bytes, the extra space for a pointer may be negligible. On the other hand, the extra space may be prohibitive if the typical block is only l0 bytes long.
To summarize the implications of our explorations regarding the question of how we might merge newly empty blocks with empty neighbors, we see three approaches to handling fragmentation.
(1) procedure merge;
var
(2) p, q: pointers to blocks;
{ p indicates left end of empty block being accumulated.
q indicates a block to the right of p that we
shall incorporate into block p if empty }
begin
(3) p:= leftmost block of heap;
(4) make available list empty;
(5) while p < right end of heap do
(6) if p points to a full block with count c then
(7) p := p + c { skip over full blocks }
(8) else begin { p points to the beginning
of a sequence of empty blocks; merge them }
(9) q := p + c; { initialize q to the next block }
(10) while q points to an empty block with some
count, say d, and q < right end of heap do begin
(11) add d to count of the block pointed to by p;
(12) q := q + d
end;
(13) insert block pointed to by p onto the available list;
(14) p := q
end
end; { merge }
Fig. 12.13. Merging adjacent empty blocks.
Example 12.5. As an example, consider the program of Fig. 12.13 applied to the heap of Fig. 12.12. Assume the leftmost byte of the heap is 0, so initially p=0. As c=500 for the first block, q is initialized to p + c=500. As the block beginning at 500 is full, the loop of lines (10)-(12) is not executed and the block consisting of bytes 0-499 is attached to the available list, by making avail point to byte 0 and putting a nil pointer in the designated place in that block (right after the count and full/empty bit). Then p is given the value 500 at line (14), and incremented to 700 at line (7). Pointer q is given value 1700 at line (9), then 2300 and 3000 at line (12), while at the same time, 600 and 700 are added to count 1000 in the block beginning at 700. As q exceeds the rightmost byte, 2999, the block beginning at 700, which now has count 2300, is inserted onto the available list. Then at line (14), p is set to 3000, and the outer loop ends at line (5).
As the total number of blocks and the number of available blocks are likely not to be too dissimilar, and the frequency with which no sufficiently large empty block can be found is likely to be low, we believe that method (3), doing the merger of adjacent empty blocks only when we run out of adequate space, is superior to (1) in any realistic situation. Method (2) is a possible competitor, but if we consider the extra space requirement and the fact that extra time is needed each time a block is inserted or deleted from the available list, we believe that (2) is preferable to (3) in extremely rare circumstances, and can probably be forgotten.
We have discussed in detail what should happen when a block is no longer needed and can be returned to available space. There is also the inverse process of providing blocks to hold new data items. Evidently we must select some available block and use some or all of it to hold the new data. There are two issues to address. First, which empty block do we select? Second, if we must use only part of the selected block, which part do we use?
The second issue can be dispensed with easily. If we are to use a block with count c, and we need d<c bytes from that block, we choose the last d bytes. In this way, we need only to replace count c by c - d, and the remaining empty block can stay as it is in the available list.†
Example 12.6. Suppose we need 400 bytes for variable W in the situation represented by Fig. 12.12. We might choose to take the 400 bytes out of the 600 in the first block on the available list. The situation would then be as shown in Fig. 12.14.
Choosing a block in which to place the new data is not so easy, since there are conflicting goals for such strategies. We desire, on one hand, to be able to quickly pick an empty block in which to hold our data and, on the other hand, to make a selection of an empty block that will minimize the fragmentation. Two strategies that represent extremes in the spectrum are known as "first-fit" and "best-fit." They are described below.
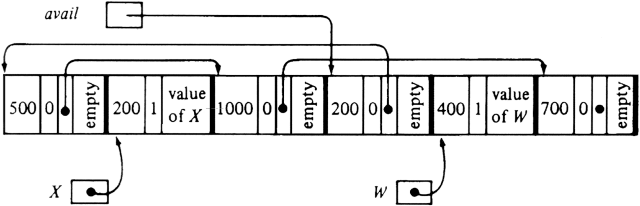
Fig. 12.14. Memory configuration.
c ?/FONT> d. Utilize the last d words of this block, as we have described above.Some observations about these strategies can be made. Best-fit is considerably slower than first-fit, since with the latter we can expect to find a fitting block fairly quickly on the average, while with best-fit, we are obliged to scan the entire available list. Best-fit can be speeded up if we keep separate available lists for blocks in various size ranges. For example, we could keep a list of available blocks between 1 and 16 bytes in length,† from 17- 32, 33-64, and so on. This "improvement" does not speed up first-fit appreciably, and in fact may slow it down if the statistics of block sizes are bad. (Compare looking for the first block of size at least 32 on the full available list and on the list for blocks of size 17-32, e.g.) A last observation is that we can define a spectrum of strategies between first-fit and best-fit by looking for a best-fit among the first k available blocks for some fixed k.
