| CONTENTS |
In this chapter you learn
C++ offers many choices for storing data in memory. You have choices for how long data remains in memory (storage duration) and choices for which parts of a program have access to data (scope and linkage). The C++ namespace facility provides additional control over access. Larger programs typically consist of several source code files that may share some data in common. Such programs involve the separate compilation of the program files, so this chapter will begin with that topic.
C++, like C, allows and even encourages you to locate the component functions of a program in separate files. As Chapter 1, "Getting Started," describes, you can compile the files separately and then link them into the final executable program. (A C++ compiler typically compiles programs and also manages the linker program.) If you modify just one file, you can recompile just that one file and then link it to the previously compiled versions of the other files. This facility makes it easier to manage large programs. Furthermore, most C++ environments provide additional facilities to help with the management. Unix and Linux systems, for example, have the make program; it keeps track of which files a program depends upon and when they were last modified. If you run make and it detects you've changed one or more source files since the last compilation, make remembers the proper steps needed to reconstitute the program. The Borland C++, Microsoft Visual C++, and Metrowerks CodeWarrior IDEs (integrated development environments) provide similar facilities with their Project menus.
Let's look at a simple example. Instead of looking at compilation details, which depend on the implementation, let's concentrate on more general aspects, such as design.
Suppose, for example, you decide to break up the program in Listing 7.11 by placing the functions in a separate file. That listing, recall, converted rectangular coordinates to polar coordinates and then displayed the result. You can't simply cut the original file on a dotted line after the end of main(). The problem is that main() and the other two functions all use the same structure declarations, so you need to put the declarations in both files. Simply typing them in is an invitation to err. Even if you copy the structure declarations correctly, you have to remember to modify both sets of declarations if you make changes later. In short, spreading a program over multiple files creates new problems.
Who wants more problems? The developers of C and C++ didn't, so they've provided the #include facility to deal with this situation. Instead of placing the structure declarations in each file, you can place them in a header file and then include that header file in each source code file. That way, if you modify the structure declaration, you can do so just once, in the header file. Also, you can place the function prototypes in the header file. Thus, you can divide the original program into three parts:
A header file that contains the structure declarations and prototypes for functions using those structures
A source code file that contains the code for the structure-related functions
A source code file that contains the code that calls upon those functions
This is a useful strategy for organizing a program. If, for example, you write another program that uses those same functions, just include the header file and add the function file to the project or make list. Also, this organization reflects the OOP approach. One file, the header file, contains the definition of the user-defined types. A second file contains the function code for manipulating the user-defined types. Together, they form a package you can use for a variety of programs.
Don't put function definitions or variable declarations into a header file. It might work for a simple setup, but usually it leads to trouble. For example, if you had a function definition in a header file and then included the header file in two other files that are part of a single program, you'd wind up with two definitions of the same function in a single program, which is an error, unless the function is inline. Here are some things commonly found in header files:
Function prototypes
Symbolic constants defined using #define or const
Structure declarations
Class declarations
Template declarations
Inline functions
It's okay to put structure declarations in a header file, for they don't create variables; they just tell the compiler how to create a structure variable when you declare one in a source code file. Similarly, template declarations aren't code to be compiled; they are instructions to the compiler on how to generate function definitions to match function calls found in the source code. Data declared const and inline functions have special linkage properties (coming up soon) that allow them to be placed in header files without causing problems.
Listings 9.1, 9.2, and 9.3 show the result of dividing Listing 7.11 into separate parts. Note that we use "coordin.h" instead of <coordin.h> when including the header file. If the filename is enclosed in angle brackets, the C++ compiler looks at the part of the host system's file system that holds the standard header files. But if the filename is enclosed in double quotation marks, the compiler first looks at the current working directory or at the source code directory (or some such choice, depending upon the compiler). If it doesn't find the header file there, it then looks in the standard location. So use quotation marks, not angle brackets, when including your own header files.
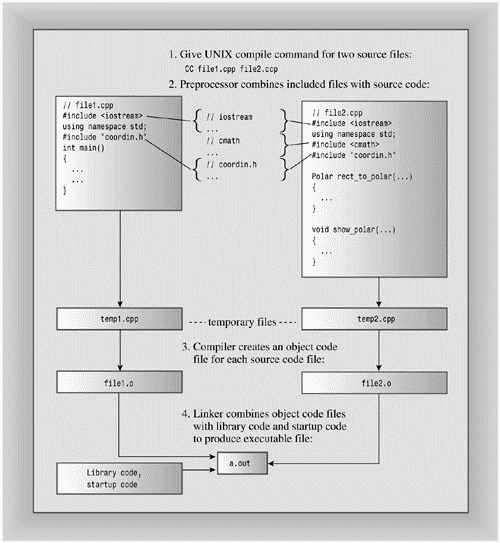
Figure 9.1 outlines the steps for putting this program together on a Unix system. Note that you just give the CC compile command and the other steps follow automatically. The g++ command-line compiler and the Borland C++ command-line compiler (bcc32.exe) also behave that way. Symantec C++, Borland C++, Turbo C++, Metrowerks CodeWarrior, Watcom C++, and Microsoft Visual C++ go through essentially the same steps, but, as outlined in Chapter 1, you initiate the process differently, using menus that let you create a project and associate source code files with it. Note that you only add source code files, not header files to projects. That's because the #include directive manages the header files. Also, don't use #include to include source code files, as that can lead to multiple declarations.
Caution
|
|
In Integrated Development Environments, don't add header files to the project list, and don't use #include to include source code files in other source code files. |
// coordin.h -- structure templates and function prototypes
// structure templates
#ifndef COORDIN_H_
#define COORDIN_H_
struct polar
{
double distance; // distance from origin
double angle; // direction from origin
};
struct rect
{
double x; // horizontal distance from origin
double y; // vertical distance from origin
};
// prototypes
polar rect_to_polar(rect xypos);
void show_polar(polar dapos);
#endif
Header File Management
|
|
You should include a header file just once in a file. That might seem to be an easy thing to remember, but it's possible to include a header file several times without knowing you did so. For example, you might use a header file that includes another header file. There's a standard C/C++ technique for avoiding multiple inclusions of header files. It's based on the preprocessor #ifndef (for if not defined) directive. A code segment like #ifndef COORDIN_H_ ... #endif means process the statements between the #ifndef and #endif only if the name COORDIN_H_ has not been defined previously by the preprocessor #define directive. Normally, you use the #define statement to create symbolic constants, as in the following: #define MAXIMUM 4096 But simply using #define with a name is enough to establish that a name is defined, as in the following: #define COORDIN_H_ The technique, which Listing 9.1 uses, is to wrap the file contents in an #ifndef: #ifndef COORDIN_H_ #define COORDIN_H_ // place include file contents here #endif The first time the compiler encounters the file, the name COORDIN_H_ should be undefined. (We chose a name based on the include filename with a few underscore characters tossed in so as to create a name unlikely to be defined elsewhere.) That being the case, the compiler looks at the material between the #ifndef and the #endif, which is what we want. In the process of looking at the material, the compiler reads the line defining COORDIN_H_. If it then encounters a second inclusion of coordin.h in the same file, the compiler notes that COORDIN_H_ is defined and skips to the line following the #endif. Note that this method doesn't keep the compiler from including a file twice. Instead, it makes it ignore the contents of all but the first inclusion. Most of the standard C and C++ header files use this scheme. |
// file1.cpp -- example of a two-file program
#include <iostream>
#include "coordin.h" // structure templates, function prototypes
using namespace std;
int main()
{
rect rplace;
polar pplace;
cout << "Enter the x and y values: ";
while (cin >> rplace.x >> rplace.y) // slick use of cin
{
pplace = rect_to_polar(rplace);
show_polar(pplace);
cout << "Next two numbers (q to quit): ";
}
cout << "Bye!\n";
return 0;
}
// file2.cpp -- contains functions called in file1.cpp
#include <iostream>
#include <cmath>
#include "coordin.h" // structure templates, function prototypes
using namespace std;
// convert rectangular to polar coordinates
polar rect_to_polar(rect xypos)
{
polar answer;
answer.distance =
sqrt( xypos.x * xypos.x + xypos.y * xypos.y);
answer.angle = atan2(xypos.y, xypos.x);
return answer; // returns a polar structure
}
// show polar coordinates, converting angle to degrees
void show_polar (polar dapos)
{
const double Rad_to_deg = 57.29577951;
cout << "distance = " << dapos.distance;
cout << ", angle = " << dapos.angle * Rad_to_deg;
cout << " degrees\n";
}
By the way, although we've discussed separate compilation in terms of files, the language description uses the term translation unit instead of file in order to preserve greater generality; the file metaphor is not the only possible way to organize information for a computer.