The best-fit strategy seems to reduce fragmentation compared with first-fit, in the sense that best-fit tends to produce very small "fragments", i.e., left-over blocks. While the number of these fragments is about the same as for first-fit, they tend to take up a rather small area. However, best-fit will not tend to produce "medium size fragments." Rather, the available blocks will tend to be either very small fragments or will be blocks returned to available space. As a consequence, there are sequences of requests that first-fit can satisfy but not best-fit, as well as vice-versa.
Example 12.7. Suppose, as in Fig. 12.12, the available list consists of blocks of sizes 600, 500, 1000, and 700, in that order. If we are using the first-fit strategy, and a request for a block of size 400 is made, we shall carve it from the block of size 600, that being the first on the list in which a block of size 400 fits. The available list now has blocks of size 200, 500, 1000, 700. We are thus unable to satisfy immediately three requests for blocks of size 600 (although we might be able to do so after merging adjacent empty blocks and/or moving utilized blocks around in the heap).
However, if we were using the best-fit strategy with available list 600, 500, 1000, 700, and the request for 400 came in, we would place it where it fit best, that is, in the block of 500, leaving a list of available blocks 600, 100, 1000, 700. We would, in that event, be able to satisfy three requests for blocks of size 600 without any form of storage reorganization.
On the other hand, there are situations where, starting with the list 600, 500, 1000, 700 again, best-fit would fail, while first-fit would succeed without storage reorganization. Let the first request be for 400 bytes. Best-fit would, as before, leave the list 600, 100, 1000, 700, while first-fit leaves 200, 500, 1000, 700. Suppose the next two requests are for 1000 and 700, so either strategy would allocate the last two empty blocks completely, leaving 600, 100 in the case of best-fit, and 200, 500 in the case of first-fit. Now, first-fit can honor requests for blocks of size 200 and 500, while best-fit obviously cannot.
There is a family of strategies for maintaining a heap that partially avoids the problems of fragmentation and awkward distribution of empty block sizes. These strategies, called "buddy systems," in practice spend very little time merging adjacent empty blocks. The disadvantage of buddy systems is that blocks come in a limited assortment of sizes, so we may waste some space by placing a data item in a bigger block than necessary.
The central idea behind all buddy systems is that blocks come only in certain sizes; let us say that s1 < s2 < s3 < ???/FONT> < sk are all the sizes in which blocks can be found. Common choices for the sequence sl, s2, . . . are 1, 2, 4, 8, . . . (the exponential buddy system) and 1, 2, 3, 5, 8, 13, . . . (the Fibonacci buddy system, where si+1 = si+si-1). All the empty blocks of size si are linked in a list, and there is an array of available list headers, one for each size si allowed.† If we require a block of size d for a new datum, we choose an available block of that size si such that si ?/FONT> d, but si-1 < d, that is, the smallest permitted size in which the new datum fits.
Difficulties arise when no empty blocks of the desired size
si exist. In
that case, we find a block of size si+1 and split it into two, one of size
si and
the other of size si+1-si.† The buddy system constrains us that
si+1 - si be
some sj, for j ?/FONT> i. We
now see the way in which the choices of values for
the si's are constrained. If we let j = i - k, for some
k ?/FONT> 0, then since
si+1-si = si-
k, it follows that
Equation (12.1) applies when i > k, and together with
values for
s1, s2, . . . , sk, completely
determines sk+1, sk+2, . . . . For
example, if
k = 0, (12.1) becomes
Whatever value of k we choose in (12.1) we get a
kth order buddy system.
For any k, the sequence of permitted sizes grows exponentially; that is, the
ratio si+1/si approximates some constant
greater than one. For example, for
k=0, si+1/si is exactly 2. For
k = 1 the ratio approximates the "golden ratio"
((?/FONT>`5+1)/2 = 1.618), and the
ratio decreases as k increases, but never gets as
low as 1. In the kth order buddy system, each block of size
si+1 may be viewed as
consisting of a block of size si and one of size si-
k. For specificity, let us suppose
that the block of size si is to the left (in lower numbered positions) of the
block of size si-k.‡ If we
view the heap as a single block of size sn, for some
large n, then the positions at which blocks of size si can begin are
completely
determined. The positions in the exponential, or 0th
order, buddy system are easily
determined. Assuming positions in the heap are numbered starting at 0, a
block of size si begins at any position beginning with a multiple of
2i, that is,
0, 2i, . . .. Moreover, each block of size 2i+1, beginning at
say, j2i+1 is
composed of two "buddies" of size 2i, beginning at positions
(2j)2i, which is
j2i+1, and (2j+1)2i. Thus it is easy to find
the buddy of a block of size 2i.