Real World Note: Multiple Library Linking
|
|
The C++ Standard allows each compiler designer the latitude to implement name decoration or mangling (see the Real World Note on name decoration in Chapter 8, "Adventures in Functions") as it sees fit, so you should be aware that binary modules (object-code files) created with different compilers will, most likely, not link properly. That is, the two compilers will generate different decorated names for the same function. This name difference will prevent the linker from matching the function call generated by one compiler with the function definition generated by a second compiler. When attempting to link compiled modules, make sure that each object file or library was generated with the same compiler. If you are provided with the source code, you can usually resolve link errors by recompiling the source with your compiler. |
Now that you've seen a multifile program, it's a good time to extend the discussion of memory schemes in Chapter 4, "Compound Types," for storage categories affect how information can be shared across files. It might have been awhile since you last read Chapter 4, so let's review what it said about memory. C++ uses three separate schemes for storing data, and the schemes differ in how long they preserve data in memory.
Variables declared inside a function definition have automatic storage duration; that includes function parameters. They are created when program execution enters the function or block in which they are defined, and the memory used for them is freed when execution leaves the function or block. C++ has two kinds of automatic storage duration variables.
Variables defined outside of a function definition or else by using the keyword static have static storage duration. They persist for the entire time a program is running. C++ has three kinds of static storage duration variables.
Memory allocated by the new operator persists until freed with the delete operator or until the program ends, whichever comes first. This memory has dynamic storage duration and sometimes is termed the free store.
We get the rest of the story now, including fascinating details about when variables of different types are in scope, or visible (usable by the program), and about linkage, which determines what information is shared across files.
Scope describes how widely visible a name is in a file (translation unit). For example, a variable defined in a function can be used in that function, but not in another, whereas a variable defined in a file above the function definitions can be used in all the functions. Linkage describes how a name can be shared in different units. A name with external linkage can be shared across files, and a name with internal linkage can be shared by functions within a single file. Names of automatic variables have no linkage, for they are not shared.
A C++ variable can have one of several scopes. A variable having local scope (also termed block scope) is known only within the block in which it is defined. A block, remember, is a series of statements enclosed in braces. A function body, for example, is a block, but you can have other blocks nested within the function body. A variable having global scope (also termed file scope) is known throughout the file after the point where it is defined. Automatic variables have local scope, and a static variable can have either scope, depending on how it is defined. Names used in a function prototype scope are known just within the parentheses enclosing the argument list. (That's why it doesn't really matter what they are or if they are even present.) Members declared in a class have class scope (see Chapter 10, "Objects and Classes"). Variables declared in a namespace have namespace scope. (Now that namespaces have been added to the language, the global scope has become a special case of namespace scope.)
C++ functions can have class scope or namespace scope, including global scope, but they can't have local scope. (Because a function can't be defined inside a block, if a function were to have local scope, it could only be known to itself, and hence couldn't be called by another function. Such a function couldn't function.)
The various C++ storage choices are characterized by their storage duration, their scope, and their linkage. Let's look at C++'s storage classes in terms of these properties. We begin by examining the situation before namespaces were added to the mix, and then see how namespaces modify the picture.
Function parameters and variables declared inside a function have, by default, automatic storage duration. They also have local scope and no linkage. That is, if you declare a variable called texas in main() and declare another variable with the same name in a function called oil(), you've created two independent variables, each known only in the function in which it's defined. Anything you do to the texas in oil() has no effect on the texas in main(), and vice versa. Also, each variable is allocated when program execution enters the innermost block containing the definition, and each fades from existence when its function terminates. (Note that the variable is allocated when execution enters the block, but the scope begins only after the point of declaration.)
If you define a variable inside of a block, the variable's persistence and scope are confined to that block. Suppose, for example, you define a variable called teledeli at the beginning of main(). Now suppose you start a new block within main() and define a new variable, called websight in the block. Then, teledeli is visible in both the outer and inner blocks, whereas websight exists only in the inner block and is in scope only from its point of definition until program execution passes the end of the block:
int main()
{
int teledeli = 5;
{ // websight allocated
cout << "Hello\n";
int websight = -2; // websight scope begins
cout << websight << ' ' << teledeli << endl;
} // websight expires
cout << teledeli << endl;
...
}
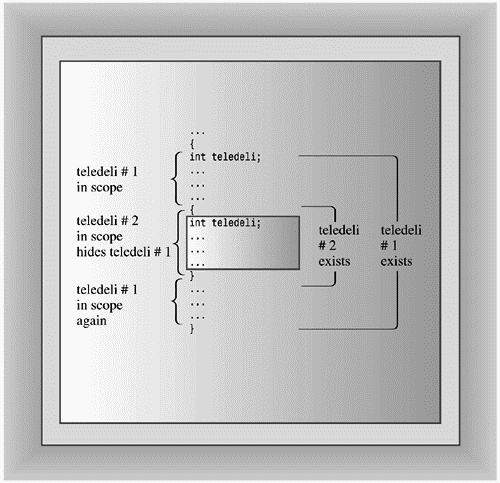
But what if you name the variable in the inner block teledeli instead of websight so that you have two variables of the same name, with one in the outer block and one in the inner block? In this case, the program interprets the teledeli name to mean the local block variable while the program executes statements within the block. We say the new definition hides the prior definition. The new definition is in scope, and the old definition temporarily is out of scope. When the program leaves the block, the original definition comes back into scope. (See Figure 9.2.)
Listing 9.4 illustrates how automatic variables are localized to the function or block that contains them.
// auto.cpp -- illustrating scope of automatic variables
#include <iostream>
using namespace std;
void oil(int x);
int main()
{
// NOTE: some implementations require that you type cast the
// addresses in this program to type unsigned
int texas = 31;
int year = 1999;
cout << "In main(), texas = " << texas << ", &texas =";
cout << &texas << "\n";
cout << "In main(), year = " << year << ", &year =";
cout << &year << "\n";
oil(texas);
cout << "In main(), texas = " << texas << ", &texas =";
cout << &texas << "\n";
cout << "In main(), year = " << year << ", &year =";
cout << &year << "\n";
return 0;
}
void oil(int x)
{
int texas = 5;
cout << "In oil(), texas = " << texas << ", &texas =";
cout << &texas << "\n";
cout << "In oil(), x = " << x << ", &x =";
cout << &x << "\n";
{ // start a block
int texas = 113;
cout << "In block, texas = " << texas;
cout << ", &texas = " << &texas << "\n";
cout << "In block, x = " << x << ", &x =";
cout << &x << "\n";
} // end a block
cout << "Post-block texas = " << texas;
cout << ", &texas = " << &texas << "\n";
}
Here is the output:
In main(), texas = 31, &texas =0x0065fd54 In main(), year = 1999, &year =0x0065fd58 In oil(), texas = 5, &texas =0x0065fd40 In oil(), x = 31, &x =0x0065fd50 In block, texas = 113, &texas = 0x0065fd44 In block, x = 31, &x =0x0065fd50 Post-block texas = 5, &texas = 0x0065fd40 In main(), texas = 31, &texas =0x0065fd54 In main(), year = 1999, &year =0x0065fd58
Notice how each of the three texas variables has its own distinct address and how the program uses only the particular variable in scope at the moment, so assigning the value 113 to the texas in the inner block in oil() has no effect on the other variables of the same name.
Let's summarize the sequence of events. When main() starts, the program allocates space for texas and year, and these variables come into scope. When the program calls oil(), these variables remain in memory but pass out of scope. Two new variables, x and texas, are allocated and come into scope. When program execution reaches the inner block in oil(), the new texas passes out of scope as it is superseded by an even newer definition. The variable x, however, stays in scope because the block doesn't define a new x. When execution exits the block, the memory for the newest texas is freed, and texas number 2 comes back into scope. When the oil() function terminates, that texas and x expire, and the original texas and year come back into scope.
Incidentally, you can use the C++ (and C) keyword auto to indicate the storage class explicitly:
int froob(int n)
{
auto float ford;
...
}
Because you can use the auto keyword only with variables that already are automatic by default, programmers rarely bother using it. Occasionally, it's used to clarify code to the reader. For example, you can use it to indicate that you purposely are creating an automatic variable that overrides a global definition, such as those we discuss shortly.
You can initialize an automatic variable with any expression whose value will be known when the declaration is reached:
int w; // value of w is indeterminate int x = 5; // initialized with a constant expression int y = 2 * x; // use previously determined value of x cin >> w; int z = 3 * w; // use new value of w
You might gain a better understanding of automatic variables by seeing how a typical C++ compiler implements them. Because the number of automatic variables grows and shrinks as functions start and terminate, the program has to manage automatic variables as it runs. The usual means is to set aside a section of memory and treat it as a stack for managing the flow and ebb of variables. It's called a stack because new data figuratively is stacked atop old data (that is, at an adjacent location, not at the same location) and then removed from the stack when a program is finished with it. The default size of the stack depends on the implementation, but a compiler generally provides the option of changing the size. The program keeps track of the stack by using two pointers. One points to the base of the stack, where the memory set aside for the stack begins, and one points to the top of the stack, which is the next free memory location. When a function is called, its automatic variables are added to the stack, and the pointer to the top points to the next available free space following the variables. When the function terminates, the top pointer is reset to the value it had before the function was called, effectively freeing the memory that had been used for the new variables.
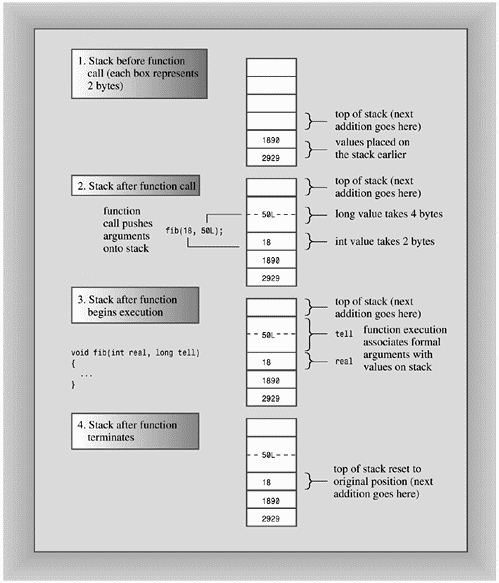
A stack is a LIFO (last-in, first-out) design, meaning the last variables added to the stack are the first to go. The design simplifies argument passing. The function call places the values of its arguments on top of the stack and resets the top pointer. The called function uses the description of its formal parameters to determine the addresses of each argument. Figure 9.3, for example, shows a fib() function that, when called, passes a 2-byte int and a 4-byte long. These values go on the stack. When fib() begins execution, it associates the names real and tell with the two values. When fib() terminates, the top-of-stack pointer is relocated to its former position. The new values aren't erased, but they no longer are labeled, and the space they occupy will be used by the next process that places values on the stack. (The figure is somewhat simplified, for function calls may pass additional information, such as a return address.)
C++, like C, supports the register keyword for declaring local variables. A register variable is another form of automatic variable, so it has automatic storage duration, local scope, and no linkage. The register keyword is a hint to the compiler that you want it to provide fast access to the variable, perhaps by using a CPU register instead of the stack to handle a particular variable. The idea is that the CPU can access a value in one of its registers more rapidly than it can access memory in the stack. To declare a register variable, preface the type with the keyword register:
register int count_fast; // request for a register variable
You've probably noticed the qualifying words "hint" and "request." The compiler doesn't have to honor the request. For example, the registers may already be occupied, or you might request a type that doesn't fit in a register. Many programmers feel that modern compilers are often smart enough not to need the hint. If you write a for loop, for example, the compiler might take it upon itself to use a register for the loop index.
If a variable is stored in a register, it doesn't have a memory address; therefore you can't apply the address operator to a register variable:
void gromb(int *); ... int x; register int y; gromb(&x); // ok gromb(&y); // not allowed
Using register in the declaration is enough to invoke this restriction, even if the compiler doesn't actually use a register for the variable.
In short, an ordinary local variable, a local variable declared using auto, and a local variable declared using register all have automatic storage duration, local scope, and no linkage.
short waffles; // auto variable by default auto short pancakes; // explicitly auto register int muffins; // register variable
Declaring a local variable without a specifier is the same as declaring it with auto, and such a variable is typically handled by being placed on a memory stack. Using the register specifier is a hint that the variable will be heavily used, and the compiler may choose to use something other than the memory stack to hold it; for example, a CPU register.
C++, like C, provides static storage duration variables with three kinds of linkage: external linkage, internal linkage, and no linkage. All three last for the duration of the program; they are less ephemeral than automatic variables. Because the number of static variables doesn't change as the program runs, the program doesn't need a special device like a stack to manage them. Instead, the compiler allocates a fixed block of memory to hold all the static variables, and those variables stay present as long as the program executes. Also, if you don't explicitly initialize a static variable, the compiler sets it to zero. Static arrays and structures have all the bits of each element or member set to zero by default.
Compatibility Note
|
|
Classic K&R C did not allow you to initialize automatic arrays and structures, but it did allow you to initialize static arrays and structures. ANSI C and C++ allow you to initialize both kinds. But some older C++ translators use C compilers that are not fully ANSI C-compliant. If you are using such an implementation, you might need to use one of the three varieties of static storage classes for initializing arrays and structures. |
Let's see how to create the three different kinds of static duration variables; then we can go on to examine their properties. To create a static duration variable with external linkage, declare it outside of any block. To create a static duration variable with internal linkage, declare it outside of any block and use the static storage class modifier. To create a static duration variable with no linkage, declare it inside a block using the static modifier. The following code fragment shows these three variations:
...
int global = 1000; // static duration, external linkage
static int one_file = 50; // static duration, internal linkage
int main()
{
...
}
void funct1(int n)
{
static int count = 0; // static duration, no linkage
int llama = 0;
...
}
void funct2(int q)
{
...
}
As already stated, all the static duration variables (global, one_file, and count) persist from the time the program begins execution until it terminates. The variable count, which is declared inside of funct1(), has local scope and no linkage, which means it can be used only inside the funct1() function, just like the automatic variable llama. But, unlike llama, count remains in memory even when the funct1() function is not being executed. Both global and one_file have file scope, meaning they can be used from the point of declaration until the end of the file. In particular, both can be used in main(), funct1(), and funct2(). Because one_file has internal linkage, it can be used only in the file containing this code. Because global has external linkage, it also can be used in other files that are part of the program.
All static duration variables share the following two initialization features:
An uninitialized static variable has all its bits set to 0.
A static variable can be initialized only with a constant expression.
A constant expression can use literal constants, const and enum constants, and the sizeof operator. The following code fragment illustrates these points:
int x; // x set to 0
int y = 49; // 49 is a constant expression
int z = 2 * sizeof(int) + 1; // also a constant expression
int m = 2 * z; // invalid, z not a constant
int main() {...}
Table 9.1 summarizes the storage class features as used in the pre-namespace era. Next, let's examine the static duration varieties in more detail.
| Storage Description | Duration | Scope | Linkage | How Declared |
|---|---|---|---|---|
| automatic | automatic | block | none | in a block (optionally with the keyword auto) |
| register | automatic | block | none | in a block with the keyword register |
| static with no linkage | static | block | none | in a block with the keyword static |
| static with external linkage | static | file | external | outside of all functions |
| static with internal linkage | static | file | internal | outside of all functions with the keyword static |
Variables with external linkage often are simply called external variables. They necessarily have static storage duration and file scope. External variables are defined outside of, and hence external to, any function. For example, they could be declared above the main() function. You can use an external variable in any function that follows the external variable's definition in the file. Thus, external variables also are termed global variables in contrast to automatic variables, which are local variables. However, if you define an automatic variable having the same name as an external variable, the automatic variable is the one in scope when the program executes that particular function. Listing 9.5 illustrates these points. It also shows how you can use the keyword extern to redeclare an external variable defined earlier and how you can use C++'s scope resolution operator to access an otherwise hidden external variable. Because the example is a one-file program, it doesn't illustrate the external linkage property; a later example will do that.
// external.cpp -- external variables
#include <iostream>
using namespace std;
// external variable
double warming = 0.3;
// function prototypes
void update(double dt);
void local();
int main() // uses global variable
{
cout << "Global warming is " << warming << " degrees.\n";
update(0.1); // call function to change warming
cout << "Global warming is " << warming << " degrees.\n";
local(); // call function with local warming
cout << "Global warming is " << warming << " degrees.\n";
return 0;
}
void update(double dt) // modifies global variable
{
extern double warming; // optional redeclaration
warming += dt;
cout << "Updating global warming to " << warming;
cout << " degrees.\n";
}
void local() // uses local variable
{
double warming = 0.8; // new variable hides external one
cout << "Local warming = " << warming << " degrees.\n";
// Access global variable with the
// scope resolution operator
cout << "But global warming = " << ::warming;
cout << " degrees.\n";
}
Here is the output:
Global warming is 0.3 degrees. Updating global warming to 0.4 degrees. Global warming is 0.4 degrees. Local warming = 0.8 degrees. But global warming = 0.4 degrees. Global warming is 0.4 degrees.