If it begins at some even multiple of 2i, say (2j)2i,
its buddy is to the right, at
position (2j+1)2i. If it begins at an odd multiple of
2i, say (2j+1)2i, its
buddy is to the left, at (2j)2i. Example 12.8. Matters are not so simple for buddy systems of order higher
than 0. Figure 12.15 shows the Fibonacci buddy system used in a heap of size
55, with blocks of sizes s1, s2, . . .,
s8 = 2, 3, 5, 8, 13, 21, 34, and 55. For
example, the block of size 3 beginning at 26 is buddy to the block of size 5
beginning at 21; together they comprise the block of size 8 beginning at 21,
which is buddy to the block of size 5 beginning at 29. Together, they
comprise the block of size 13 starting at 21, and so on.
Fig. 12.15. Division of a heap according to the Fibonacci buddy
system. If we require a block of size n, we choose any one from the available list of
blocks of size si, where si ?/FONT> n and either i = 1 or si-1 <
n; that is, we choose
a best fitting block. In a kth order buddy system, if no blocks of size
si exist,
we may choose a block of size si+1 or
si+k+1 to split, as one of the resulting
blocks will be of size si in either case. If no blocks in either of these sizes
exist, we may create one by applying this splitting strategy recursively for size
si+1. There is a small catch, however. In a
kth order system, we may not split
blocks of size s1, s2, . . .,
sk, since these would result in a block whose size is
smaller than s1. Rather we must use the block whole, if no smaller block is
available. This problem does not come up if k=0, i.e., in the exponential
buddy system. It could be alleviated in the Fibonacci buddy system if we start
with s1 = 1, but that choice may not be acceptable since blocks of size 1 (byte
or word, perhaps) could be too small to hold a pointer and a full/empty bit. When a block becomes available for reuse, we can see one of the advantages
of the buddy system. We can sometimes reduce fragmentation by combining
the newly available block with its buddy, if the buddy is also available.† In
fact, should that be the case, we can combine the resulting block with its
buddy, if that buddy is empty, and so on. The combination of empty buddies
takes only a constant amount of time, and thus is an attractive alternative to
periodic mergers of adjacent empty blocks, suggested in the previous section,
which takes time proportional to the number of empty blocks. The exponential buddy system makes the locating of buddies
especially
easy. If we have just returned the block of size 2i beginning at
p2i, its buddy
is at (p+1)2i if p is even, and at (p-
1)2i if p is odd. For a buddy system of order k ?/FONT> 1, finding buddies is not that simple.
To make it easier, we shall store certain pieces of information in each block. In each pair of buddies, one (the left buddy) is to the left
of the other (the
right buddy). Intuitively, the left buddy count of a block tells how many times
consecutively it is all or part of a left buddy. Formally, the entire heap,
treated as a block of size sn has a left buddy count of 0. When we divide
any
block of size si+1, with left buddy count b, into blocks of size
si and si-k,
which are the left and right buddies respectively, the left buddy gets a left
buddy count of b+1, while the right gets a left buddy count of 0, independent
of b. For example, in Fig. 12.15, the block of size 3 beginning at 0 has a left
buddy count of 6, and the block of size 3 beginning at 13 has a left buddy
count of 2. In addition to the above information, empty blocks, but not
utilized ones,
have forward and backward pointers for the available list of the appropriate
size. The bidirectional pointers make mergers of buddies, which requires
deletion from available lists, easy. The way we use this information is as follows. Suppose k
is the order of
the buddy system. Any block beginning at position p with a left buddy count
of 0 is a right buddy. Thus, if it has size index j, its left buddy is of size
sj+k
and begins at position p - sj+k. If the left buddy count is
greater than 0, then
the block is left buddy to a block of size sj-k, which is located beginning at
position p+sj. If we combine a left buddy of size
si, having a left buddy count of b, with
a right buddy of size si-k, the resulting block has size index
i+1, begins at the
same position as the block of size si, and has a left buddy count b-
1. Thus,
the necessary information can be maintained easily when we merge two empty
buddies. The reader may check that the information can be maintained when