The program output illustrates that both main() and update() can access the external variable warming. Note that the change that update() makes to warming shows up in subsequent uses of the variable.
The update() function redeclares the warming variable by using the keyword extern. This keyword means "use the variable by this name previously defined externally." Because that is what update() would do anyway if you omitted the entire declaration, this declaration is optional. It serves to document that the function is designed to use the external variable. The original declaration
double warming = 0.3;
is called a defining declaration, or, simply, a definition. It causes storage for the variable to be allocated. The redeclaration
extern double warming;
is called a referencing declaration , or, simply, a declaration. It does not cause storage to be allocated, for it refers to an existing variable. You can use the extern keyword only in declarations referring to variables defined elsewhere (or functions梞ore on that later). Also, you cannot initialize a variable in a referencing declaration:
extern double warming = 0.5; // INVALID
You can initialize a variable in a declaration only if the declaration allocates the variable, that is, only in a defining declaration. After all, the term initialization means assigning a value to a memory location when that location is allocated.
The local() function demonstrates that when you define a local variable having the same name as a global variable, the local version hides the global version. The local() function, for example, uses the local definition of warming when it displays warming's value.
C++ takes a step beyond C by offering the scope resolution operator (::). When prefixed to the name of a variable, this operator means to use the global version of that variable. Thus, local() displays warming as 0.8, but it displays ::warming as 0.4. You'll encounter this operator again in namespaces and classes.
Global or Local?
|
|
Now that you have a choice of using global or local variables, which should you use? At first, global variables have a seductive appeal梑ecause all functions have access to a global variable, you don't have to bother passing arguments. But this easy access has a heavy price梪nreliable programs. Computing experience has shown that the better job your program does of isolating data from unnecessary access, the better job the program does in preserving the integrity of the data. Most often, you should use local variables and pass data to functions on a need-to-know basis rather than make data available indiscriminately with global variables. As you will see, OOP takes this data isolation a step further. Global variables do have their uses, however. For example, you might have a block of data that's to be used by several functions, such as an array of month names or the atomic weights of the elements. The external storage class is particularly suited to representing constant data, for then you can use the keyword const to protect the data from change. const char * const months[12] =
{
"January", "February", "March", "April", "May",
"June", "July", "August", "September", "October",
"November", "December"
};
The first const protects the strings from change, and the second const makes sure that each pointer in the array remains pointing to the same string to which it pointed initially. |
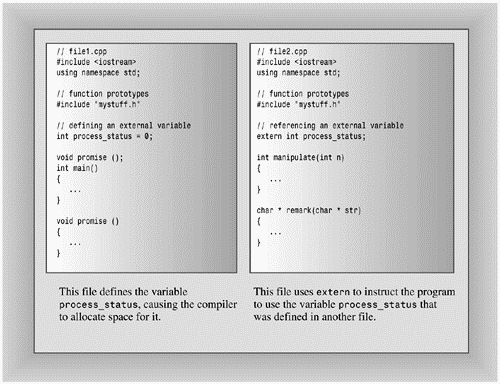
Applying the static modifier to file-scope variable gives it internal linkage. The difference between internal linkage and external linkage becomes meaningful in multifile programs. In that context, a variable with internal linkage is local to the file containing it. But a regular external variable has external linkage, meaning it can be used in different files. For external linkage, one and only one file can contain the external definition for the variable. Other files that want to use that variable must use the keyword extern in a reference declaration. (See Figure 9.4.)
If a file doesn't provide the extern declaration of a variable, it can't use an external variable defined elsewhere:
// file1
int errors = 20; // global declaration
...
---------------------------------------------
// file 2
... // missing an extern int errors declaration
void froobish()
{
cout << errors; // doomed attempt to use errors
..
If a file attempts to define a second external variable by the same name, that's an error:
// file1
int errors = 20; // external declaration
...
---------------------------------------------
// file 2
int errors; // invalid declaration
void froobish()
{
cout << errors; // doomed attempt to use errors
..
The correct approach is to use the keyword extern in the second file:
// file1
int errors = 20; // external declaration
...
---------------------------------------------
// file 2
extern int errors; // refers to errors from file1
void froobish()
{
cout << errors; // uses errors defined in file1
..
But if a file declares a static external variable having the same name as an ordinary external variable declared in another file, the static version is the one in scope for that file:
// file1
int errors = 20; // external declaration
...
---------------------------------------------
// file2
static int errors = 5; // known to file2 only
void froobish()
{
cout << errors; // uses errors defined in file2
...
Remember
|
|
In a multifile program, you can define an external variable in one and only one file. All other files using that variable have to declare that variable with the extern keyword. |
Use an external variable to share data among different parts of a multifile program. Use a static variable with internal linkage to share data among functions found in just one file. (Name spaces offer an alternative method for this, and the standard indicates that using static to create internal linkage will be phased out in the future.) Also, if you make a file-scope variable static, you needn't worry about its name conflicting with file-scope variables found in other files.
Listings 9.6 and 9.7 show how C++ handles variables with external and internal linkage. Listing 9.6 (twofile1.cpp) defines the external variables tom and dick and the static external variable harry. The main() function in that file displays the addresses of the three variables and then calls the remote_access() function, which is defined in a second file. Listing 9.7 (twofile2.cpp) shows that file. In addition to defining remote_access(), the file uses the extern keyword to share tom with the first file. Next, the file defines a static variable called dick. The static modifier makes this variable local to the file and overrides the global definition. Then, the file defines an external variable called harry. It can do so without conflicting with the harry of the first file because the first harry has internal linkage only. Then, the remote_access() function displays the addresses of these three variables so that you can compare them with the addresses of the corresponding variables in the first file. Remember to compile both files and link them to get the complete program.
// twofile1.cpp -- variables with external and internal linkage
#include <iostream> // to be compiled with two file2.cpp
using namespace std;
int tom = 3; // external variable definition
int dick = 30; // external variable definition
static int harry = 300; // static, internal linkage
// function prototype
void remote_access();
int main()
{
cout << "main() reports the following addresses:\n";
cout << &tom << " = &tom, " << &dick << " = &dick, ";
cout << &harry << " = &harry\n";
remote_access();
return 0;
}
// twofile2.cpp -- variables with internal and external linkage
#include <iostream>
using namespace std;
extern int tom; // tom defined elsewhere
static int dick = 10; // overrides external dick
int harry = 200; // external variable definition,
// no conflict with twofile1 harry
void remote_access()
{
cout << "remote_access() reports the following addresses:\n";
cout << &tom << " = &tom, " << &dick << " = &dick, ";
cout << &harry << " = &harry\n";
}
Here is the output:
main() reports the following addresses: 0x0041a020 = &tom, 0x0041a024 = &dick, 0x0041a028 = &harry remote_access() reports the following addresses: 0x0041a020 = &tom, 0x0041a450 = &dick, 0x0041a454 = &harry
As you can see, both files use the same tom variable but different dick and harry variables.
So far, we've looked at a file-scope variable with external linkage and a file-scope variable with internal linkage. Now let's look at the third member of the static duration family, a local variable with no linkage. Such a variable is created by applying the static modifier to a variable defined inside a block. When you use it inside a block, static makes a local variable have static storage duration. That means that even though the variable is known within that block, it exists even while the block is inactive. Thus, a static local variable can preserve its value between function calls. (Static variables would be useful for reincarnation梱ou could use them to pass secret account numbers for a Swiss bank to your next appearance.) Also, if you initialize a static local variable, the program initializes the variable once, when the program starts up. Subsequent calls to the function don't reinitialize the variable the way they do for automatic variables. Listing 9.8 illustrates these points.
Incidentally, the program shows one way to deal with line input that may exceed the size of the destination array. The cin.get(input,ArSize) input method, recall, reads up to the end of the line or up to ArSize - 1 characters, whichever comes first. It leaves the newline character in the input queue. This program reads the character that follows the line input. If it is a newline character, then the whole line was read. If it isn't a newline character, there are more characters left on the line. This program then uses a loop to reject the rest of the line, but you can modify the code to use the rest of the line for the next input cycle. The program also uses the fact that attempting to read an empty line with get(char *, int) causes cin to test as false.