we split an empty block of size si+1 into a used block of size
si and an empty
one of size si-k. If we maintain all this information, and link the available lists in
both
directions, we spend only a constant amount of time on each split of a block
into buddies or merger of buddies into a larger block. Since the number of
mergers can never exceed the number of splits, the total amount of work is
proportional to the number of splits. It is not hard to recognize that most
requests for an allocated block require no splits at all, since a block of the
correct size is already available. However, there are bizarre situations where
each allocation requires many splits. The most extreme example is where we
repeatedly request a block of the smallest size, then return it. If there are n
different sizes, we require at least n/k splits in a kth order
buddy system,
which are then followed by n/k merges when the block is returned. There are times when, even after merging all adjacent empty blocks, we
cannot satisfy a request for a new block. It could be, of course, that there simply
is not the space in the entire heap to provide a block of the desired size. But
more typical is a situation like Fig. 12.11, where although there are 2200 bytes
available, we cannot satisfy a request for a block of more than 1000. The
problem is that the available space is divided among several noncontiguous
blocks. There are two general approaches to this problem. Method (1), using chains of blocks for a datum, tends to be
wasteful of
space. If we choose a small block size, we use a large fraction of space for
"overhead," the pointers needed to maintain chains. If we use large blocks,
we shall have little overhead, but many blocks will be almost wasted, storing a
little datum. The only situation in which this sort of approach is to be
preferred is when the typical data item is very large. For example, many file
systems work this way, dividing the heap, which is typically a disk unit, into
equal-sized blocks, of say 512 to 4096 bytes, depending on the system. As
many files are much longer than these numbers, there is not too much wasted
space, and pointers to the blocks composing a file take relatively little space.
Allocation of space under this discipline is relatively straightforward, given
what has been said in previous sections, and we shall not discuss the matter
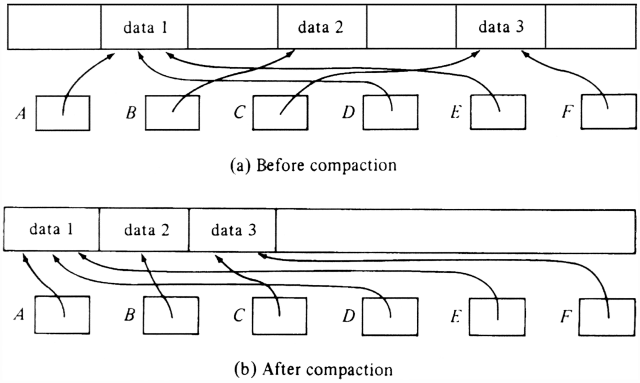
further here. The typical problem we face is to take a collection of blocks in use, as
suggested by Fig. 12.16(a), each of which may be of a different size and pointed
to by more than one pointer, and slide them left until all available space is at
the right end of the heap, as shown in Fig. 12.16(b). The pointers must
continue to point to the same data as before, naturally.
Fig. 12.16. The storage compaction process. There are some simple solutions to this problem if we allocate a
little
extra space in each block, and we shall discuss another, more complicated
method that is efficient, yet requires no extra space in utilized blocks beyond
what is required for any of the storage management schemes we have
discussed, namely a full/empty bit and a count indicating the size of the block. A simple scheme for compacting is first to scan all blocks from
the left,
whether full or empty, and compute a "forwarding address" for each full
block. The forwarding address of a block is its present position minus the sum
of all the empty space to its left, that is, the position to which the block
should be moved eventually. It is easy to calculate forwarding addresses. As
we scan blocks from the left, accumulate the amount of empty space we see
and subtract this amount from the position of each block we see. The
algorithm is sketched in Fig. 12.17. Fig. 12.17. Computation of forwarding addresses. Having computed forwarding addresses, we then look at all
pointers to the
heap.† We follow each pointer to some block B and
replace the pointer by the
forwarding address found in block B. Finally, we move all full blocks to their
forwarding addresses. This process is similar to Fig. 12.17, with line (8)
replaced by
si+1 = si +
si-k (12.1)
si+1 = 2si
(12.2)
Beginning with s1 = 1 in (12.2), we get the exponential sequence 1, 2, 4,
8, . . .. Of course no matter what value of s1 we start with, the s's grow
exponentially in (12.2). As another example, if k=1, s1=1, and
s2=2,
( 12. l ) becomes
si+1 = si +
si-1 (12.3)
(12.3) defines the Fibonacci sequence: 1, 2, 3, 5, 8, 13, . . ..