// static.cpp -- using a static local variable
#include <iostream>
using namespace std;
// constants
const int ArSize = 10;
// function prototype
void strcount(const char * str);
int main()
{
char input[ArSize];
char next;
cout << "Enter a line:\n";
cin.get(input, ArSize);
while (cin)
{
cin.get(next);
while (next != '\n') // string didn't fit!
cin.get(next);
strcount(input);
cout << "Enter next line (empty line to quit):\n";
cin.get(input, ArSize);
}
cout << "Bye\n";
return 0;
}
void strcount(const char * str)
{
static int total = 0; // static local variable
int count = 0; // automatic local variable
cout << "\"" << str <<"\" contains ";
while (*str++) // go to end of string
count++;
total += count;
cout << count << " characters\n";
cout << total << " characters total\n";
}
Compatibility Note
|
|
Some older compilers don't implement the requirement that when cin.get(char *,int) reads an empty line, it sets the failbit error flag, causing cin to test as false. In that case, you can replace the test while (cin) with this: while (input[0]) Or, for a test that works for both old and new implementations, do this: while (cin && input[0]) |
Here is the program's output:
Enter a line: nice pants "nice pant" contains 9 characters 9 characters total Enter next line (empty line to quit): thanks "thanks" contains 6 characters 15 characters total Enter next line (empty line to quit): parting is such sweet sorrow "parting i" contains 9 characters 24 characters total Enter next line (empty line to quit): ok "ok" contains 2 characters 26 characters total Enter next line (empty line to quit): Bye
Note that because the array size is 10, the program does not read more than 9 characters per line. Also note that the automatic variable count is reset to 0 each time the function is called. However, the static variable total is set to 0 once, at the beginning. After that, total retains its value between function calls, so it's able to maintain a running total.
Certain C++ keywords, called storage class specifiers and cv-qualifiers, provide additional information about storage. Here's a list of the storage class specifiers:
auto register static extern mutable
You've already seen most of these, and you can use no more than one of them in a single declaration. To review, the keyword auto can be used in a declaration to document that variable is an automatic variable. The keyword register is used in a declaration to indicate the register storage class. The keyword static, when used with a file-scope declaration, indicates internal linkage. When used with a local declaration, it indicates static storage duration for a local variable. The keyword extern indicates a reference declaration, that is, that the declaration refers to a variable defined elsewhere. The keyword mutable is explained in terms of const, so let's look at the cv-qualifiers first before returning to mutable.
Here are the cv-qualifiers:
const volatile
The most commonly used is const, and you've already seen its purpose. It indicates that memory, once initialized, should not be altered by a program. We come back to const in a moment.
The volatile keyword indicates that the value in a memory location can be altered even though nothing in the program code modifies the contents. This is less mysterious than it sounds. For example, you could have a pointer to a hardware location that contains the time or information from a serial port. Here the hardware, not the program, changes the contents. Or two programs may interact, sharing data. The intent of this keyword is to improve the optimization abilities of compilers. For example, suppose the compiler notices that a program uses the value of a particular variable twice within a few statements. Rather than have the program look up the value twice, the compiler might cache the value in a register. This optimization assumes that the value of the variable doesn't change between the two uses. If you don't declare a variable to be volatile, then the compiler can feel free to make this optimization. If you do declare the variable to be volatile, you're telling the compiler not to make that sort of optimization.
Now let's return to mutable. You can use it to indicate that a particular member of a structure (or class) can be altered even if a particular structure (or class) variable is a const. For example, consider the following code:
struct data
{
char name[30];
mutable int accesses;
...
};
const data veep = {"Claybourne Clodde", 0, ...};
strcpy(veep.name, "Joye Joux"); // not allowed
veep.accesses++; // allowed
The const qualifier to veep prevents a program from changing veep's members, but the mutable specifier to the accesses member shields accesses from that restriction.
This book won't be using volatile or mutable, but there is more to learn about const.
In C++ (but not C), the const modifier alters the default storage classes slightly. Whereas a global variable has external linkage by default, a const global variable has internal linkage by default. That is, C++ treats a global const definition as if the static specifier had been used.
const int fingers = 10; // same as static const int fingers;
int main(void)
{
...
C++ altered the rules for constant types to make life easier for you. Suppose, for example, you have a set of constants that you'd like to place in a header file and that you use this header file in several files in the same program. After the preprocessor includes the header file contents in each source file, each source file will contain definitions like this:
const int fingers = 10; const char * warning = "Wak!";
If global const declarations had external linkage like regular variables, this would be an error, for you can define a global variable in one file only. That is, only one file can contain the preceding declaration, whereas the other files have to provide reference declarations using the extern keyword. Moreover, only the declarations without the extern keyword can initialize values:
// extern would be required if const had external linkage extern const int fingers; // can't be initialized extern const char * warning;
So, you need one set of definitions for one file and a different set of declarations for the other files. But, because externally defined const data have internal linkage, you can use the same declarations in all files.
Internal linkage also means that each file gets its own set of constants rather than sharing them. Each definition is private to the file containing it. This is why it's a good idea to put constant definitions in a header file. That way, as long as you include the same header file in two source code files, they receive the same set of constants.
If, for some reason, you want to make a constant have external linkage, you can use the extern keyword to override the default internal linkage:
extern const int states = 50; // external linkage
You must use the extern keyword to declare the constant in all files using the constant. This differs from regular external variables, in which you don't use the keyword extern when you define a variable, but use extern in other files using that variable. Also, unlike regular variables, you can initialize an extern const value. Indeed, you have to, for const data requires initialization.
When you declare a const within a function or block, it has block scope, meaning the constant is usable only when the program is executing code within the block. This means that you can create constants within a function or block and not have to worry about the name conflicting with constants defined elsewhere.
Functions, too, have linkage propertieslinllinl, although the selection is more limited than for variables. C++, like C, does not allow you to define one function inside another, so all functions automatically have a static storage duration, meaning they are all present as long as the program is running. By default, functions have external linkage, meaning they can be shared across files. You can, in fact, use the keyword extern in a function prototype to indicate the function is defined in another file, but that is optional. (For the program to find the function in another file, that file must be one of the files being compiled as part of the program or a library file searched by the linker.) You also can use the keyword static to give a function internal linkage, confining its use to a single file. You would apply this keyword to the prototype and to the function definition:
static int private(double x);
...
static int private(double x)
{
...
}
That means the function is known only in that file. It also means you can use the same name for another function in a different file. As with variables, a static function overrides an external definition for the file containing the static declaration, so a file containing a static function definition will use that version of the function even if there is an external definition of a function with the same name.
C++ has a "one definition rule" that states that every program shall contain exactly one definition of every non-inline function. For functions with external linkage, this means that only one file of a multifile program can contain the function definition. However, each file that uses the function should have the function prototype.
Inline functions are excepted from this rule to allow you to place inline function definitions in a header file. Thus, each file that includes the header file ends up having the inline function definition. However, C++ does require that all the inline definitions for a particular function be identical.
Where C++ Finds Functions
|
|
Suppose you call a function in a particular file in a program. Where does C++ look for the function definition? If the function prototype in that file indicates that function is static, the compiler looks only in that file for the function. Otherwise, the compiler (including the linker, too) looks in all the program files. If it finds two definitions, the compiler sends you an error message, for you can have only one definition for an external function. If it fails to find any definition in your files, the function then searches the libraries. This implies that if you define a function having the same name as a library function, the compiler uses your version rather than the library version. (However, C++ reserves the names of the standard library functions, meaning you shouldn't reuse them.) Some compiler-linkers need explicit instructions to identify which libraries to search. |
There is another form of linking, called language linking, that affects functions. First, a little background. A linker needs a different symbolic name for each distinct function. In C, this was simple to implement because there could only be one C function by a given name. So, for internal purposes, a C compiler might translate a C function name such as spiff to _spiff.
The C approach is termed C language linkage. C++, however, can have several functions with the same C++ name that have to be translated to separate symbolic names. Thus, the C++ compiler indulged in the process of name mangling or name decoration (as discussed in Chapter 8) to generate different symbolic names for overloaded functions. For example, it could convert spiff(int) to, say, _spiff_i, and spiff(double, double) to _spiff_d_d. The C++ approach is C++ language linkage.