Distribution of Blocks
Allocating Blocks
Returning Blocks to Available Storage
12.6 Storage Compaction
The Compaction Problem
(1) var
p: integer; { the position of the current block }
gap: integer; { the total amount of empty space seen so far }
begin
(2) p := left end of heap;
(4) gap := 0;
(5) while p ?/FONT> right end of heap do begin
{ let p point to block B }
(6) if B is empty then
(7) gap := gap + count in block B
else { B is full }
(8) forwarding address of B := p - gap;
(9) p := p + count in block B
end
end;
for i := p to p - 1 + count in B do
heap[i - gap] := heap[i];
to move block B left by an amount gap. Note that the movement of full
blocks, which takes time proportional to the amount of the heap in use, will
likely dominate the other costs of the compaction.
F. L. Morris discovered a method for compacting a heap without using space in blocks for forwarding addresses. It does, however, require an endmarker bit associated with each pointer and with each block to indicate the end of a chain of pointers. The essential idea is to create a chain of pointers emanating from a fixed position in each full block and linking all the pointers to that block. For example, we see in Fig. 12.16(a) three pointers, A, D, and E, pointing to the leftmost full block. In Fig. 12.18, we see the desired chain of pointers. A chunk of the data of size equal to that of a pointer has been removed from the block and placed at the end of the chain, where pointer A used to be.
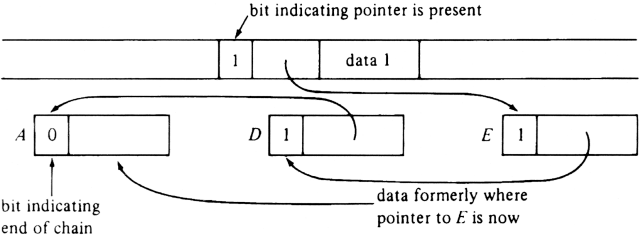
Fig. 12.18. Chaining pointers.
The method for creating such chains of pointers is as follows. We scan all the pointers in any convenient order. Suppose we consider a pointer p to block B. If the endmarker bit in block B is 0, then p is the first pointer found that points to B. We place in p the contents of those positions of B used for the pointer chain, and we make these positions of B point to p. Then we set the endmarker bit in B to 1, indicating it now has a pointer, and we set the endmarker bit in p to 0, indicating the end of the pointer chain and the presence of the displaced data.
Suppose now that when we first consider pointer p to block B the endmarker bit in B is 1. Then B already has the head of a chain of pointers. We copy the pointer in B into p, make B point to p, and set the endmarker bit in p to 1. Thus we effectively insert p at the head of the chain.
Once we have all the pointers to each block linked in a chain emanating from that block, we can move the full blocks far left as possible, just as in the simpler algorithm previously discussed. Lastly, we scan each block in its new position and run down its chain of pointers. Each pointer encountered is made to point to the block in its new position. When we encounter the end of the chain, we restore the data from B, held in the last pointer, to its rightful place in block B and set the endmarker bit in the block to 0.
| 12.1 | Consider the following heap of 1000 bytes, where blank blocks are in use, and the labeled blocks are linked on a free list in alphabetical order. The numbers indicate the first byte in each block. |
|---|

Suppose the following requests are made: Give the free list, in order, after executing the above sequence of steps, assuming free blocks are selected by the strategy of
- allocate a block of 120 bytes
- allocate a block of 70 bytes
- return to the front of the available list the block in bytes 700-849
- allocate a block of 130 bytes.
- first fit
- best fit.
| 12.2 | Consider the following heap in which blank regions are in use and labeled regions are empty. |
|---|

Give sequences of requests that can be satisfied if we use
- first fit but not best fit
- best fit but not first fit.