When the linker looks for a function to match a C++ function call, it uses a different look-up method than it does to match a C function call. But suppose you want to use a precompiled function from a C library in a C++ program? For example, suppose you have this code:
spiff(22); // want spiff(int) from a C library
Its symbolic name in the C library file is _spiff, but, for our hypothetical linker, the C++ look-up convention is to look for the symbolic name _spiff_i. To get around this problem, you can use the function prototype to indicate which protocol to use:
extern "C" void spiff(int); // use C protocol for name look-up extern void spoff(int); // use C++ protocol for name look-up extern "C++" void spaff(int); // use C++ protocol for name look-up
The first uses C language linkage. The second and third use C++ language linkage. The second does so by default, and the third explicitly.
You've seen the five schemes C++ uses to allocate memory for variables (including arrays and structures). They don't apply to memory allocated by using the C++ new operator (or by the older C malloc() function). We call that kind of memory dynamic memory. As you saw in Chapter 4, dynamic memory is controlled by the new and delete operators, not by scope and linkage rules. Thus, dynamic memory can be allocated from one function and freed from another function. Unlike automatic memory, dynamic memory is not LIFO; the order of allocation and freeing depends upon when and how new and delete are used. Typically, the compiler uses three separate memory chunks: one for static variables (this chunk might be subdivided), one for automatic variables, and one for dynamic storage.
Although the storage scheme concepts don't apply to dynamic memory, they do apply to pointer variables used to keep track of dynamic memory. For example, suppose you have the following statement inside a function:
float * p_fees = new float [20];
The 80 bytes (assuming a float is four bytes) of memory allocated by new remains in memory until the delete operator frees it. But the p_fees pointer passes from existence when the function containing this declaration terminates. If you want to have the 80 bytes of allocated memory available to another function, you need to pass or return its address to that function. On the other hand, if you declare p_fees with external linkage, then the p_fees pointer will be available to all the functions following that declaration in the file. And by using
extern float * p_fees;
in a second file, you make that same pointer available in the second file. Note, however, that a statement using new to set p_fees has to be in a function because static storage variables can only be initialized with constant expressions:
float * p_fees; // = new float[20] not allowed here
int main()
{
p_fees = new float [20];
...
Compatibility Note
|
|
Memory allocated by new typically is freed when the program terminates. However, this is not always true. Under DOS, for example, in some circumstances a request for a large block of memory can result in a block that is not deleted automatically when the program terminates. |
Names in C++ can refer to variables, functions, structures, enumerations, classes, and class and structure members. When programming projects grow large, the potential for name conflicts increases. When you use class libraries from more than one source, you can get name conflicts. For example, two libraries might both define classes named List, Tree, and Node, but in incompatible ways. You might want the List class from one library and the Tree from the other, and each might expect its own version of Node. Such conflicts are termed namespace problems.
The C++ Standard provides namespace facilities to provide greater control over the scope of names. It has taken a while for compilers to incorporate namespaces, but, by now, support has become common.
Before looking at the new facilities, let's review the namespace properties that already exist in C++ and introduce some terminology. This can help make the idea of namespaces seem more familiar.
The first term is declarative region. A declarative region is a region in which declarations can be made. For example, you can declare a global variable outside of any function. The declarative region for that variable is the file in which it is declared. If you declare a variable inside a function, its declarative region is the innermost block in which it is declared.
The second term is potential scope. The potential scope for a variable begins at its point of declaration and extends to the end of its declarative region. So the potential scope is more limited than the declarative region because you can't use a variable above the point it is first defined.
A variable, however, might not be visible everywhere in its potential scope. For example, it can be hidden by another variable of the same name declared in a nested declarative region. For example, a local variable declared in a function (the declarative region is the function) hides a global variable declared in the same file (the declarative region is the file). The portion of the program that actually can see the variable is termed the scope, which is the way we've been using the term all along. Figures 9.5 and 9.6 illustrate the terms declarative region, potential scope, and scope.
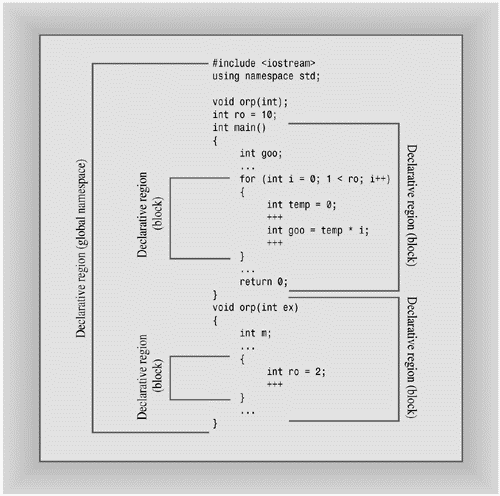
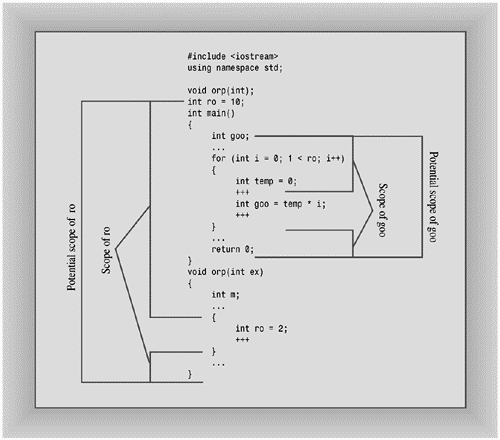
C++'s rules about global and local variables define a kind of namespace hierarchy. Each declarative region can declare names that are independent of names declared in other declarative regions. A local variable declared in one function doesn't conflict with a local variable declared in a second function.
What C++ now adds is the ability to create named namespaces by defining a new kind of declarative region, one whose main purpose is to provide an area in which to declare names. The names in one namespace don't conflict with the same names declared in other namespaces, and there are mechanisms for letting other parts of a program use items declared in a namespace. The following code, for example, uses the new keyword namespace to create two namespaces, Jack and Jill.
namespace Jack {
double pail;
void fetch();
int pal;
struct Well { ... };
}
namespace Jill {
double bucket(double n) { ... }
double fetch;
int pal;
struct Hill { ... };
}
Namespaces can be located at the global level or inside other namespaces, but they cannot be placed in a block. Thus, a name declared in a namespace has external linkage by default (unless it refers to a constant).
In addition to user-defined namespaces, there is one more namespace, the global namespace. This corresponds to the file-level declarative region, so what used to be termed global variables are now described as being part of the global namespace.
The names in any one namespace can't conflict with names in another namespace. Thus, the fetch in Jack can coexist with the fetch in Jill, and the Hill in Jill can coexist with an external Hill. The rules governing declarations and definitions in a namespace are the same as the rules for global declarations and definitions.
Namespaces are open, meaning you can add names to existing namespaces. For example, the statement
namespace Jill {
char * goose(const char *);
}
adds the name goose to the existing list of names in Jill.
Similarly, the original Jack namespace provided a prototype for a fetch() function. You can provide the code for the function later in the file (or in another file) by using the Jack namespace again:
namespace Jack {
void fetch()
{
...
}
}
Of course, you need a way to access names in a given namespace. The simplest way is to use ::, the scope resolution operator, to qualify a name with its namespace:
Jack::pail = 12.34; // use a variable Jill::Hill mole; // create a type Hill structure Jack::fetch(); // use a function
An unadorned name, such as pail, is termed the unqualified name, whereas a name with the namespace, as in Jack::pail, is termed a qualified name.
Having to qualify names every time they are used is not an appealing prospect, so C++ provides two mechanisms梩he using-declaration and the using-directive梩o simplify using namespace names. The using-declaration lets you make particular identifiers available, and the using-directive makes the entire namespace accessible.
The using-declaration consists of preceding a qualified name with the new keyword using:
using Jill::fetch; // a using-declaration
A using-declaration adds a particular name to the declarative region in which it occurs. For example, a using-declaration of Jill::fetch in main() adds fetch to the declarative region defined by main(). After making this declaration, you can use the name fetch instead of Jill::fetch.
namespace Jill {
double bucket(double n) { ... }
double fetch;
struct Hill { ... };
}
char fetch;
int main()
{
using Jill::fetch; // put fetch into local namespace
double fetch; // Error! Already have a local fetch
cin >> fetch; // read a value into Jill::fetch
cin >> ::fetch; // read a value into global fetch
...
}
Because a using-declaration adds the name to the local declarative region, this example precludes creating another local variable by the name of fetch. Also, like any other local variable, fetch would override a global variable by the same name.
Placing a using-declaration at the external level adds the name to the global namespace:
void other();
namespace Jill {
double bucket(double n) { ... }
double fetch;
struct Hill { ... };
}
using Jill::fetch; // put fetch into global namespace
int main()
{
cin >> fetch; // read a value into Jill::fetch
other()
...
}
void other()
{
cout << fetch; // display Jill::fetch
...
}
A using-declaration, then, makes a single name available. In contrast, the using-directive makes all the names available. A using-directive consists of preceding a namespace name with the keywords using namespace, and it makes all the names in the namespace available without using the scope resolution operator:
using namespace Jack; // make all the names in Jack available
Placing a using-directive at the global level makes the namespace names available globally. You've seen this in action many a time:
#include <iostream> // places names in namespace std using namespace std; // make names available globally
Placing a using-directive in a particular function makes the names available just in that function.
int vorn(int m)
{
using namespace jack; // make names available in vorn()
...
}
Using a using-directive to import all the names wholesale is not the same as using multiple using-declarations. It's more like the mass application of a scope resolution operator. When you use a using-declaration, it is as if the name is declared at the location of the using- declaration. If a particular name already is declared in a function, you can't import the same name with a using-declaration. When you use a using-directive, however, name resolution takes place as if you declared the names in the smallest declarative region containing both the using-declaration and the namespace itself. For the following example, that would be the global namespace. If you use a using-directive to import a name that already is declared in a function, the local name will hide the namespace name, just as it would hide a global variable of the same name. However, you still can use the scope resolution operator:
namespace Jill {
double bucket(double n) { ... }
double fetch;
struct Hill { ... };
}
char fetch; // global namespace
int main()
{
using namespace Jill; // import all namespace names
Hill Thrill; // create a type Jill::Hill structure
double water = bucket(2); // use Jill::bucket();
double fetch; // not an error; hides Jill::fetch
cin >> fetch; // read a value into the local fetch
cin >> ::fetch; // read a value into global fetch
cin >> Jill::fetch; // read a value into Jill::fetch
...
}
int foom()
{
Hill top; // ERROR
Jill::Hill crest; // valid
}
Here, in main(), the name Jill::fetch is placed in the local namespace. It doesn't have local scope, so it doesn't override the global fetch. But the locally declared fetch hides both Jill::fetch and the global fetch. However, both of the last two fetch variables are available if you use the scope resolution operator. You might want to compare this example to the preceding one, which used a using-declaration.
One other point of note is that although a using-directive in a function treats the namespace names as being declared outside the function, it doesn't make those names available to other functions in the file. Hence in the preceding example, the foom() function can't use the unqualified Hill identifier.
Remember
|
|
Suppose a namespace and a declarative region both define the same name. If you attempt to use a using-declaration to bring the namespace name into the declarative region, the two names conflict, and you get an error. If you use a using-directive to bring the namespace name into the declarative region, the local version of the name hides the namespace version. |
Generally speaking, the using-declaration is safer to use because it shows exactly what names you are making available. And if the name conflicts with a local name, the compiler lets you know. The using-directive adds all names, even ones you might not need. If a local name conflicts, it overrides the namespace version, and you won't be warned. Also, the open nature of namespaces means that the complete list of names in a namespace might be spread over several locations, making it difficult to know exactly which names you are adding.
What about the approach used for this book's examples?
#include <iostream> using namespace std;
First, the iostream header file puts everything in the std namespace. Then, the next line exports everything in that namespace into the global namespace. Thus, this approach merely reproduces the pre-namespace era. The main rationale for this approach is expediency. It's easy to do, and if your system doesn't have namespaces, you can replace the preceding two lines with the original form:
#include <iostream.h>
However, the hope of namespace proponents is that you will be more selective and use either the resolution operator or the using-declaration. That is, don't use the following:
using namespace std; // avoid as too indiscriminate
Instead, do this:
int x; std::cin >> x; std::cout << x << std::endl;
Or else do this:
using std::cin; using std::cout; using std::endl; int x; cin >> x; cout << x << endl;
You can use nested namespaces, as described next, to create a namespace holding the using-declarations you commonly use.
You can nest namespace declarations:
namespace elements
{
namespace fire
{
int flame;
...
}
float water;
}
In this case, you refer to the flame variable as elements::fire::flame. Similarly, you can make the inner names available with this using-directive:
using namespace elements::fire;
Also, you can use using-directives and using-declarations inside namespaces:
namespace myth
{
using Jill::fetch;
using namespace elements;
using std::cout;
using std::cin;
}
Suppose you want to access Jill::fetch. Because Jill::fetch is now part of the myth namespace, where it can be called fetch, you can access it this way:
std::cin >> myth::fetch;
Of course, because it also is part of the Jill namespace, you still can call it Jill::fetch:
std::cout << Jill::fetch; // display value read into myth::fetch
Or you can do this, providing no local variables conflict:
using namespace myth; cin >> fetch; // really std::cin and Jill::fetch
Now consider applying a using-directive to the myth namespace. The using-directive is transitive. We say an operation op is transitive if A op B and B op C implies A op C. For example, the > operator is transitive. (That is, A bigger than B and B bigger than C implies A bigger than C.) In this context, the upshot is that the statement
using namespace myth;
results in the elements namespace being added via a using-directive also, so it's the same as the following:
using namespace myth; using namespace elements;
You can create an alias for a namespace. For example, suppose you have a namespace defined as follows:
namespace my_very_favorite_things { ... };
You can make mvft an alias for my_very_favorite_things with the following statement:
namespace mvft = my_very_favorite_things;
You can use this technique to simplify using nested namespaces:
namespace MEF = myth::elements::fire; using MEF::flame;
You can create an unnamed namespace by omitting the namespace name:
namespace // unnamed namespace
{
int ice;
int bandycoot;
}
This behaves as if it were followed by a using-directive; that is, the names declared in this namespace are in potential scope until the end of the declarative region containing the unnamed namespace. In this respect, they are like global variables. However, because the namespace has no name, you can't explicitly use a using-directive or using-declaration to make the names available elsewhere. In particular, you can't use names from an unnamed namespace in a file other than the one containing the namespace declaration. This provides an alternative to using static variables with internal linkage. Indeed, the C++ standard deprecates the use of the keyword static in namespaces and global scope. ("Deprecate" is a term the standard uses to indicate practices that currently are valid but most likely will be rendered invalid by future revisions of the standard.) Suppose, for example, you have this code:
static int counts; // static storage, internal linkage
int other();
int main()
{
}
int other()
{
}
The intent of the standard is that you should do this instead:
namespace
{
int counts; // static storage, internal linkage
}
int other();
int main()
{
}
int other()
{
}
Let's take a look at a multifile example that demonstrates some of the namespace features. The first file is a header file that contains some items normally found in header files梒onstants, structure definitions, and function prototypes. In this case the items are placed in two namespaces. The first namespace, called pers, contains a definition of a Person structure, plus prototypes for a function that fills a structure with a person's name and a function that displays the structure contents. The second namespace, called debts, defines a structure for storing the name of a person and the amount of money owed to that person. This structure uses the Person structure, so, the debts namespace has a using-directive to make the names in the pers available in the debts namespace. The debts namespace also contains some prototypes. Listing 9.9 shows this header file.
// namesp.h
namespace pers
{
const int LEN = 40;
struct Person
{
char fname[LEN];
char lname[LEN];
};
void getPerson(Person &);
void showPerson(const Person &);
}
namespace debts
{
using namespace pers;
struct Debt
{
Person name;
double amount;
};
void getDebt(Debt &);
void showDebt(const Debt &);
double sumDebts(const Debt ar[], int n);
}
The next file follows the usual pattern of having a source code file provide definitions for functions prototyped in a header file. The function names, being declared in a namespace, have namespace scope so the definitions need to be in the same namespace as the declarations. This is where the open nature of namespaces comes in handy. The original namespaces are brought in by including namesp.h (Listing 9.9). The file then adds the function definitions to the two namespaces, as shown in Listing 9.10.
// namesp.cpp -- namespaces
#include <iostream>
using namespace std;
#include "namesp.h"
namespace pers
{
void getPerson(Person & rp)
{
cout << "Enter first name: ";
cin >> rp.fname;
cout << "Enter last name: ";
cin >> rp.lname;
}
void showPerson(const Person & rp)
{
cout << rp.lname << ", " << rp.fname;
}
}
namespace debts
{
void getDebt(Debt & rd)
{
getPerson(rd.name);
cout << "Enter debt: ";
cin >> rd.amount;
}
void showDebt(const Debt & rd)
{
showPerson(rd.name);
cout <<": $" << rd.amount << endl;
}
double sumDebts(const Debt ar[], int n)
{
double total = 0;
for (int i = 0; i < n; i++)
total += ar[i].amount;
return total;
}
}
Finally, the third file of the program is a source code file using the structures and functions declared and defined in the namespaces. Listing 9.11 shows several methods of making the namespace identifiers available.