| 12.3 | Suppose we use an exponential buddy system with sizes 1, 2, 4, 8, and 16 on a heap of size 16. If we request a block of size n, for 1 ?/FONT> n ?/FONT> 16, we must allocate a block of size 2i, where 2i-1 < n ?/FONT> 2i. The unused portion of the block, if any, cannot be used to satisfy any other request. If we need a block of size 2i, i < 4, and no such free block exists, then we first find a block of size 2i+1 and split it into two equal parts. If no block of size 2i+1 exists, we first find and split a free block of size 2i+2, and so on. If we find ourselves looking for a free block of size 32, we fail and cannot satisfy the request. For the purposes of this question, we never combine adjacent free blocks in the heap. |
|---|---|
| There are sequences of requests a1, a2, . . . , an whose sum is less than 16, such that the last request cannot be satisfied. For example, consider the sequence 5, 5, 5. The first request causes the initial block of size 16 to be split into two blocks of size 8 and one of them is used to satisfy the request. The remaining free block of size 8 satisfies the second request, and there is no free space to satisfy the third request. | |
| Find a sequence a1, a2, . . . , an of (not necessarily identical) integers between 1 and 16, whose sum is as small as possible, such that, treated as a sequence of requests for blocks of size a1, a2, . . . , an, the last request cannot be satisfied. Explain why your sequence of requests cannot be satisfied, but any sequence whose sum is smaller can be satisfied. | |
| 12.4 | Consider compacting memory while managing equal-sized blocks. Assume each block consists of a data field and a pointer field, and that we have marked every block currently in use. The blocks are currently located between memory locations a and b. We wish to relocate all active blocks so that they occupy contiguous memory starting at a. In relocating a block remember that the pointer field of any block pointing to the relocated block must be updated. Design an algorithm for compacting the blocks. |
| 12.5 | Consider an array of size n. Design an algorithm to shift all items in the array k places cyclically counterclockwise with only constant additional memory independent of k and n. Hint. Consider what happens if we reverse the first k elements, the last n-k elements, and then finally the entire array. |
| 12.6 | Design an algorithm to replace a substring y of a string xyz by another substring y' using as little additional memory as possible. What is the time and space complexity of your algorithm? |
| 12.7 | Write a program to make a copy of a given list. What is the time and space complexity of your program? |
| 12.8 | Write a program to determine whether two lists are identical. What is the time and space complexity of your program? |
| 12.9 | Implement Morris' heap compaction algorithm of Section 12.6. |
| *12.10 | Design a storage allocation scheme for a situation in which memory is allocated and freed in blocks of lengths one and two. Give bounds on how well your algorithm works. |
Efficient storage management is a central concern in many programming languages, including Snobol [Farber, Griswold, and Polonsky (1964)], Lisp [McCarthy (1965)], APL [Iverson (1962)], and SETL [Schwartz (1973)]. Nicholls [1975] and Pratt [1975] discuss storage management techniques in the context of programming language compilation.
The buddy system of storage allocation was first published by Knowlton [1965]. Fibonacci buddy systems were studied by Hirschberg [1973].
The elegant marking algorithm for use in garbage collection was discovered by Peter Deutsch (Deutsch and Bobrow [1966]) and by Schorr and Waite [1967]. The heap compaction scheme in Section 12.6 is from Morris [1978].
Robson [1971] and Robson [1974] analyzes the amount of memory needed for dynamic storage allocation algorithms. Robson [1977] presents a bounded workspace algorithm for copying cyclic structures. Fletcher and Silver [1966] contains another solution to Exercise 12.5 that uses little additional memory.
† Each programming language must provide for itself a method of representing the current set of variables, and any of the methods discussed in Chapters 4 and 5 is appropriate. For example, most implementations use a hash table to hold the variables.
† This awkwardness is made necessary by peculiarities of Pascal.
† Note that in Fig. 12.1, instead of a count indicating the length of the block, we used the length of the data.
† The reader should, as an exercise, discover how to maintain the pointers when a block is split into two; presumably one piece is used for a new data item, and the other remains empty.
† If c - d is so small that a count and pointer cannot fit, we must use the whole block and delete it from the available list.
† Actually, there is a minimum block size larger than 1, since blocks must hold a pointer, a count and a full/empty bit if they are to be chained to an available list.
† Since empty blocks must hold pointers (and, as we shall see, other information as well) we do not really start the sequence of permitted sizes at 1, but rather at some suitably larger number in the sequence, say 8 bytes.
† Of course, if there are no empty blocks of size si+1, we create one by splitting a block of size si+2, and so on. If no blocks of any larger size exist, we are effectively out of space and must reorganize the heap as in the next section.
‡ Incidentally, it is convenient to think of the blocks of sizes si and si - k making up a block of size si + 1 as "buddies," from whence comes the term "buddy system."
† As in the previous section, we must assume that one bit of each block is reserved to tell whether the block is in use or empty.
† In all that follows we assume the collection of such pointers is available. For example, a typical Snobol implementation stores pairs consisting of a variable name and a pointer to the value for that name in a hash table, with the hash function computed from the name. Scanning the whole hash table allows us to visit all pointers.