// usenmsp.cpp -- using namespaces
#include <iostream>
using namespace std;
#include "namesp.h"
void other(void);
void another(void);
int main(void)
{
using debts::Debt;
using debts::showDebt;
Debt golf = { {"Benny", "Goatsniff"}, 120.0};
showDebt(golf);
other();
another();
return 0;
}
void other(void)
{
using namespace debts;
Person dg = {"Doodles", "Glister"};
showPerson(dg);
cout << endl;
Debt zippy[3];
int i;
for (i = 0; i < 3; i++)
getDebt(zippy[i]);
for (i = 0; i < 3; i++)
showDebt(zippy[i]);
cout << "Total debt: $" << sumDebts(zippy, 3) << endl;
return;
}
void another(void)
{
using pers::Person;;
Person collector = { "Milo", "Rightshift" };
pers::showPerson(collector);
cout << endl;
}
First, main() using two using-declarations:
using debts::Debt; // makes the Debt structure definition available using debts::showDebt; // makes the showDebt function available
Note that using-declarations just use the name; for example, the second one doesn't describe the return type or function signature for showDebt; it just gives the name. (Thus, if a function were overloaded, a single using-declaration would import all the versions.) Also, although both Debt and showDebt() use the Person type, it isn't necessary to import any of the Person names because the debt namespace already has a using-directive including the pers namespace.
Next, the other() function takes the less desirable approach of importing the entire namespace with a using-directive:
using namespace debts; // make all debts and pers names available to other()
Because the using-directive in debts imports the pers namespace, the other() function can use the Person type and the showPerson() function.
Finally, the another() function uses a using-declaration and the scope resolution operator to access specific names:
using pers::Person;; pers::showPerson(collector);
Here is a sample run of the program:
Goatsniff, Benny: $120 Glister, Doodles Enter first name: Arabella Enter last name: Binx Enter debt: 100 Enter first name: Cleve Enter last name: Delaproux Enter debt: 120 Enter first name: Eddie Enter last name: Fiotox Enter debt: 200 Binx, Arabella: $100 Delaproux, Cleve: $120 Fiotox, Eddie: $200 Total debt: $420 Rightshift, Milo
As programmers become familiar with namespaces, common programming idioms will emerge. In particular, many hope that use of the global namespace will wither away and that class libraries will be designed by using the namespace mechanisms. Indeed, current C++ already calls for placing standard library functions in a namespace called std.
As mentioned before, changes in the header filenames reflect these changes. The older style header files, such as iostream.h, do not use namespaces, but the newer iostream header file should use the std namespace.
C++ encourages you to use multiple files in developing programs. An effective organizational strategy is to use a header file to define user types and provide function prototypes for functions to manipulate the user types. Use a separate source code file for the function definitions. Together, the header file and the source file define and implement the user-defined type and how it can be used. Then, main() and other functions using those functions can go into a third file.
C++'s storage schemes determine how long variables remain in memory (storage duration) and what parts of a program have access to them (scope and linkage). Automatic variables are those defined within a block, such as a function body or a block within the body. They exist and are known only while the program executes statements in the block that contains the definition. Automatic variables may be declared using the storage class specifiers auto or register or with no specifier at all, which is the same as using auto. The register specifier is a hint to the compiler that the variable is heavily used.
Static variables exist for the duration of the program. A variable defined outside of any function is known to all functions in the file following its definition (file scope) and is made available to other files in the program (external linkage). For another file to use such a variable, that file must declare it by using the extern keyword. A variable shared across files should have a defining declaration in one file (extern not used) and reference declarations in the other files (extern used). A variable defined outside any function but qualified with the keyword static has file scope but is not made available to other files (internal linkage). A variable defined inside a block but qualified with the keyword static is local to that block (local scope, no linkage) but retains its value for the duration of the program.
C++ functions, by default, have external storage class, so they can be shared across files. But functions qualified with the keyword static have internal linkage and are confined to the defining file.
Namespaces let you define named regions in which you can declare identifiers. The intent is to reduce name conflicts, particularly in large programs using code from several vendors. Identifiers in a namespace can be made available by using the scope resolution operator, by using a using-declaration, or by using a using-directive.
| 1: |
What storage scheme would you use for the following situations?
|
| 2: |
Discuss the differences between a using-declaration and a using-directive. |
| 3: |
Rewrite the following so that it doesn't use using-declarations or using-directives. #include <iostream>
using namespace std;
int main()
{
double x;
cout << "Enter value: ";
while (! (cin >> x) )
{
cout << "Bad input. Please enter a number: ";
cin.clear();
while (cin.get() != '\n')
continue;
}
cout << "Value = " << x << endl;
return 0;
}
|
| 4: |
Rewrite the following so that it uses using-declarations instead of the using-directive. #include <iostream>
using namespace std;
int main()
{
double x;
cout << "Enter value: ";
while (! (cin >> x) )
{
cout << "Bad input. Please enter a number: ";
cin.clear();
while (cin.get() != '\n')
continue;
}
cout << "Value = " << x << endl;
return 0;
}
|
| 5: | |
| 6: |
What will the following two-file program display? // file1.cpp
#include <iostream>
using namespace std;
void other();
void another();
int x = 10;
int y;
int main()
{
cout << x << endl;
{
int x = 4;
cout << x << endl;
cout << y << endl;
}
other();
another();
return 0;
}
void other()
{
int y = 1;
cout << "Other: " << x << "," << y << endl;
}
// file 2.cpp
#include <iostream>
using namespace std;
extern int x;
namespace
{
int y = -4;
}
void another()
{
cout << "another(): " << x << ", " << y << endl;
}
|
| 7: |
What will the following program display? #include <iostream>
using namespace std;
void other();
namespace n1
{
int x = 1;
}
namespace n2
{
int x = 2;
}
int main()
{
using namespace n1;
cout << x << endl;
{
int x = 4;
cout << x << ", " << n1::x << ", " << n2::x << endl;
}
using n2::x;
cout << x << endl;
other();
return 0;
}
void other()
{
using namespace n2;
cout << x << endl;
{
int x = 4;
cout << x << ", " << n1::x << ", " << n2::x << endl;
}
using n2::x;
cout << x << endl;
}
|
| 1: |
Here is a header file: // golf.h -- for pe8-3.cpp
const int Len = 40;
struct golf
{
char fullname[Len];
int handicap;
};
// non-interactive version:
// function sets golf structure to provided name, handicap
// using values passed as arguments to the function
void setgolf(golf & g, const char * name, int hc);
// interactive version:
// function solicits name and handicap from user
// and sets the members of g to the values entered
// returns 1 if name is entered, 0 if name is empty string
int setgolf(golf & g);
// function resets handicap to new value
void handicap(golf & g, int hc);
// function displays contents of golf structure
void showgolf(const golf & g);
Note that setgolf() is overloaded. Using the first version would look like this: golf ann; setgolf(ann, "Ann Birdfree", 24); The function call provides the information that's stored in the ann structure. Using the second version would look like this: golf andy; setgolf(andy); The function would prompt the user to enter the name and handicap and store them in the andy structure. This function could (but doesn't need to) use the first version internally. Put together a multifile program based on this header. One file, named golf.cpp, should provide suitable function definitions to match the prototypes in the header file. A second file should contain main() and demonstrate all the features of the prototyped functions. For example, a loop should solicit input for an array of golf structures and terminate when the array is full or the user enters an empty string for the golfer's name. The main() function should use only the prototyped functions to access the golf structures. |
| 2: |
Here is a namespace: namespace SALES
{
const int QUARTERS = 4;
struct Sales
{
double sales[QUARTERS];
double average;
double max;
double min;
};
// copies the lesser of 4 or n items from the array ar
// to the sales member of s and computes and stores the
// average, maximum, and minimum values of the entered items;
// remaining elements of sales, if any, set to 0
void setSales(Sales & s, const double ar[], int n);
// gathers sales for 4 quarters interactively, stores them
// in the sales member of s and computes and stores the
// average, maximum, and minumum values
void setSales(Sales & s);
// display all information in structure s
void showSales(const Sales & s);
}
Write a three-file program based on this namespace. The first file should be a header file containing the namespace. The second file should be a source code file extending the namespace to provide definitions for the three prototyped functions. The third file should declare two Sales objects. It should use the interactive version of setSales() to provide values for one structure and the non-interactive version of setSales() to provide values for the second structure. It should display the contents of both structures by using showSales(). |
| CONTENTS |


